
《网络是怎样连接的》读书笔记二
昨天我们讲了在浏览器上输入的网址是如何传输给web服务器并得到响应消息显示在屏幕上,对HTTP这一过程不熟悉的同学可以去看我的上一篇笔记,今天只要讲DNS的工作过程以及如何委托协议栈发送消息
1.1 DNS工作工程
有一个机制,能通过域名查询IP地址或通过IP地址查询域名,这个机制就叫做DNS域名解析服务。
计算机有一个DNS客户端,这一部分简称DNS解析器,解析器实际上是一段程序,它包含在操作系统的socket库中,解析器的用法很简单,在编写浏览器等应用程序的时候,写上解析器的程序名称“gethostbyname”以及Web 服务器的域名“www.baidu.com”就可以了,这样就完成了对解析器的调用,调用成功后,解析器会向DNS服务器发送查询请求,然后服务器返回响应消息,消息里面包含了域名的IP地址,解析器会读出IP地址放到浏览器指定的内存中,接下来,浏览器向web服务器发送消息,只要从该内存取出IP地址,并将它与HTTP请求消息一起交给操作系统就行了
DNS解析的过程:调用解析器gethostbyname->生成发送给DNS服务器的查询消息->操作系统收到后向DNS服务器发送UDP消息->操作系统接受DNS的响应消息并返回给解析器 ->解析器从响应消息中取出IP地址放入内存,返回应用程序
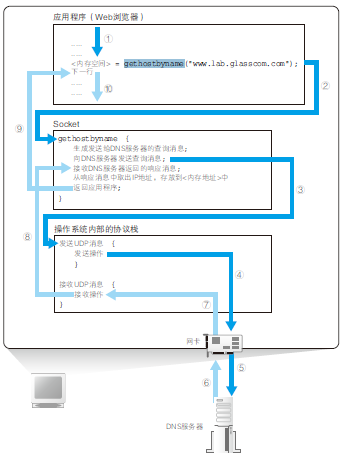
顺带一提,向DNS服务器发送请求消息也需要DNS服务器的IP地址,只不过这个IP地址是预先设好了,比如windows中设置为自动获取DNS服务器地址
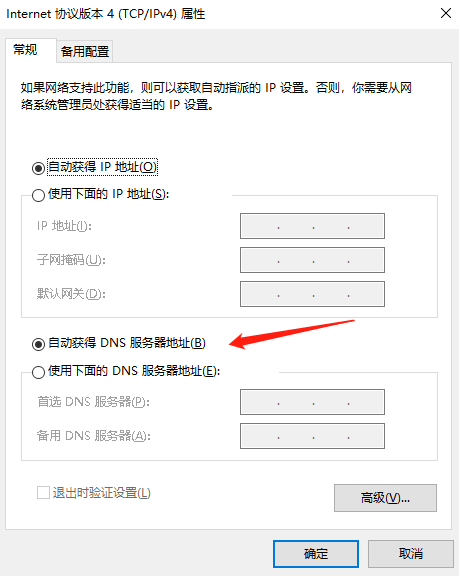
1.1.1 寻找相应的DNS 服务器并获取IP 地址
发送给DNS服务器的请求消息主要包含3个部分:域名、class、记录类型。
域名就是你在浏览器上输入的域名;class,识别网络的信息,默认为IN;记录类型,域名对应何种类型的记录,A表示IP地址,MX表示邮件服务器
例如,如果要查询 www.baidu.com 这个域名对应的IP 地址,客户端会向DNS 服务器发送包含以下信息的查询消息。
(a) 域名 = www.baidu.com
(b) Class = IN
(c) 记录类型 = A
有的同学可能要问了,是不是所有的域名信息都保存在一台DNS服务器上呢?
答案是否定的,将全世界所有服务器的信息存放在一台DNS服务器上是不可能的,要将信息分布保存在多台DNS 服务器中,这些DNS 服务器相互接力配合,从而查找出要查询的信息
那么,如何找到我们要访问的WEB服务器的信息归哪台DNS服务器管呢?
