
从整体上理解进程创建、可执行文件的加载和进程执行进程切换,重点理解分析fork、execve和进程切换
学号520
1.阅读理解task_struct数据结构
- 进程是程序的一个执行的实例;
- 进程是正在执行的程序;
- 进程是能分配处理器并由处理器执行的实体;
进程是分配系统资源(CPU时间,内存)的实体。为了管理进程,操作系统必须对每个进程所做的事情进行清楚的描述,为此,操作系统使用数据结构来代表处理不同的实体,这个数据结构就是通常所说的进程描述符或进程控制块(PCB)。在linux操作系统下这就是task_struct结构 ,所属的头文件#include <sched.h>每个进程都会被分配一个task_struct结构,它包含了这个进程的所有信息,在任何时候操作系统都能够跟踪这个结构的信息,宰割结构是linux内核汇总最重要的数据结构。
这个进程的主要信息:
1、与进程相关的唯一标识符,区别正在执行的进程和其他进程
2、状态:描述进程的状态,因为进程有阻塞、挂起、运行等好几个状态,所以都有个表示符来记录进程的执行状态。
3、优先级:如果有好几个进程正在执行,就涉及到进程的执行的先后顺序,这和进程的优先级这个标识符有关。
4、程序计数器:程序中即将被执行指令的下一条地址。
5、内存指针:程序代码和进程相关数据的指针。
6、上下文数据:进程执行时处理器的寄存器中的数据。
7、I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
8、记账信息:包括处理机的时间总和,记账号等等。
2.fork函数
在Linux系统中,除了系统启动之后的第一个进程由系统来创建,其余的进程都必须由已存在的进程来创建,新创建的进程叫做子进程,而创建子进程的进程叫做父进程。那个在系统启动及完成初始化之后,Linux自动创建的进程叫做根进程。根进程是Linux中所有进程的祖宗,其余进程都是根进程的子孙。具有同一个父进程的进程叫做兄弟进程。
linux中,父进程以分裂的方式来创建子进程,创建一个子进程的系统调用叫做fork(),fork函数创建进程的实质是子进程对父进程的复制:
int ForkProcess() { int pid; /* fork another process */ pid = fork(); if (pid<0) { /* error occurred */ printf("Fork Failed!"); //exit(-1); } else if (pid==0) { /* child process */ //execlp("/bin/ls","ls",NULL); printf("Child Process!,My PID is %d\n",pid); } else { /* parent process */ /* parent will wait for the child to complete*/ printf("Parent process!My PID is %d\n",pid);
//wait(NULL); printf("Child Complete!"); //exit(0); } return 0; }
3.编译链接的过程和ELF可执行文件格式
3.1 编译链接的过程

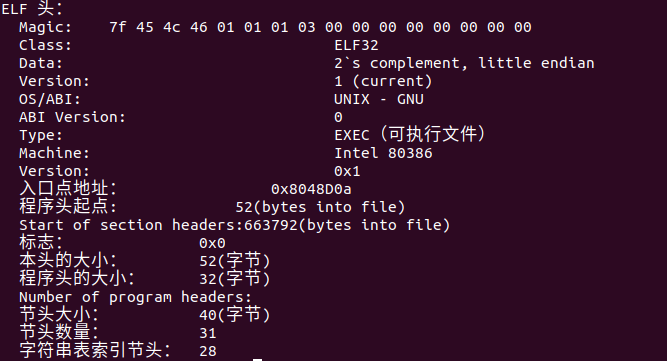
3.2 ELF可执行文件格式
在Linux下,可执行文件/动态库文件/目标文件(可重定向文件)都是同一种文件格式,我们把它称之为ELF文件格式。
虽然它们三个都是ELF文件格式但都各有不同:
- 可执行文件没有section header table 。
- 目标文件没有program header table。
- 动态库文件俩个 header table 都有,因为链接器在链接的时候需要section header table 来查看目标文件各个 section 的信息然后对各个目标文件进行链接,而加载器在加载可执行程序的时候需要program header table ,它需要根据这个表把相应的段加载到相应的虚拟内存(虚拟地址空间)中。
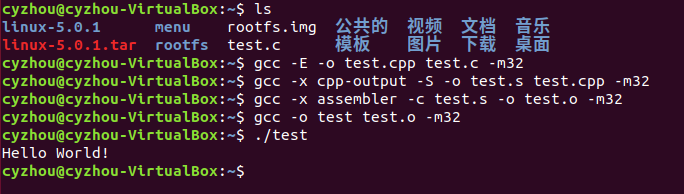
4.使用exec*库函数加载一个可执行文件
- 先编辑一个 .c
#include <stdio.h> #include <stdlib.h> int main() { printf("Hello World!\n"); return 0; }
