

❀third Summary❀
最前面:
完结撒花!想放假想放假想放假!各位美女bb还有彭于晏,不要恶意低分捏,我辛辛苦苦一个个字敲的哎,假期快来了,一切会好起来的。
我不包括前前言是3200字奥,够了的,真的,你可以自己复制粘贴看看,可能看起来短了点,没有题干和多余代码奥。
是真的懒得贴图了,没有放类图,因为老师上课讲过了,就不再放了,很多地方只贴了关键性的,而且没有复制代码过来。

(1)前言:
第一次实验
总计一道题(课程成绩统计程序-1)
有了上次实验的经验,这次上手难度就看起来简单了许多,设计学生成绩管理系统嘛毕竟,涉及的知识点就很多了,例如中英文的排序,这又穿插了(*【0-9】正则表达式的运用什么的),按照类图设计代码(会让代码的构造简单很多),类关系的设计与实现,正则表达式的使用,HashMap,HashSet等容器的使用,使用Iterator迭代器遍历容器元素,使用Collator进行中文字符的比较,类的抽象与子类的继承(继承可以通过 `extends` 关键字来实现。在继承的过程中,子类可以通过覆盖或重写方法来改变父类的行为),等等。
本次主要是考察类的设计与构造,以及平均分的计算,但由于要用到hashmap,hashset等容器类计算平均分时要使用迭代器进行迭代,代码量还是偏大。
难度上面讲,相较于上次,就简单了许多。
第二次实验总计四道题,
前两道考察hashmap的基本应用,
第三道(课程成绩统计程序-2)
是延续第一次实验的内容,知识点有实验类的设计与添加,实验考核方式类的设计与添加。,正则表达式下多次重复内容的处理与判读,使用迭代器累加实验课单次成绩并计算总成绩。
而第四题是考察implement的使用。接口可以通过 `interface` 关键字来定义,实现类可以通过 `implements` 关键字来实现接口。
本次统计程序实际上是第1次程序的迭代,添加实验课类即可,题量不高,代码量不高较易实现。
总而言之难度适中。
第三次实验
总计五道题,第一道考察容器-ArrayList-排序,第二道是学生成绩排序系统的继续延伸,知识点大概是继承关系修改为组合关系的使用,将平时成绩以及期末成绩的特定权重改为可修改式权重,正则表达式的处理与判断,使用迭代器进行数据的累加处理,权重的总和判断,不符合数据的输出,double类型数据和整形数据的比较处理
之后依次是jmu-Java-02基本语法-03-身份证排序,jmu-Java-04面向对象进阶-03-接口-自定义接口ArrayIntegerStack,jmu-Java-03面向对象基础-05-覆盖。
本次统计程序将前两次中的权重进行了可修化的迭代,题量总体来说并不大。
课程成绩统计程序-1
(2)设计与分析:
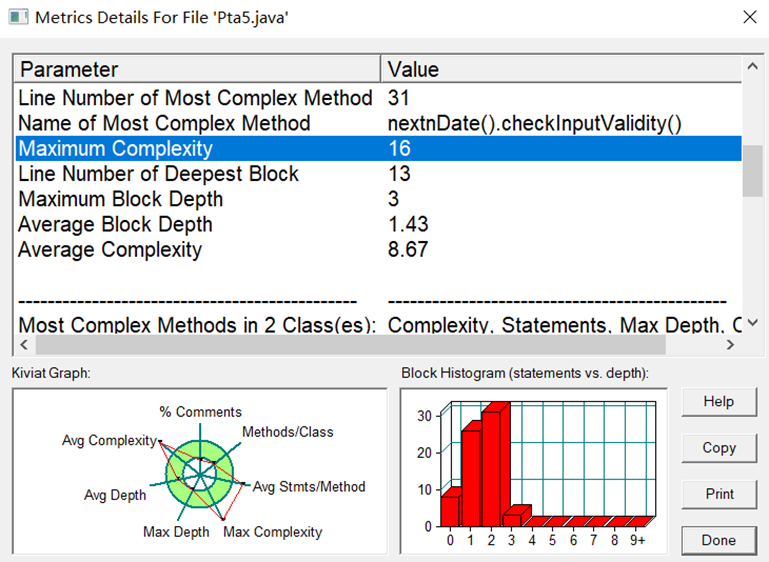
通过图片我们可以看出Statements为11,Branches为0.0,calls为0,Comments为0.0,class为1,Method为3,Lines为12。代码不简单,下次再编写代码应该重视圈复杂度这个问题,看看如何让代码更简洁一点

