

数据采集作业三
作业①
1)实验要求
- 指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.we ather.com.cn)。分别使用单线程和多线程的方式爬取。
- 输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
2)思路分析
分析网页,发现对应翻页信息

获取href的正则表达式为:
href = re.findall(r'<a href="(.+?)"', r)
再分析网页,找到需要获取的图片信息 发现存在img的src中
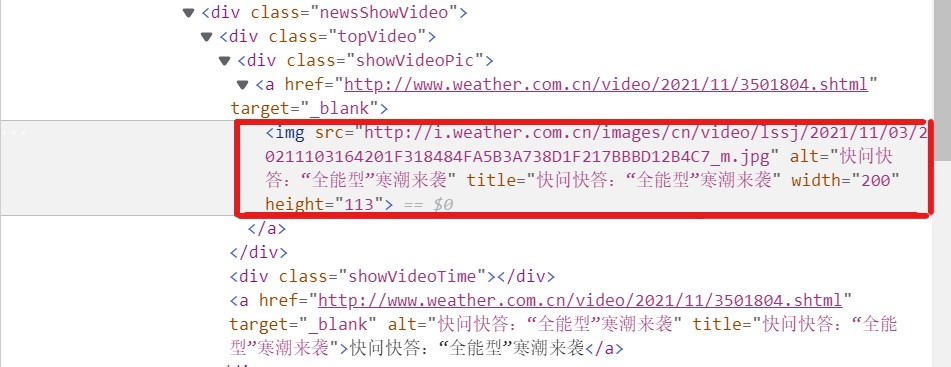
然后就可以开始写代码啦
单线程:
获取网页信息,为了翻页做准备
def getHTML(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
翻页处理模块
for i in range(len(href)): rsp = href[i].strip() imageSpider(rsp) #爬取中途会出现报错 if rsp == 'javascript:void(0)': continue
下载图片模块
def download(url): global count try: count += 1 #学号尾号是131 if count<=131: if (url[len(url) - 4] == "."): ext = url[len(url) - 4:] else: ext = "" req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() # 将下载的图像文件写入本地文件夹 fobj = open("D:\\数据采集\\images\\" + str(count) + ext, "wb") fobj.write(data) fobj.close() print(url) print("download " + str(count) + ext) except Exception as err: print(err)
输出结果(顺序输出)
多线程:
与单线程想比,需要添加的内容
if url not in urls: print(url) count = count + 1 # 创建线程 T = threading.Thread(target=download, args=(url, count)) T.setDaemon(False) T.start() threads.append(T)
for i in range(len(href)): rsp = href[i].strip() imageSpider(rsp) #多线程 for t in threads: t.join() if rsp == 'javascript:void(0)': continue
