


使用unittest的discover方法发现目录中子文件夹中的case
前言:开始用的时候都是把所有的test.py文件放在一个目录下,虽然对运行没什么影响,但是吧,总是不那么好看,且有时候文件名类似,要找好久,就想能不能再创建子文件夹进行分类一下,那又该如何使用discover方法去拿到所有用例呢?下面分享。
可能有人说可以用pytest框架,可以的,我可以用,但是我还想基于Unittest去解决试试。
第一种方法:
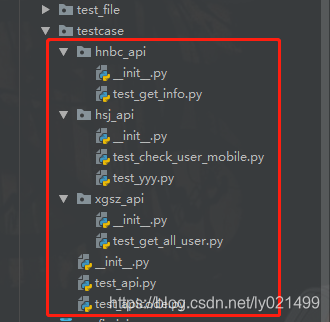
testcase目录
上代码:
注释写的很详细,其逻辑很简单,就是先用os.walk()方法拿到所有的py文件名称,再用判断去除非testcase.py文件,添加进case_list列表,再遍历case_list得到单个文件名,然后用discover中的pattern匹配方式去匹配相应文件名的文件得到单个testcase,就可以拿到所有的用例了。
特别注意一点:要想拿到所有的testcase必须在每个文件夹中有一个__init__.py文件引导,否则无法获取。
# pro_path是工程目录,构造了一个case_pth路径
case_path = os.path.join(pro_path, "testcase")
suit = unittest.TestSuite()
case_list = []
# 使用os.walk方法遍历得到所有文件名称filename的列表集合
for dirpath, dirname, filename in os.walk(case_path):
for file in filename:
# 判断文件以.py结尾且不以__开始,为去除__init.py文件和.pyx后缀的文件
if file.endswith(".py") and not file.startswith("__"):
# print(file)
case_list.append(file)
# 得到有效的用例文件列表后传值给discover方法的pattern匹配方式,可拿到所有testcase
# 此处注意,要想拿到所有的testcase必须在每个文件夹中有一个__init__.py文件引导,否则无法获取。
for case in case_list:
discover = unittest.defaultTestLoader.discover(start_dir=case_path, pattern=case)
suit.addTest(discover)
第二种方法:
用一个txt配置文件去记录所有的test.py文件,
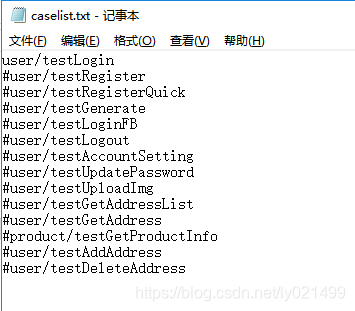
上代码:思路我就不讲解了,注释很清晰
caseListFile = os.path.join(pro_path, "caselist")
fb = open(caseListFile)
# 逐行读取文件名信息
for value in fb.readlines():
data = str(value)
# 过滤空格和#开头注释的文件名
if data != '' and not data.startswith("#"):
# 再添加进caseList列表中
self.caseList.append(data.replace("\n", ""))
fb.close()
test_suite = unittest.TestSuite()
# 遍历caseList列表
for case in self.caseList:
# 读取的文件名带了user路径,使用split进行分割,[-1]最后一个值
case_name = case.split("/")[-1]
print(case_name+".py")
# 使用discover方法去寻找以case_name开头的文件(txt中并未带.py后缀)
discover = unittest.defaultTestLoader.discover(self.caseFile, pattern=case_name + '.py', top_level_dir=None)
suite_module.append(discover)