string类输出这是,然后再调用方法就好啦
(3)采坑心得:
为了实现课程的正确顺序的输出,我编写了treemap类型的按照字母排序的方式,但是经过不断的测试我 发现当输入的课程是有中文有英文的时候使用treemap没有办法将中英文混合的课程信息实现正确的排序,因为这其中混入了关于字典的排序,所以很有几个测试点没有办法过。
接口使用

后来找别人帮忙后,我使用了适配kecheng中的key课程名的String类型的list来二次存入课程名称,并使用Collection的sort排序方法配合着list和改写的排序方法进行中英文混合排序,通过for循环利用list适配hashmap课程中相同课程名的课程。实现排序输出。当然也是自然的就过啦。
还使用了接口,可以通过 `interface` ,实现类可以通过 `implements` 关键字来实现接口,让代码简洁了很多咱就是说
(4) 改进建议:

自己写的检索函数,其实后来发现hashmap会更简单一点
这次作业主要是发生了因为输入格式复杂,导致的错误,需要对每条输入进行解析和处理,容易出现格式错误和异常情况,需要同时考虑多种情况,如权重默认值这个下面例子有详细写,因为排版问题写在2里面了、考核方式、课程性质等,容易出现逻辑错误和漏洞,输出结果需要排序和处理异常情况,容易出现输出错误和不完整的结果然后导致报错,显示答案错误倒是没有非0返回。
课程成绩统计程序-2
(2)设计与分析:

通过图片我们可以看出Statements为28,Branches为3.6,calls为10,Comments为16.3,class为1,Method为10,Lines为43。
主方法上:我这次将主要的运行代码放在了新建的Play类中,所以我的main方法只有一个Play的运行方法。在Play中,我创建了String类型的s去接收输入的每一行信息。这样可以减少主函数里面的负担

一点代码震撼给到你,就是非常老式但是好用(特别好用)的格式检索,自己定义字符串然后匹配,看起来挺麻烦但是其实比正则还是简单一点。
(3)采坑心得:

一个自动生成的方法存根,写成方法会降低复杂度啦
相较于第一次。对于成绩类的结构进行了修改,由原来的继承结构变成了组合结构,将grade里的成绩变成ArrayList容器,可复用程度较高,相对于继承关系来说组合关系的关联程度也较低。然后这样改动的动作也没有小一点耶。
测试点如上,其实三次作业不见得有多难,就是精度问题次次都是跌跟头的地方,这里也是要进行强制转换。

(4)改进建议:
我要啥改进意见?100个人眼中100个哈利波特,大家都是好样的,当然圈复杂度也挺低,我的建议是没有建议。
正经,下次可以重视一些小地方,像精准度这个地方不大但是你不认真对待它就会让你扣很多分。
课程成绩统计程序-3
(2)设计与分析:
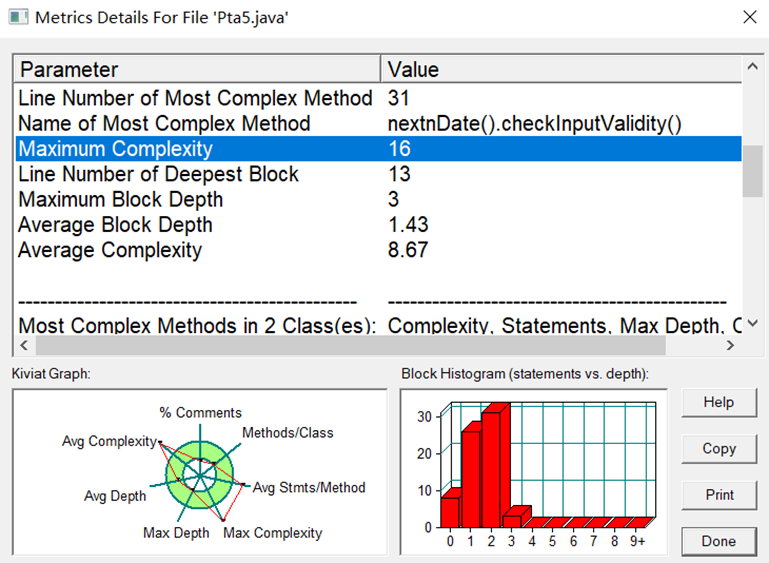
通过图片我们可以看出Statements为28,Branches为3.6,calls为10,Comments为16.3,class为1,Method为10,Lines为43。
代码还是不够简单
(3)采坑心得:

