数据采集作业四
作业①
1)实验要求
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
- 候选网站:http://www.dangdang.com/
- 关键词:学生自由选择
- 输出信息: MySQL数据库存储和输出格式如下

2)思路分析
分析网页,寻找对应的信息


就可以写代码啦
i_list = selector.xpath("//*[@id='component_59']/li") #先以ul的id值定位到相应的ul,再定位下面的li标签即可 for li in li_list: title = li.xpath("./a[position()=1]/@title").extract_first() price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first() author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first() date = li.xpath("./p[@class='search_book_author']/span[position()= last()-1]/text()").extract_first() publisher = li.xpath( "./p[@class='search_book_author']/span [position()=last()]/a/@title").extract_first() #有的detail值为空 detail = li.xpath("./p[@class='detail']/text()").extract_first()
这就是BooksspiderSpider最主要的内容,同时要考虑控制得到带有关键词的url
def start_requests(self): url = BooksspiderSpider.source_url + "?key=" + BooksspiderSpider.key #拼接得到带有搜索关键词的url yield scrapy.Request(url = url , callback=self.parse) #回调请求,用的都是同一个parse方法
items设置元素变量:
class BooksproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() author = scrapy.Field() date = scrapy.Field() publisher = scrapy.Field() detail = scrapy.Field() price = scrapy.Field() pass
pipelines则要考虑连接MySQL:
连接数据库
def open_spider(self, spider): print("opened") try: self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="yy0426cc..", db="myDB", charset='utf8') self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.opened = True self.count = 1 except Exception as err: print(err) self.opened = False
关闭数据库
def close_spider(self, spider): if self.opened: self.con.commit() self.con.close() self.opened = False print("closed") print("总共爬取", self.count, "本书籍")
