朴素贝叶斯 - 预测你能找到女朋友吗?
朴素贝叶斯
是一种对待分类项进行分类的算法
主要有以下几个步骤
1.人工给出一些训练数据(每个数据有多个属性F1,F2...Fn),并对每条数据标注人工看法下的分类属于哪类(C1,C2,C3...)
2.输入第一步的数据,根据朴素贝叶斯算法,求得分类器(实际上就是求得每个类别之下,各属性所占的概率,比如在分类C1下,属性F1为true 的频率是多少,再求属性为false的频率有多少,这里的F1属性,我们举例的限定是只有true和false2种情况可选)
3.需要对新的待分类数据进行分类时,根据第二步得到的分类器,求得该数据项发生的前提下在各个分类下发生的概率(P1,P2..Pn),找到概率最大的一个,将该数据分为该类
1.中指出的数据中被抽象出来的属性维度,需要自己衡量所需的属性有哪些
接下来说说公式的推导和理解
A,B为独立事件
发生B的概率为 P(B)
发生A的概率为 P(A)
在B发生时,再发生A的概率 P(A|B)
在A发生时,再发生B的概率 P(B|A)
A,B同时发生的概率 P(AB) = P(A∩B)
图:
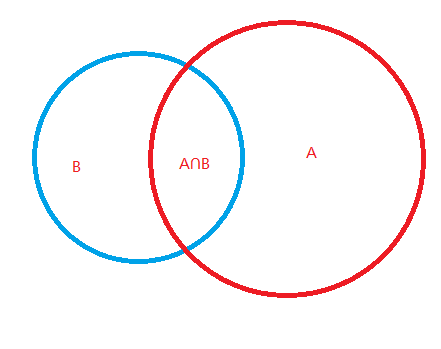
例如 ,A为 0.8 ,B为 0.6 , A∩B = 0.2
A,B为独立事件
发生B的概率为 P(B) = 0.6
发生A的概率为 P(A) = 0.8
A,B同时发生的概率 P(AB) = P(A∩B) = 0.2
在B发生时,再发生A的概率 P(A|B) = P(A∩B)/P(B) = 0.2 / 0.8 = 0.25
在A发生时,再发生B的概率 P(B|A) = P(A∩B)/P(A) = 0.2 / 0.6 = 0.33
看这2个式子
P(A|B) = P(A∩B)/P(B)
P(B|A) = P(A∩B)/P(A)
我们可以导出朴素贝叶斯的公式
(1). P(A∩B) = P(A|B) * P(B)
(2). P(A∩B) = P(B|A) * P(A)
(1) = (2)
P(A|B) * P(B) = P(B|A) * P(A)
P(A|B) = P(B|A) * P(A) / P(B)
在含义上也等于
P(A|B) = P(A∩B) / P(B) //A∩B的部分占B面积的百分比
类似的
P(A|B) = P(A|B) * P(B) / P(A)
举例:
在1984年中的某一天
会下雨的地区为 80%
忘记带伞的人占 20%
在忘记带伞的人中处在下雨地区的人占 10%
问:处于会下雨的地区的人中忘记带伞的人占百分之多少?
P(B) = 0.8
P(A) = 0.2
P(B|A) = 0.1
P(A|B) = ?
根据公式 = P(B|A) * P(A) / P(B) = 0.1 * 0.8 / 0.2 = 0.08 / 0.2 = 0.4
如果事件A有多种可能性 A = {A1,A2}
这时
P(A|B) = P(B|A) * P(A) / P(B)
P(A1|B) = P(B|A1) * P(A1) / P(B)
P(A1|B) = P(B|A1) * P(A1) / P(A1∩B) + P(A2∩B)
P(A1|B) = P(B|A1) * P(A1) / (P(B|A1)*P(A1) + P(B|A2)*P(A2))
在含义上也等于
P(A1|B) = P(A1∩B) / P(A1∩B) + P(A2∩B)
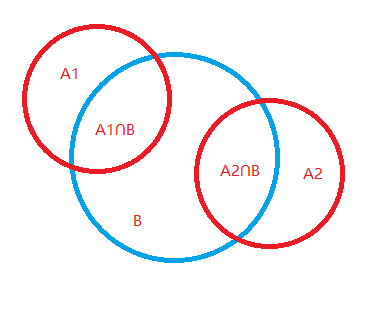
A = {A1,A2...Aj}
P(A1|B) = P(B|A1) * P(A1) / Σnj=1 P(B|Aj) * P(Aj)
P(A1|B) = P(A1∩B) / P(A1∩B) + P(A2∩B) + ...P(An ∩ B)
朴素贝叶斯分类器
实际情况下,一个事件往往受多个特征影响, 影响 B 的因素有 n 个,分别是 b1,b2,…,bn。
P(A|B) = P(B|A) * P(A) / P(B)
中的B(先验的)有特征属性 b1,b2,b3。。。bn (对应的 A 也有这些属性 )
P(A|B) = P(A|b1,b2,b3...bn) = P(b1,b2,b3...bn|A) * P(A) / P(b1,b2,b3...Fn)
其中
P(b1,b2,b3...Fn) = P(B)
P(b1,b2,b3...Fn|A) = P(B|A)
那么 P(b1,b2,b3...bn|A) 应该如何计算呢?