首先,DNS 服务器中的所有信息都是按照域名以分层次的结构来保存的,比如www.baidu.com,这里的句点代表了不同层次的界限,最右边层级最高
将负责管理下级域的DNS 服务器的IP 地址注册到它们的上级DNS 服务器中,然后上级DNS 服务器的IP 地址再注册到更上一级的DNS 服务器中,比如负责管理lwww.baidu.com这个域的DNS 服务器的IP 地址需要注册到baidu.com 域的DNS服务器中,而baidu.com 域的DNS 服务器的IP 地址又需要注册到com域的DNS 服务器中。这样,我们就可以通过上级DNS 服务器查询出下级DNS 服务器的IP 地址,也就可以向下级DNS 服务器发送查询请求了。
接下来就是查询的过程了:客户端首先访问最近的一台DNS服务器(在上面的TCP/IP设置为自动获取DNS服务器地址),然后服务器把查询消息发送给根域(DNS最高级的域),根域判断这个域名属于com域,因此根域DNS服务器返回它所管理的com域的DNS服务器的IP地址,com域DNS服务器判断这个域名属于下一级baidu域,返回它所管理的baidu域的DNS服务器的IP地址,大体意思就是说,我不知道你这个域名的IP地址,但我给你另一个DNS服务器的IP地址,它可能知道。。接下来baidu域判断这个域名属于下一级www域,再返回www域DNS服务器的IP地址,到了www域后,就找到了www.baidu.com这个域名的IP地址了,将这个IP地址发送回客户端,也就完成了查询过程。
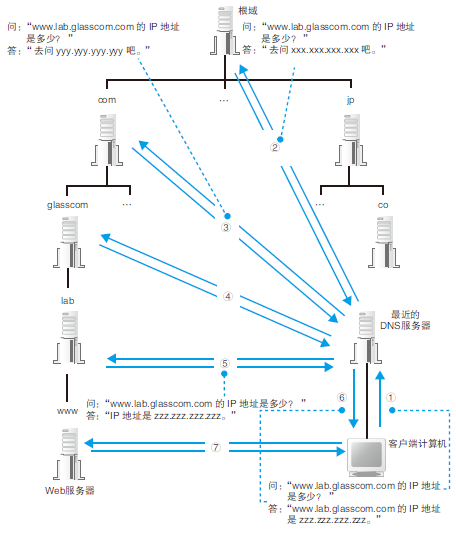
1.1.2 通过缓存加快DNS 服务器的响应
上面讲的DNS服务的基本原理,与真实互联网中的工作方式还是有一些区别的。在真实的互联网中,一台DNS 服务器可以管理多个域的信息,因此并不是像图1.16 这样每个域都有一台自己的DNS 服务器。图中,每一个域旁
边都写着一台DNS 服务器,但现实中上级域和下级域有可能共享同一DNS 服务器。在这种情况下,访问上级DNS 服务器时就可以向下跳过一级DNS 服务器,直接返回再下一级DNS 服务器的相关信息。
此外,有时候并不需要从最上级的根域开始查找,因为DNS 服务器有一个缓存A 功能,可以记住之前查询过的域名。如果要查询的域名和相关信息已经在缓存中,那么就可以直接返回响应,接下来的查询可以从缓存的位置开
始向下进行。相比每次都从根域找起来说,缓存可以减少查询所需的时间。
2、委托协议栈发送消息
2.1 数据收发操作概览和向DNS 服务器查询IP 地址的操作一样,这里也需要使用Socket 库中的程序组件。不过,查询IP 地址只需要调用一个程序组件就可以了,而这里需要按照指定的顺序调用多个程序组件,这个过程有点复杂。发送数据是一系列操作相结合来实现的,如果不能理解这个操作的全貌,就无法理解其中每个操作的意义。因此,我们先来介绍一下收发数据操作的整体思路。
简单来说,收发数据的两台计算机之间连接了一条数据通道,数据沿着这条通道流动,最终到达目的地。我们可以把数据通道想象成一条管道,将数据从一端送入管道,数据就会到达管道的另一端然后被取出。数据可以从任何一端被送入管道,数据的流动是双向的。不过,这并不是说现实中真的有这么一条管道,只是为了帮助大家理解数据收发操作的全貌。