setting中设置请求头:
BOT_NAME = 'bookspro' SPIDER_MODULES = ['bookspro.spiders'] NEWSPIDER_MODULE = 'bookspro.spiders' LOG_LEVEL = 'ERROR' USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44' #UA伪装 ROBOTSTXT_OBEY = False ITEM_PIPELINES = { 'bookspro.pipelines.BooksproPipeline': 300, }
输出结果
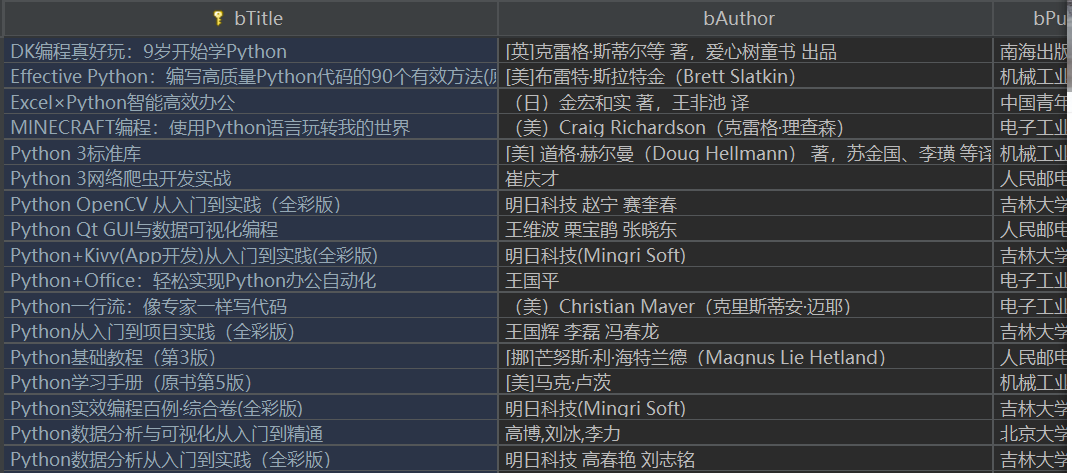
3)心得体会
这次实验主要是复现,代码方面没有什么问题,但是在安装配置MySQL以及实现可视化方面用了较多的时间,同时第一次使用mysql还有点不太熟练,还要多加练习。
作业②
1)实验要求
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
- 候选网站:招商银行网:http://fx.cmbchina.com/hq/
- 输出信息:MYSQL数据库存储和输出格式
| id | Currency | TSP | CSP | TBP | CBP | Time |
| 1 | 港币 | 86.60 | ... | |||
| ... |
2)思路分析
分析网页,获得所需要的信息
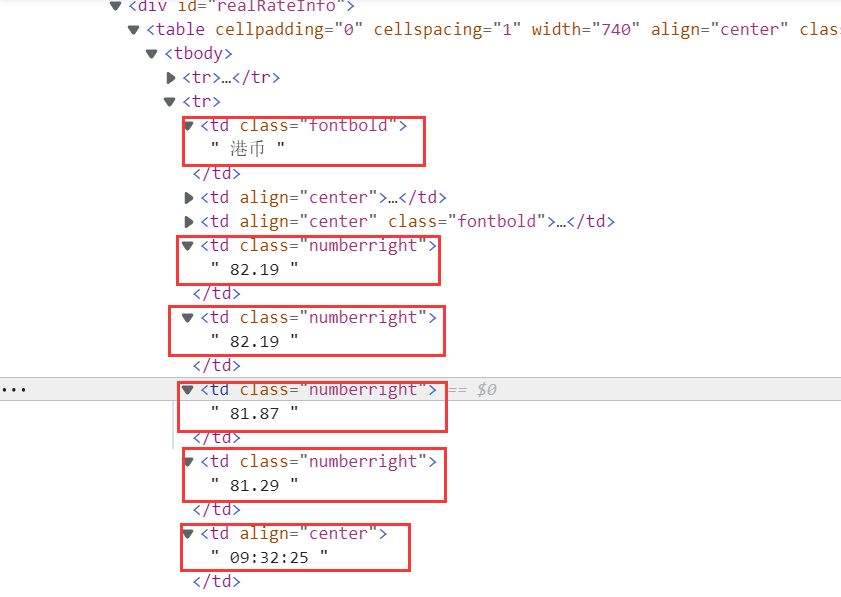
对应的代码
data = selector.xpath("//div[@id='realRateInfo']/table/tr") for tr in data[1:]: currency = tr.xpath("./td[@class='fontbold'][position()=1]/text()").extract_first() tsp = tr.xpath("./td[@class='numberright'][position()=1]/text()").extract_first() csp = tr.xpath("./td[@class='numberright'][position()=2]/text()").extract_first() tbp = tr.xpath("./td[@class='numberright'][position()=3]/text()").extract_first() cbp = tr.xpath("./td[@class='numberright'][position()=4]/text()").extract_first() time = tr.xpath("./td[@align='center'][position()=3]/text()").extract_first()
items设置元素变量:
class CurrencyItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() Currency = scrapy.Field() TSP = scrapy.Field() CSP = scrapy.Field() TBP = scrapy.Field() CBP = scrapy.Field() Time = scrapy.Field()
pipelines同样要考虑连接MySQL:
连接数据库,建立对应的表:
def open_spider(self, spider): print("opened") try: self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="yy0426cc..", db="mydb", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("DROP TABLE IF EXISTS bank") self.cursor.execute("CREATE TABLE IF NOT EXISTS bank(" "id int PRIMARY KEY," "Currency VARCHAR(32)," "TSP VARCHAR(32)," "CSP VARCHAR(32)," "TBP VARCHAR(32)," "CBP VARCHAR(32)," "TIME VARCHAR(32))") self.opened = True self.count = 0 except Exception as err: print(err) self.opened = False
关闭数据库:
def close_spider(self, spider): if self.opened: self.con.commit() self.con.close() self.opened = False print("closed") print("总共爬取", self.count, "条信息")
settings设置请求头:
BOT_NAME = 'currency' SPIDER_MODULES = ['currency.spiders'] NEWSPIDER_MODULE = 'currency.spiders' USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44' #UA伪装 ITEM_PIPELINES = { 'currency.pipelines.CurrencyPipeline':300, }
输出结果

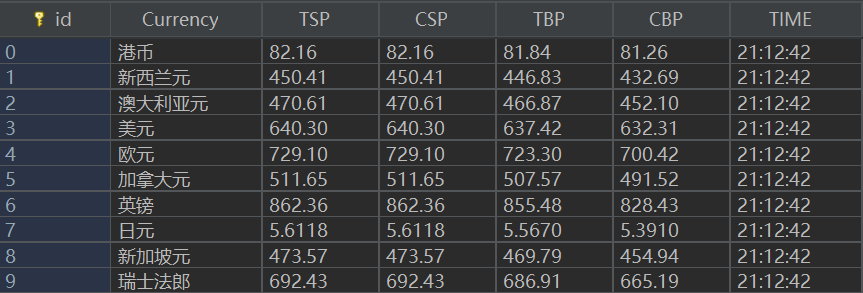
3)心得体会
做第二个实验的实验参照了第一个的写法,相比之下对MySQL的使用有了初步的认识,明白了具体的使用。这次寻找对应节点信息也比较简单,但还需要多加练习
作业③
1)实验要求
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
- 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
- 输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头
| num | name | new_price | new_change | new_change_num | money |
| 688093 | N世华 | ... | |||
| ... |
2)思路分析
分析网页,寻找所需要的信息
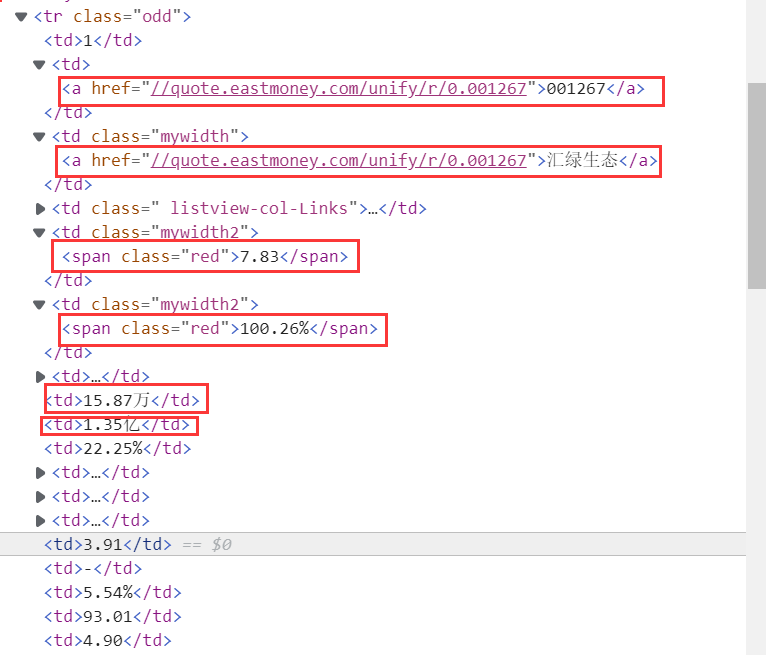
编写对应代码,并插入数据库
locator = (By.XPATH, "//table[@id='table_wrapper-table']/tbody/tr/td") # 等表格加载出来再爬取网站信息 WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator)) trs = driver.find_elements_by_xpath("//table[@class='table_wrapper-table']/tbody/tr") count=0 # 每个页面爬取4个数据 for tds in trs: count+=1 if(count==4): break td = tds.find_elements_by_xpath("./td") # 序号,名称,最新价格,涨跌额,涨跌幅,成交量 # item["f12"], item["f14"], item["f2"], item["f3"], item["f4"], item["f5"] num = td[1].text name = td[2].text new_price = td[4].text new_change_num = td[5].text new_change = td[6].text money = td[7].text print(num,name) insertIntoDB(num,name,new_price,new_change,new_change_num,money)