在每个属性 b1,b2...bn 没有关联性的前提下
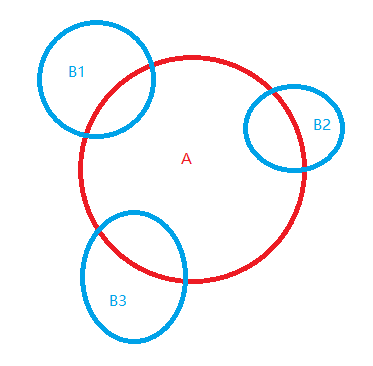
P(b1,b2,b3...bn|A) = P(b1|A) * P(b2|A) ... * P(bn|A)
所以
P(A|b1,b2,b3...bn) = P(b1|A) * P(b2|A) ... * P(bn|A) * P(A) / P(b1,b2...bn)
n
=i=1 P(bi|A) * P(A) /P(b1,b2...bn)
代码:
一个测试你是否会被妹子喜欢的例子:
//朴素贝叶斯 //是一种对待分类项进行分类的算法 //主要有以下几个步骤 //1.人工给出一些训练数据(每个数据有多个属性F1,F2...Fn),并对每条数据标注人工看法下的分类属于哪类(C1,C2,C3...) //2.输入第一步的数据,根据朴素贝叶斯算法,求得分类器(实际上就是求得每个类别之下,各属性所占的概率,比如在分类C1下,属性F1为true 的频率是多少,再求属性为false的频率有多少,这里的F1属性,我们举例的限定是只有true和false2种情况可选) //3.需要对新的待分类数据进行分类时,根据第二步得到的分类器,求得该数据项发生的前提下在各个分类下发生的概率(P1,P2..Pn),找到概率最大的一个,将该数据分为该类 //1.数据中被抽象出来的属性维度,需要自己衡量所需的属性有哪些 import java.util.HashMap; import java.util.LinkedList; import java.util.List; import java.util.Map; //离散数据的 朴素贝叶斯 public class NaiveBayesDCT { int fieldNum; //包含人工分类的一列维度 List<List<Integer>> datas; List<Integer>[] fieldValueOptions; //映射,方便找全局索引(一个类别下的一个属性被分配一个索引号)(索引号从0到+) //<fieldCountIndex :<fieldValue :fieldIndex>> Map<Integer, Map<Integer, Integer>> fci2fv2fi; //反向映射,全局索引找fieldCountIndex(类别索引) //fieldIndex 2 fieldCountIndex Map<Integer, Integer> fi2fci; int fieldIndexCount; //P(C) ,每个人工分类类别占训练样本的百分比 Map<Integer, Float> clazz2Prob; //按类别分类的数据 //<类别:数据[]> Map<Integer, List<List<Integer>>> classifyData; //<类别:<全局属性索引号:概率统计值>> Map<Integer, Map<Integer, Float>> trainData; //一个维度一个List,每个list的integer表示该维度下允许的可选值是哪些,比如对野外采集的农产品有重量维度:轻,中,重 ,对应1,2,3 //最后一列是人工标注的分类 //f1,f2,...fn,clazzTypes public NaiveBayesDCT(List<Integer>... fieldValueOptions) { this.fieldNum = fieldValueOptions.length; this.fieldValueOptions = fieldValueOptions; datas = new LinkedList<>(); trainData = new HashMap<>(); } public void addData(List<Integer> data) { if (data.size() != fieldNum) //check 输入的数据维度要一致 return; datas.add(data); } private void initTrainData() { fci2fv2fi = new HashMap<>(); fi2fci = new HashMap<>(); for (int filedCount = 0; filedCount < fieldValueOptions.length - 1; filedCount++) { //每类属性 ,抛开人工分类的属性 fci2fv2fi.put(filedCount, new HashMap<Integer, Integer>()); for (int fv : fieldValueOptions[filedCount]) { //这类属性的每个可能出现的属性值 fci2fv2fi.get(filedCount).put(fv, fieldIndexCount); //属性的每一个可能出现的值,被分配一个全局索引 fi2fci.put(fieldIndexCount, filedCount); fieldIndexCount++; } } //初始化人工标注类别属性的 每个类别的默认概率为0 for (int clazzType : fieldValueOptions[fieldNum - 1]) { trainData.put(clazzType, new HashMap<Integer, Float>()); Map<Integer, Float> field2Prob = trainData.get(clazzType); for (int tmpfi = 0; tmpfi < fieldIndexCount; tmpfi++) { field2Prob.put(tmpfi, 0f); //默认是 0% } } } public void train() { trainData = new HashMap<>(); //先按人工标注的类别分类,再计算该分类下,每个维度属性的可选值的统计概率 spliteByClass(); initTrainData(); //<人工分类类型:[属性索引]=统计次数> Map<Integer, int[]> fieldIndexSavedCountsMap = new