在parseinput类里进行权重总值的判断需要将权重总值为1,在parseinput类中解析单条数据时解析的先后顺序问题,也可能会造成相关的错误(会报错单条),例如在判断课程数据是否正确时应该先判断课程类型和考核方式,而不是根据考核方式再来判断课程类型。都是细节的问题哩
还是精度问题,真的很讨厌,可以使用强制类型转化转化为int进行比较或作将二者相减小于一特定精度值。我是在一开始没有注意到数字精度对数据结果的影响,在后面将double改成float,把1改成0.99-1.01之间,测试点就过了。

主函数相对简单,但是没有统一的用一个play,而是分开三个模块,这样子遵循自己的逻辑,在写代码的时候直接对应找过去就行了
(4)改进建议:
我在原先的基础上增加了新的属性,ArrayList<Float> FloatArrayList ,用来存入课程录入时适配于课程的权重,方便在后续计算总成绩进行计算。
(5)总结:
虽然我的编写依旧处于从慢到快的艰难过程,至少在结构编写上我有了更加清晰的思路去编写,在分析需求上和功能要求上比以前更加的准确和自然。
通过本类型的大作业深化了容器类的使用,以及正则表达式的使用,在完成问题中类设计的相关的概念逐渐完善,类之间的关系逐渐清晰,意识到本课程中类图设计的重要性,一个好的设计可以给后期写代码和修改代码带来巨大的方便。
自身对于java的学习的感觉呢,就像是黄金矿工,你不挖永远也不知道不幸和黄金哪个先到(我肯定是黄金啦),遇到石头呢,里面可能裹的就是黄金,要靠查阅解决将其刨开,打磨,收获新的知识,许多的知识都是需要自行发现的。如果你发先自己在某方面出碰了壁,在代码中想要实现某功能却不知所措,那就会去挖矿趴,去学习新的编程知识,总会有新发现的。
我学习了java语法中的List泛型和Hash类型的方法。我可以通过List泛型消除强制类型转换,同时可以消除源代码中的许多强制类型转换,这样可以使代码具有可读性,并减少出错的机会(因为不冗杂)。使用hashset方法检索,可以用来去除集合中的重复元素当然也可以判断元素是否存在,使用contains() 方法来判断集合中是否包含某个元素(也是检索)。HashSet还能用来维护能维护一个无序的集合, 具有较快的查找速度。它还可以进行元素的快速查找,因为它使用的是散列表,可以在常数时间内查找元素,还可以其次发现自己对于一些容器类的使用不是很熟练,这些类的特点以及相关的方法还不熟悉,今后在这方面还得深入学习。
除此之外,我深入学习了对判断语句非常有用的正则表达式。类似于string类的matches()方法,我都有拿正则表达式与这条匹配语句进行对比,再给出判断的结果返回boolean值。(真的很好用)。熟练的运用正则表达式,在规范格式方面上,匹配纯文本上的格式上真的是谁用谁知道,嘎嘎好用,我为正则表达式代言。
正如老师教导的,一个类所具有的功能不应该繁琐的。当我进一步的了解了关于JAVA中类,方法,属性之间的关系,在行文中运用三者时,有种打太极的感觉,和为大同,相互制约相互联系共同构成大同, 这次java实验让我在短期内学到了很多编程的知识和技能,同时也让我认识到了编程的乐趣和挑战。我相信,通过不断的实践和学习,我可以更好地掌握java编程的知识和技能,成为一名优秀的欧皇(代码掌控概率,概率决定欧非,我学会了代码我就是欧皇了)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器