输出结果(非顺序)

3)心得体会
单线程和多线程的练习之前也有做过,这次主要是翻页处理比较难,找到href以后一开始也没想到怎么处理。然后最开始翻页处理的时候,图片下载到104张就停止了,但是尝试输出rsp以后,后面的rsp可以输出,中间会跳出javascript:void(0)无法识别的错误,去掉以后就正常了。
作业②
1)实验要求
- 使用scrapy框架复现作业①
- 输出信息:同作业①
2)思路分析
网页分析之前以后做过了,改写用scrapy框架就好了
items:
class WeatherdemoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() img = scrapy.Field()
myweatherSpider:
class MYweatherSpider(scrapy.Spider): name = 'weather' allowed_domains = ['weather.com'] url='http://www.weather.com.cn/' r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding href = re.findall(r'<a href="(.+?)"', str(r)) def start_requests(self): yield scrapy.Request(url=MYweatherSpider.url, callback=self.parse) def parse(self, response): count=0 selector = Selector(text=response.text) srclist = selector.xpath("//img/@src").extract() for src in srclist: if count <131: item = WeatherdemoItem() print("src", src) item['img'] = src count + 1 yield item if count <131: yield scrapy.Request(url=MYweatherSpider.href, callback=self.parse)
pipelines:
class WeatherdemoPipeline(ImagesPipeline): def get_media_requests(self, item, info): yield scrapy.Request(item['img']) def file_path(self, request, response=None, info=None): imgname = request.url.split("/")[-1] return imgname def item_completed(self, results, item, info): return item #返回给下一个即将被执行的管道类