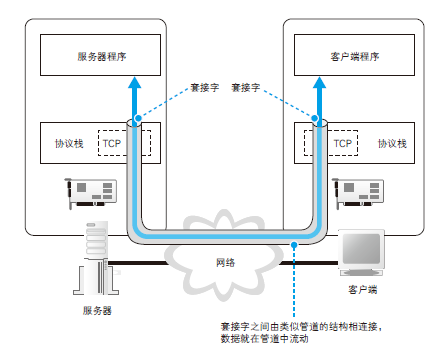
在进行收发数据操作之前,双方需要先建立起这条管道才行。建立管道的关键在于管道两端的数据出入口,这些出入口称为套接字。我们需要先创建套接字,然后再将套接字连接起来形成管道。实际的过程是下面这样的。首先,服务器一方先创建套接字,然后等待客户端向该套接字连接管道A。当服务器进入等待状态时,客户端就可以连接管道了。具体来说,客户端也会先创建一个套接字,然后从该套接字延伸出管道,最后管道连接到服务器端的套接字上。当双方的套接字连接起来之后,通信准备就完成了。接下来,就像我们刚刚讲过的一样,只要将数据送入套接字就可以收发数据了。我们再来看一看收发数据操作结束时的情形。当数据全部发送完毕之后,连接的管道将会被断开。管道在连接时是由客户端发起的,但在断开时可以由客户端或服务器任意一方发起A。其中一方断开后,另一方也会随之断开,当管道断开后,套接字也会被删除。到此为止,通信操作就结束了。
综上所述,收发数据的操作分为若干个阶段,可以大致总结为以下4 个。
(1)创建套接字(创建套接字阶段)
(2)将管道连接到服务器端的套接字上(连接阶段)
(3)收发数据(通信阶段)
(4)断开管道并删除套接字(断开阶段)
2.2 连接阶段
接下来,我们需要委托协议栈将客户端创建的套接字与服务器那边的套接字连接起来。应用程序通过调用Socket 库中的名为connect 的程序组件来完成这一操作。这里的要点是当调用connect 时,需要指定描述符、服务器IP 地址和端口号这3 个参数。
第1 个参数,即描述符,就是在创建套接字的时候由协议栈返回的那个描述符。connect 会将应用程序指定的描述符告知协议栈,然后协议栈根据这个描述符来判断到底使用哪一个套接字去和服务器端的套接字进行连接,并执行连接的操作A。
第2 个参数,即服务器IP 地址,就是通过DNS 服务器查询得到的我们要访问的服务器的IP 地址。在DNS 服务器的部分已经讲过,在进行数据收发操作时,双方必须知道对方的IP 地址并告知协议栈。这个参数就是那个IP 地址了。
第3 个参数,即端口号,这个需要稍微解释一下。可能大家会觉得,IP 地址就像电话号码,只要知道了电话号码不就可以联系到对方了吗?其实,网络通信和电话还是有区别的,我们先来看一看IP 地址到底能用来干什么。IP 地址是为了区分网络中的各个计算机而分配的数值B。因此,只要知道了IP 地址,我们就可以识别出网络上的某台计算机。但是,连接操作的对象是某个具体的套接字,因此必须要识别到具体的套接字才行,而仅凭IP 地址是无法做到这一点的。我们打电话的时候,也需要通过“请帮我找一下某某某”这样的方式来找到具体的某个联系人,而端口号就是这样一种方式。当同时指定IP 地址和端口号时,就可以明确识别出某台具体的计算机上的某个具体的套接字。
好了,今天主要复习了DNS的工作流程还有委托协议栈发送消息,这个委托协议栈发送消息其实就相当于linux下tcp的创建过程,明天继续做笔记
转载请注明作者、出处,谢谢