HashMap<>(); //按分类遍历数据集合 for (Map.Entry<Integer, List<List<Integer>>> e : classifyData.entrySet()) { int clazzType = e.getKey(); int[] fieldIndexSavedCounts = new int[fieldNum]; fieldIndexSavedCountsMap.put(clazzType, fieldIndexSavedCounts); Map<Integer, Float> field2Prob = trainData.get(clazzType); //遍历该分类下的所有数据 List<List<Integer>> datas = e.getValue(); for (int i = 0; i < datas.size(); i++) { List<Integer> data = datas.get(i); //对该分类下的一个样本的每个属性统计概率(先求出该属性现次数的总和) for (int fci = 0; fci < data.size() - 1; fci++) { //属性索引 - 属性值 - 属性全局索引 int fieldIndex = -1; //该数据类别的全局属性索引号 try { fieldIndex = fci2fv2fi.get(fci).get(data.get(fci)); } catch (NullPointerException ex) { //数据中给出了未再构造函数中声明的属性值 ex.printStackTrace(); throw new RuntimeException("fieldIndex :" + fci + " value : " + data.get(fci) + " not statement in constructor params"); } field2Prob.put(fieldIndex, field2Prob.get(fieldIndex) + 1); //统计值+1 fieldIndexSavedCounts[fci]++; } } } if (datas.size() <= 0) return; //再算概率 = (统计值 / 总数量),最后几个是人工分类类别(数量=分类类别中的类别个数) for (Map.Entry<Integer, Map<Integer, Float>> e : trainData.entrySet()) { int clazzType = e.getKey(); int[] fieldIndexSavedCounts = fieldIndexSavedCountsMap.get(clazzType); for (Map.Entry<Integer, Float> e2 : e.getValue().entrySet()) { int globalFieldIndex = e2.getKey(); float sumCount = trainData.get(clazzType).get(globalFieldIndex); float prob = sumCount / fieldIndexSavedCounts[fi2fci.get(e2.getKey())]; //prob trainData.get(e.getKey()).put(e2.getKey(), prob); } } clazz2Prob = new HashMap<>(); for (Map.Entry<Integer, List<List<Integer>>> e2 : classifyData.entrySet()) { clazz2Prob.put(e2.getKey(), ((float) e2.getValue().size() / datas.size())); } System.out.println("==== trainData ===="); System.out.println(trainData); //分类1={全局属性索引1=概率,全局属性索引2=概率....} , 分类2={全局属性索引1=概率,全局属性索引2=概率....} .... System.out.println("==== clazz2Prob ===="); System.out.println(clazz2Prob); } private void spliteByClass() { classifyData = new HashMap<>(); for (int clazzType : fieldValueOptions[fieldNum - 1]) { classifyData.put(clazzType, new LinkedList<List<Integer>>()); } for (int i = 0; i < datas.size(); i++) { List<Integer> data = datas.get(i); int clazzType = data.get(fieldNum - 1); classifyData.get(clazzType).add(data); } } //对数据进行分类 public int caculClass(List<Integer> data) { //C = CLASS TYPE {c1,c2,c3...cn} //B = DATA //P(C|B) = P(B|C) * P(C) / P(B) // ∝ P(b1|c1) * P(b2|c2) * ..... * P(C) * P(B) // ∝ P(b1|c1) * P(b2|c2) * ..... * P(C) if (data.size() != fieldNum - 1) return -1; //数据的属性维度和定义的不一致 float maxDataClassProb = 0; //保存各分类中,概率最大的概率值 int maxDataClassProbClassType = -1; //概率最大的概率值的分类类型 Map<Integer, Float> dataClazz2Prob = new HashMap<>(); //key:分类类型 