- 生成预处理文件hello.cpp(预处理负责把include的文件包含进来及宏替换等工作)
- 编译成汇编代码hello.s
- 编译成目标代码,得到二进制文件hello.o
- 链接成可执行文件hello
- 运行一下./hello
5.使用gdb跟踪分析schedule()函数
打开终端中输入qemu-system-x86_64 –kernel linux-5.0.1/arch/x86/boot/bzImage –initrd rootfs.img –S –s
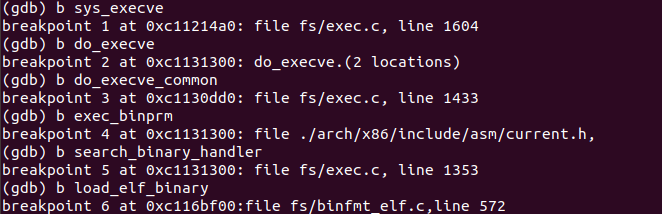
- 设置断点
- 中断
6.分析switch_to中的汇编代码
switch_to实现了进程之间的真正切换:
- 首先在当前进程prev的内核栈中保存esi,edi及ebp寄存器的内容。
- 然后将prev的内核堆栈指针ebp存入prev->thread.esp中。
- 把将要运行进程next的内核栈指针next->thread.esp置入esp寄存器中
- 将popl指令所在的地址保存在prev->thread.eip中,这个地址就是prev下一次被调度
- 通过jmp指令(而不是call指令)转入一个函数__switch_to()
- 恢复next上次被调离时推进堆栈的内容。从现在开始,next进程就成为当前进程而真正开始执行
#define switch_to(prev, next, last) do { /* * Context-switching clobbers(彻底击败) all registers, so we clobber * them explicitly, via unused output variables. * (EAX and EBP is not listed because EBP is saved/restored * explicitly for wchan access and EAX is the return value of * __switch_to()) */ unsigned long ebx, ecx, edx, esi, edi; asm volatile("pushfl\n\t" /* save flags */"pushl %%ebp\n\t" /* save EBP */"movl %%esp,%[prev_sp]\n\t" /* save ESP */"movl %[next_sp],%%esp\n\t" /* restore ESP */"movl $1f,%[prev_ip]\n\t" /* save EIP */"pushl %[next_ip]\n\t" /* restore EIP */"jmp __switch_to\n" /* regparm call */"1:\t""popl %%ebp\n\t" /* restore EBP */"popfl\n" /* restore flags *//* output parameters */ : [prev_sp] "=m" (prev->thread.sp), /*m表示把变量放入内存,即把[prev_sp]存储的变量放入内存,最后再写入prev->thread.sp*/ [prev_ip] "=m" (prev->thread.ip), "=a" (last), /*=表示输出,a表示把变量last放入ax,eax = last*//* clobbered output registers: */"=b" (ebx), "=c" (ecx), "=d" (edx), /*b 变量放入ebx,c表示放入ecx,d放入edx,S放入si,D放入edi*/"=S" (esi), "=D" (edi) /* input parameters: */ : [next_sp] "m" (next->thread.sp), /*next->thread.sp 放入内存中的[next_sp]*/ [next_ip] "m" (next->thread.ip), /* regparm parameters for __switch_to(): */ [prev] "a" (prev), /*eax = prev edx = next*/ [next] "d" (next) : /* reloaded segment registers */"memory"); } while (0)