settings:
USER_AGENT ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40' #增加访问header,加个降低被拒绝的保险 ITEM_PIPELINES ={ 'weatherdemo.pipelines.WeatherdemoPipeline':1 } IMAGES_STORE = 'D:/数据采集/images'#图片保存地址 BOT_NAME = 'weatherdemo' SPIDER_MODULES = ['weatherdemo.spiders'] NEWSPIDER_MODULE = 'weatherdemo.spiders' LOG_LEVEL='ERROR'
run:
from scrapy import cmdline cmdline.execute("scrapy crawl weather ".split())
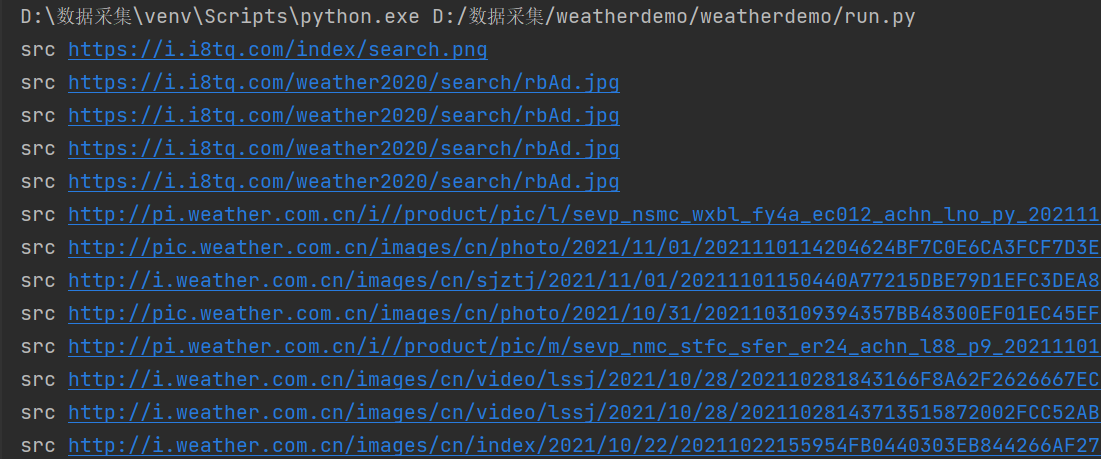
输出结果
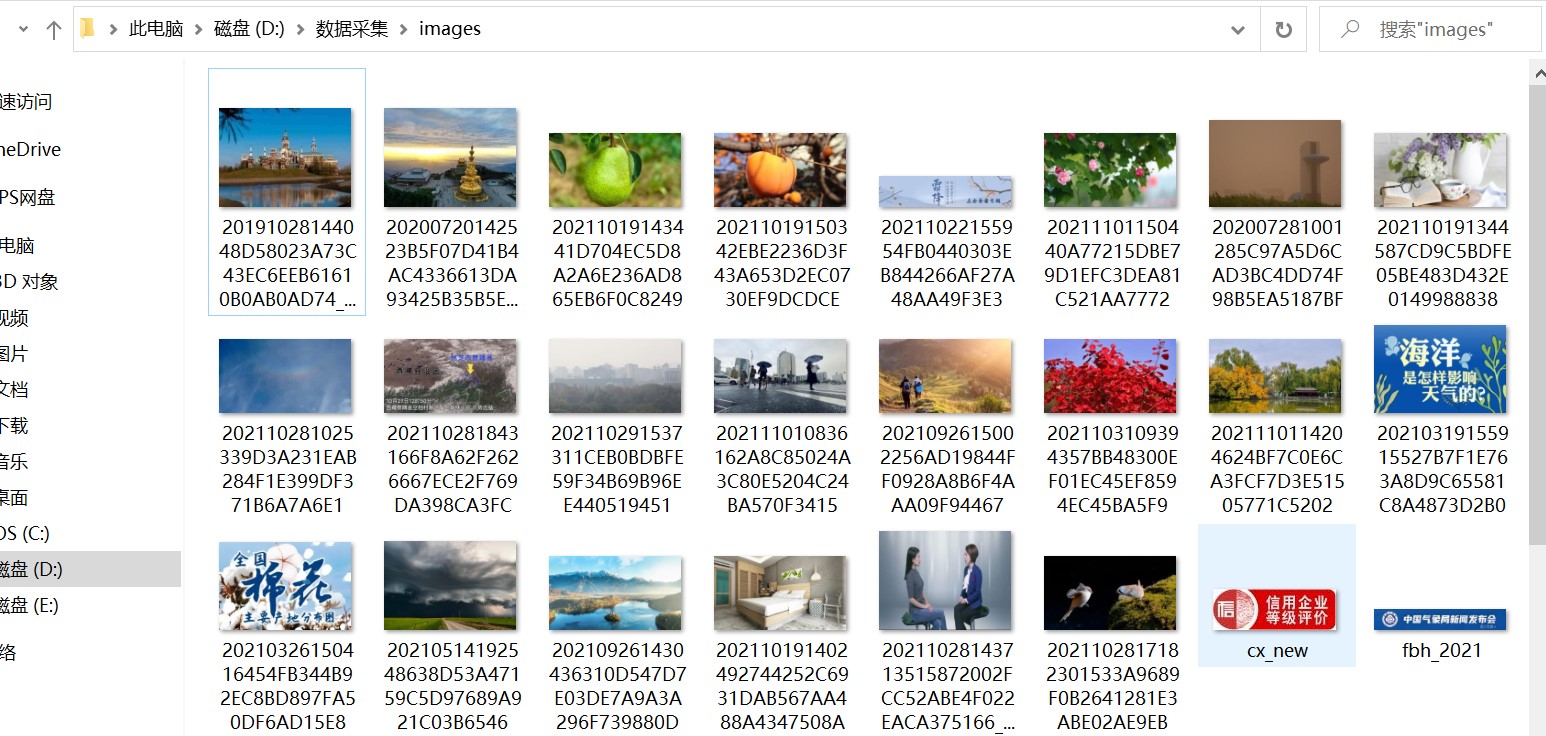
3)心得体会
最开始写scrapy框架的时候有点懵,不知道哪个py文件写哪个内容,经常跑出来是一片红色,后来发先是item[img]那里写错了,总的来说也让我对scrapy框架更加熟悉了。
作业③
1)实验要求
- 要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
- 候选网站: https://movie.douban.com/top250
- 输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2 | ... |
2)思路分析
分析网页获取信息
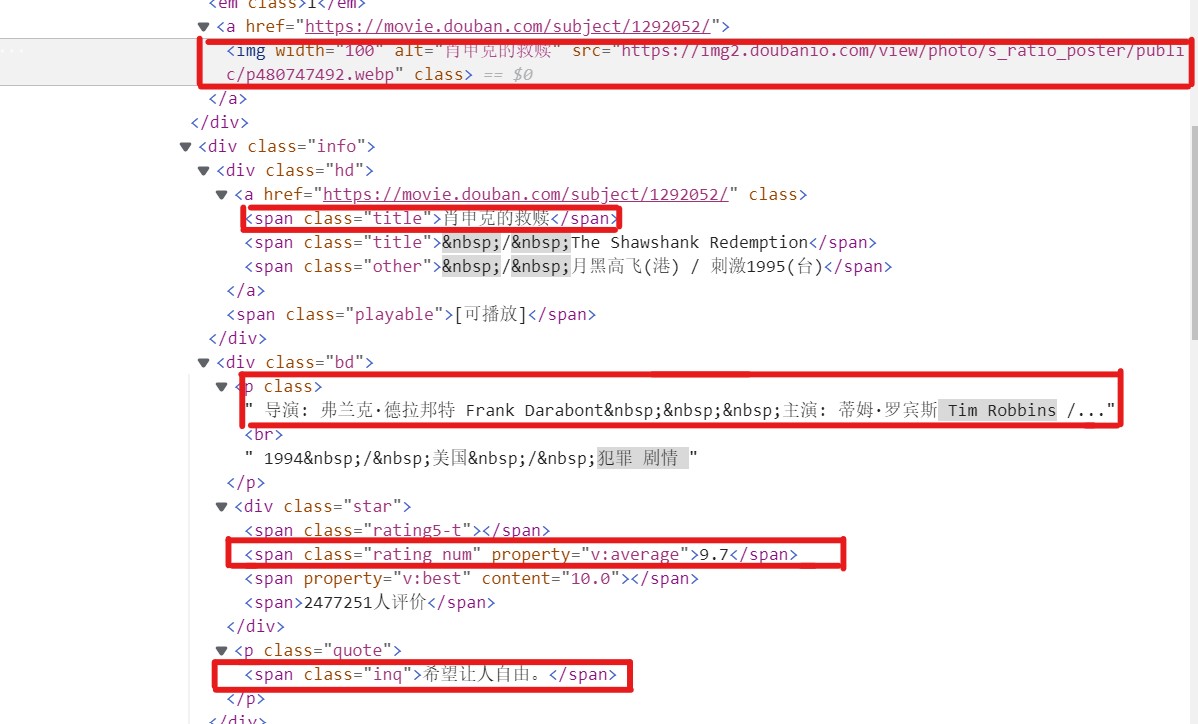
发现导演和演员连在了一起,要想办法分开,编写的xpath代码如下
item['raking'] = li.xpath(".//em/text()").extract_first() # 序号 item['name']=li.xpath(".//div[@class='info']//a/span[@class='title']/text()").extract_first() # 电影名称 act = li.xpath(".//div[@class='bd']/p/text()").extract_first() # 导演和演员 acts = act.split("主演:") try: item['director'] = re.search(':.