c1,c2...cn, value:该分类在data发生情况下的 概率值 P(C|B) for (Map.Entry<Integer, Map<Integer, Float>> trainClazzData : trainData.entrySet()) { int clazzType = trainClazzData.getKey(); Map<Integer, Float> filedProbMap = trainClazzData.getValue(); float probProduct = clazz2Prob.get(clazzType); //P(C) 的值 for (int fieldCountIndex = 0; fieldCountIndex < data.size(); fieldCountIndex++) { int val = data.get(fieldCountIndex); if(!fci2fv2fi.get(fieldCountIndex).containsKey(val)) return -1; //没有该属性存在定义中 int globalFieldIndex = fci2fv2fi.get(fieldCountIndex).get(val); probProduct *= filedProbMap.get(globalFieldIndex); } if (maxDataClassProb < probProduct) { maxDataClassProb = probProduct; maxDataClassProbClassType = clazzType; } dataClazz2Prob.put(clazzType, probProduct); } System.out.println(dataClazz2Prob); return maxDataClassProbClassType; } public static void main(String[] a) { //属性1 List<Integer> face = new LinkedList<Integer>(); face.add(10); //好看的脸 face.add(0xdeadface); //不好看的脸 //属性2 List<Integer> FightCapacity = new LinkedList<Integer>(); FightCapacity.add(999); //999战斗力 FightCapacity.add(5); //5战斗力 //人工分类属性 List<Integer> beLiked = new LinkedList<>(); beLiked.add(1); //被人喜欢 beLiked.add(0); //不被人喜欢 NaiveBayesDCT nbdct = new NaiveBayesDCT(face, FightCapacity, beLiked); //初始化训练数据 List<Integer> data = new LinkedList<>(); data.add(10); //f1 data.add(999); //f2 data.add(1); //clazzType ,人工标注 nbdct.addData(data); data = new LinkedList<>(); data.add(0xdeadface); data.add(5); data.add(0); nbdct.addData(data); //训练 nbdct.train(); //该妹子几乎只喜欢脸好看,战斗力999的 System.out.println(); //进行一次 分类测试 List<Integer> people1 = new LinkedList<>(); people1.add(10); people1.add(999); System.out.println("people1 " + people1); System.out.println("是否被喜欢:" + nbdct.caculClass(people1)); //理想输出:1 //博主: List<Integer> me = new LinkedList<>(); me.add(0xdeadface); me.add(5); System.out.println("me " + me); System.out.println("博主 是否被喜欢:" + nbdct.caculClass(me)); //理想输出:0 List<Integer> people3 = new LinkedList<>(); people3.add(0xdeadface); people3.add(999); System.out.println("people3 " + people3); System.out.println("是否被喜欢: " + nbdct.caculClass(people3)); //理想输出:-1 ,不知道 List<Integer> people4 = new LinkedList<>(); people4.add(5); people4.add(999); System.out.println("people4 " + people4); System.out.println("是否被喜欢: " + nbdct.caculClass(people4)); //理想输出:-1 ,不知道 } }
输出:
==== trainData ==== {0={0=0.0, 1=1.0, 2=0.0, 3=1.0}, 1={0=1.0, 1=0.0, 2=1.0, 3=0.0}} ==== clazz2Prob ==== {0=0.5, 1=0.5} people1 [10, 999] {0=0.0, 1=0.5} 是否被喜欢:1 me [-559023410, 5] {0=0.5, 1=0.0} 博主 是否被喜欢:0 people3 [-559023410, 999] {0=0.0, 1=0.0} 是否被喜欢: -1 people4 [5, 999] 是否被喜欢: -1
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号