控制翻页
try: driver.find_element_by_xpath("/html/body/div[@class='page-wrapper']/div[@id='page-body']/div[@id='body-main']/div[@id='table_wrapper']/div[@class='listview full']/div[@class='dataTables_wrapper']/div[@id='main-table_paginate']/a[@class='next paginate_button disabled']") except: nextPage = driver.find_element_by_xpath("/html/body/div[@class='page-wrapper']/div[@id='page-body']/div[@id='body-main']/div[@id='table_wrapper']/div[@class='listview full']/div[@class='dataTables_wrapper']/div[@id='main-table_paginate']/a[@class='next paginate_button']") # 爬取三页就好 if(sum<=2): nextPage.click() time.sleep(2) spider() else: print("爬取下一个股票",id) if(id<=8): nextstock = driver.find_elements_by_xpath( "//div[@class='page-wrapper']/div[@id='page-body']/div[@id='body-main']/div[@id='tab']/ul[@class='tab-list clearfix']/li") driver.execute_script("window.scrollTo(0,0);") nextstock[id].click() time.sleep(2) # 跳到最新打开的页面 driver.switch_to.window(driver.window_handles[-1]) time.sleep(2) spider()
与数据库建立连接
connect = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="yy0426cc..", db="mydb", charset="utf8") # 中间三个依次是数据库连接名、数据库密码、数据库名称 cursor = connect.cursor() createTable() spider()
关闭数据库
connect.close()
driver.close()
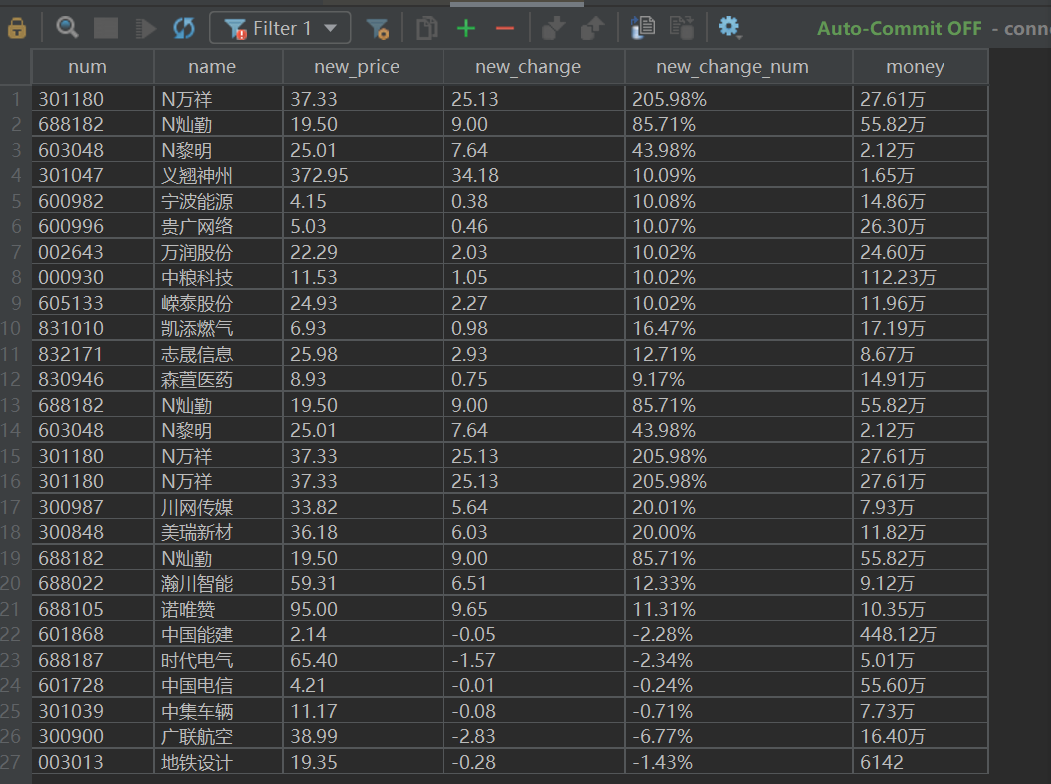
输出结果

3)心得体会
这个实验是使用Selenium框架,感觉还不太会。在选择爬取的信息时就先选了最简单的几个,但是MySQL的使用更熟练了,不过Selenium能跳出网页还是很神奇,这就是爬虫的魅力叭。
代码地址:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号