*:', acts).group()[1:-3] except: item['director'] = "奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano " item['actor'] = acts[0].split(':')[1] item['content']=li.xpath(".//div[@class='bd']/p[@class='quote']/span/text()").extract_first() # 简介 item['number']=li.xpath(".//div[@class='star']/span[@class='rating_num']/text()").extract_first() # 电影评分 item['img']= li.xpath(".//div/a/img/@src").extract_first() # 电影封面
翻页规律
https://movie.douban.com/top250
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
start_url = 'https://movie.douban.com/top250' url = MymovieSpider.start_url + "?start=" + str(i *25)
items:
class MoviedemoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() raking = scrapy.Field() # 排名 name = scrapy.Field() # 电影名称 director = scrapy.Field() # 导演 actor = scrapy.Field() # 演员 content = scrapy.Field() # 简介 number = scrapy.Field() # 评分 img = scrapy.Field() # 封面
pipelines:
数据库(之前实验有写过,算是复习)
class movieDB: # 打开数据库的方法 def openDB(self): self.con = sqlite3.connect("movie.db") self.cursor = self.con.cursor() try: self.cursor.execute( "create table movies(raking varchar(5),name varchar(16),director varchar(20),actor varchar(20),content varchar(20),score varchar(5),picture varchar(16) )" ) except: self.cursor.execute("delete from movies") def closeDB(self): self.con.commit() self.con.close() # 加入元组 def insert(self, raking, name, director, actor, content, score, picture): try: self.cursor.execute("insert into movies (raking, name, director, actor, content, score, picture) " "values (?,?,?,?,?,?,?)", (raking, name, director, actor, content, score, picture)) # 插入表 except Exception as err: print(err)
插入数据并下载图片
def process_item(self, item, spider): self.db.insert(item["raking"], item["name"], item["director"], item["actor"], item["content"], item["number"], item["img"]) urllib.request.urlretrieve(item["img"], 'D:\数据采集\images\\' + str(item["raking"]) + '.jpg') try: print(item["raking"]) print(item["name"]) print(item["director"]) print(item["actor"]) print(item["content"]) print(item["number"]) print(item["img"]) except Exception as err: print(err) return item
settings:
ITEM_PIPELINES = { 'moviedemo.pipelines.MoviedemoPipeline': 300, }
run:
from scrapy import cmdline cmdline.execute("scrapy crawl mySpider".split())
输出内容
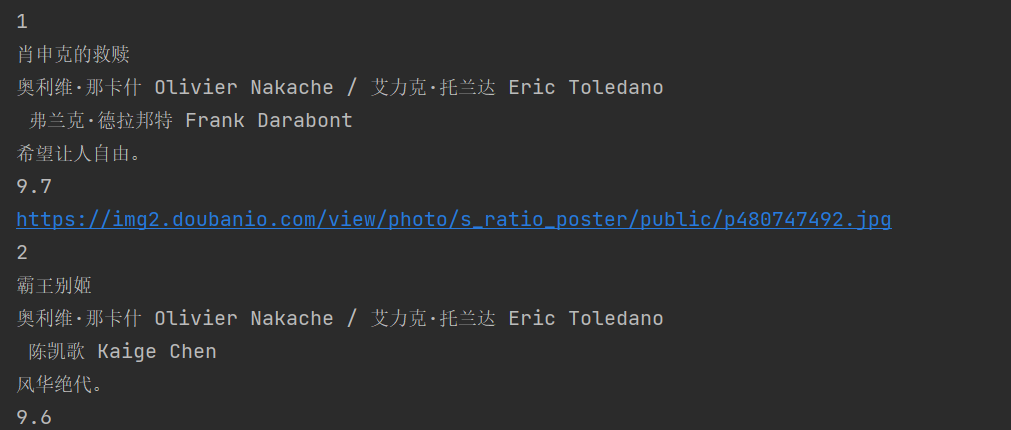
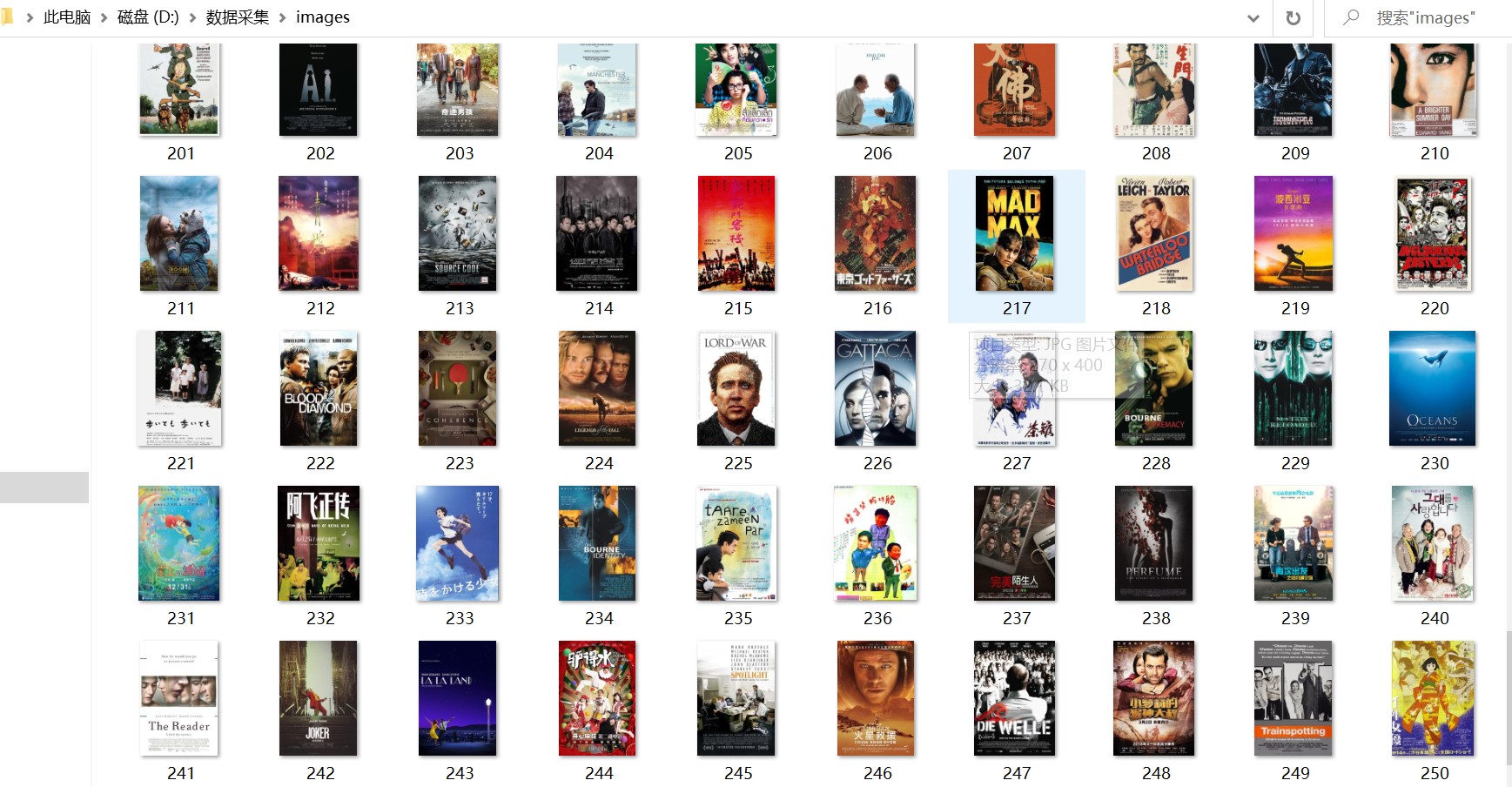
3)心得体会
这个实验改了很久很久很久,报错都是一片红,最印象深刻的两个点是 start_url要去掉列表,以及在区分导演和演员时列表没法切割。总之还是要多加练习呀。
代码地址:
