
SQL进阶教程1-8 EXISTS-----查询表中不存在的数据、全称量化和存在量化的相互转换、EXISTS与HAVING的互换、使用ALL和ANY对列进行量化
1. 谓词
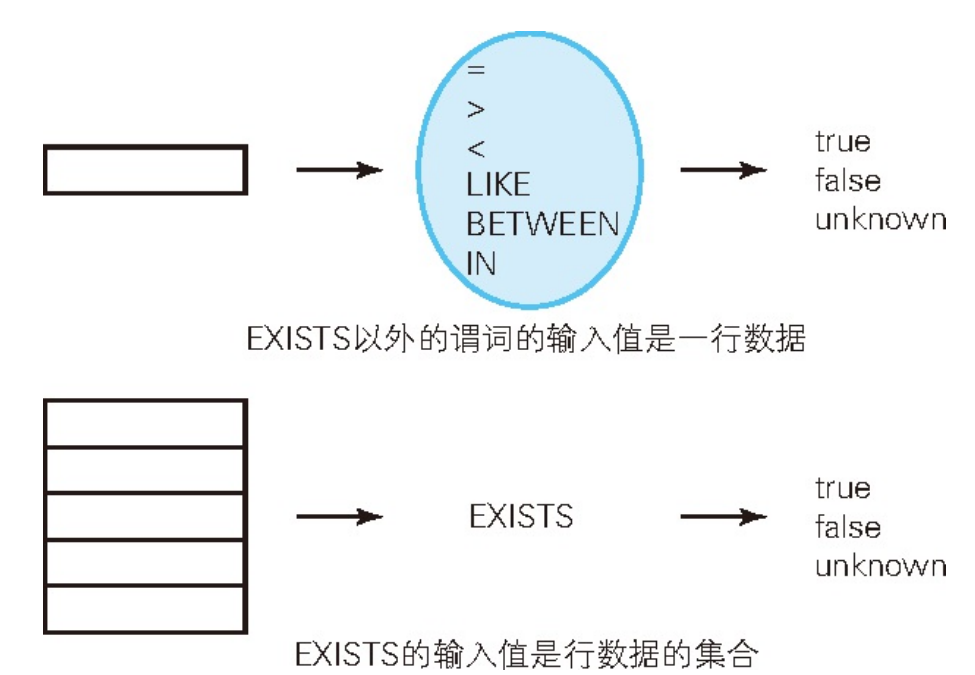
谓词是一种特殊的函数,返回值是真值。例如 < > = Betweeen LIKE IN IS NULL等,返回值都是true false或者unknown。
同样是谓词,但是与= BETWEEB等相比,EXISTS的用法还是不殊的函数,返回值是真值。例如 < > = Betweeen LIKE IN IS NULL等,返回值都是true false或者unknown。
同样是谓词,但是与= BETWEEB等相比,EXISTS的用法还是不太相同的。区别在于“谓词的参数可以取什么值”

可以看出EXISTS的参数是行数据的集合,无论子查询中选择什么样的列,对于EXISTS来说都是一样的。在EXISTS的子查询里,SELECT子句的列表可以有下面这三种写法:
1.通配符: SELECT *
2.常量: SELECT ‘任意内容'
3.列名: SELECT col
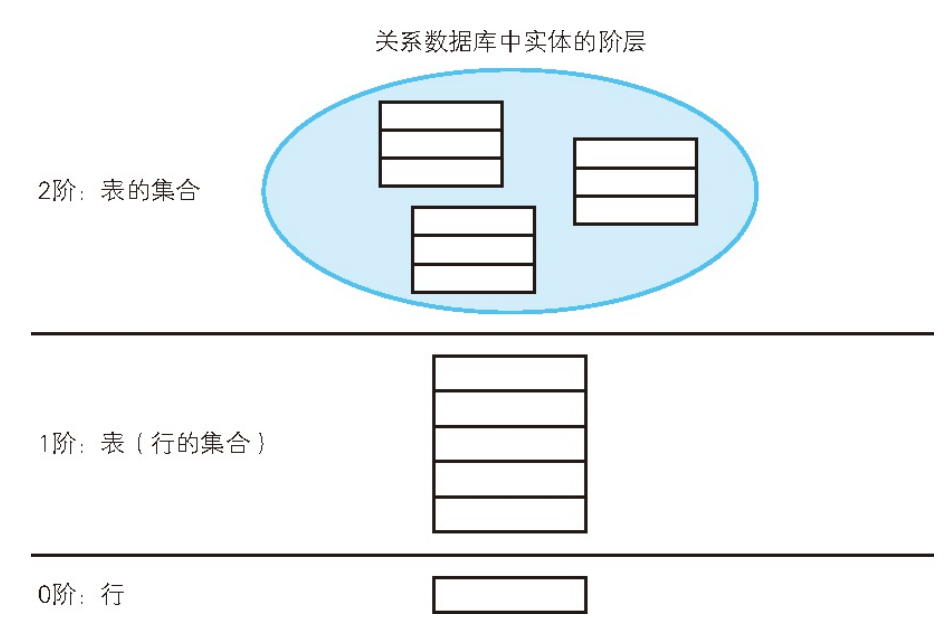
EXISTS的特殊性在与输入值的阶数,谓词逻辑中,根据输入值的阶数对谓词进行分类。
1. =或者BETWEEN 等输入值为一行的谓词叫做“一阶谓词”
2.像EXISTS这样输入值为行的集合的谓词叫做“二阶谓词”;
3. 三阶谓词--------输入值为“集合的集合”的谓词;
4.四阶谓词---------输入值为“集合的集合的集合”的谓词;
..........
可以像上面这样无限地扩展阶数。
高阶函数-------指的是不以一般的原子性的值为参数,而是以函数为参数的函数。
现在,在SQL中EXISTS谓词最高只能接受一阶的实体作为参数。如果将来SQL能支持二阶谓词逻辑,那么我们就能对表进行量化,现在的SQL只能进行“是否包含供应商S1的行”这样的查询,如果能够支持二阶谓词逻辑,那么就能够表达更为复杂的查询,比如“是否存在包含供应商S1的表”。
全称量化和存在量化
谓词逻辑中有量词这类特殊的谓词。
“所有的X都满足条件P”-----------全称量词
“存在至少一个满足条件P的X”-----存在量词。
SQL中的EXISTS谓词实现了谓词逻辑中的存在量词,但是并没有全称量词的实现。全称量词可以由存在量词推到出来,依照德.摩根定律:


实践:
1.查询表中不存在的数据,使用NOT EXISTS实现差集运算功能
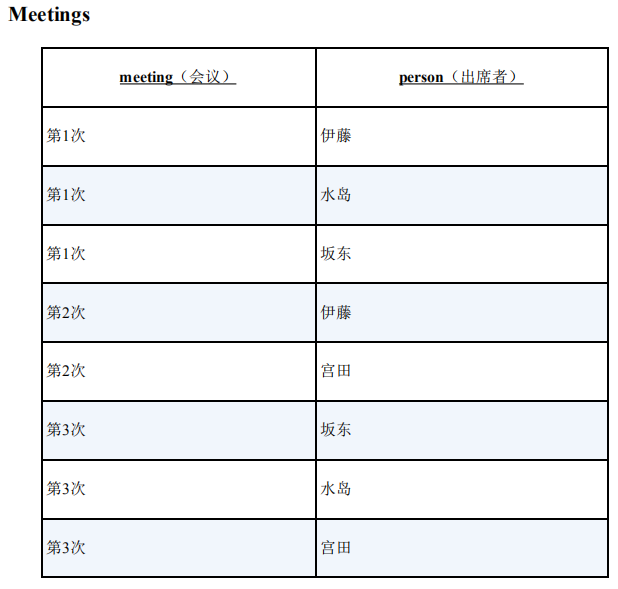
想要从上面的表中查找出“没有参加某次会议的人”,想要的结果如下:
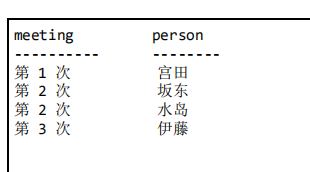
问题分析:一般来说,我们从数据库中查询数据时,都是从表中存在的数据选出满足某些条件的数据。但是某些情况下,需要从表中查找出“数据是否存在”。从阶层上来说,这是更高一阶的问题,即“二阶查询”。
思路:先假设所有人都参加了全部会议,并以此生成一个集合,然后从中减去实际参加会议的人,这样就能得到缺席会议的人。
SELECT Distinct M1.meeting, M2.person FROM Meetings M1 CROSS JOIN Meetings M2 EXCEPT SELECT meeting, person FROM Meetings;
或者
SELECT DISTINCT M1.meeting, M2.person FROM Meetings M1 CROSS JOIN Meetings M2 WHERE NOT EXISTS ( SELECT M3.* FROM Meetings M3 WHERE M1.meeting = M3.meeting AND M2.person = M3.person);
2.全称量化: "肯定<->双重否定之间的转化"
使用EXISTS谓词来表达全称量化,将“所有的行都XXX”转化为“不XX的行一行都不存在”。
如下是一张存储了学生考试成绩的表:
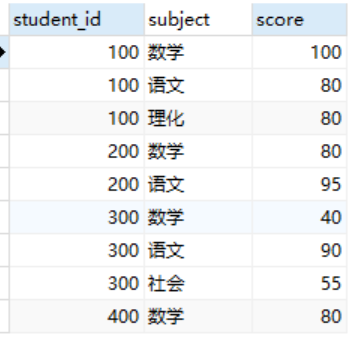
查找同时满足如下两个条件的学生:
1.数学的分数在80分以上;
2.语文的分数在50分以上。
像这样的需求,我们在实际业务中应该会经常遇到,但是乍一看可能会觉得不太像是全称量化的条件。改成下面的说法:
“某个学生的所有行数据中,如果科目是数学,则分数在80分以上;如果科目是语文,则分数在50分以上。”
这其实是针对同一个集合内的行数据进行了条件分支后的全称量化。
SELECT DISTINCT student_id FROM TestScores ts1 WHERE subject IN ('数学','语文') AND NOT EXISTS ( SELECT * FROM TestScores ts2 WHERE ts1.student_id = ts2.student_id AND 1= CASE WHEN ts2.subject = '数学' AND ts2.score <80 THEN 1 WHEN ts2.subject = '语文' AND ts2.score <50 THEN 1 ELSE 0 END )
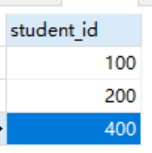
想要排除掉学号为400的学生,因为其只有数学的分数。
FROM TestScores ts1 WHERE subject IN ('数学','语文') AND NOT EXISTS ( SELECT * FROM TestScores ts2 WHERE ts1.student_id = ts2.student_id AND 1= CASE WHEN ts2.subject = '数学' AND ts2.score <80 THEN 1 WHEN ts2.subject = '语文' AND ts2.score <50 THEN 1 ELSE 0 END ) GROUP BY student_id HAVING COUNT(*) = 2
3. 全称量化:集合VS 谓词
EXISTS和HAVING有一个地方很像,就是都是以集合而不是个体为单位来操作数据。很多时候两者是可以互换的。
EG: 如下图是一个项目工程管理表
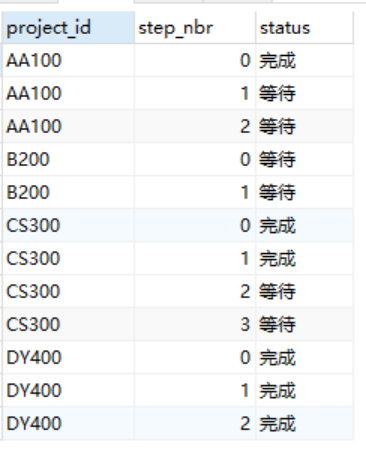

使用HAVING解答:从这张表中查询出哪些项目已经完成到工程1:
SELECT project_id FROM Projects GROUP BY project_id HAVING COUNT(*) = SUM(CASE WHEN step_nbr <= 1 AND status = '完成' THEN 1 WHEN step_nbr >1 AND status = '等待' THEN 1 ELSE 0 END)
使用EXISTS实现如下:
SELECT project_id FROM Projects P1 WHERE NOT EXISTS (SELECT status FROM Projects P2 WHERE P1.project_id = P2.project_id AND status <> CASE WHEN P2.step_nbr <= 1 THEN '完成' ELSE '等待'END) GROUP BY project_id
EXISTS与HAVING相比的有点:
1.性能好,只要有一行满足条件,查询就会中止,不一定需要查询所有行的数据。???? 能够通过连接条件使用“project_id”的列做索引,查询起来更快;
2.使用EXISTS结果里面包含的信息量更大,使用HAVING,结果会被聚合,只能取到项目的ID,使用EXISTS,则能将集合里面的元素的整体都获取到。
4.对列进行量化
如下是一个存储了数组的表。
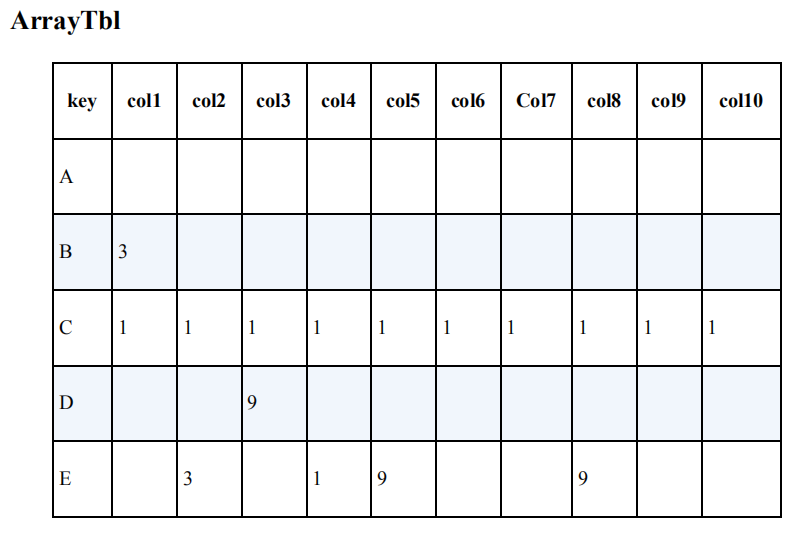
这张表设计不好的原因是:数组中的元素可以自由地增加或者减少,而表中的列却不能这样。即便只是增加或者减少1列,都非常麻烦,相反,行的增加或者减少对系统几乎没有什么影响。数组中的元素不应该对应表中的列,而是应该对应行。
在设计表时有一条原则:让列具有一定的扩展性。
针对上面的表要求查询:
![]()
EXISTS谓词主要用于进行“行方向”的量化-------我的理解是EXISTS主要用来查询某个列或者某几个列(是有限的列)为某个值或者不为某个值的行;
“列方向”的量化-----------大概指的是对所有的列进行条件判断,不知道理解的对不对。
可以使用ALL 或者ANY对所有列的值进行条件判断。
SELECT * FROM ArrayTbl WHERE 1 = ALL (col1, col2, col3, col4, col5, col6, col7, col8, col9,col10)
SELECT *
FROM ArrayTbl
WHERE 9 = ANY (col1, col2, col3, col4, col5, col6, col7, col8, col9,col10)
如果想要查询所有的列都是NULL的列:
SELECT * FROM ArrayTbl WHERE COALSECE(col1, col2, col3, col4, col5, col6, col7, col8, col9,col10) IS NULL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号