

SQL进阶教程1-7 用SQL进行集合运算: 比较两个表是否相等、用差集实现关系除法运算、寻找相等的子集
集合运算符的参数是集合,从数据库实现层面上来说就是表或者视图。
注意事项:
1.SQL能够操作具有重复行的集合,可以通过可选项ALL来支持。
一般的集合论是不允许集合里面存在重复元素的,因此集合{1,1,2,3,3}和集合{1,2,3}被视为相同的集合,但是关系数据库的表允许存在重复的行,称为多重集合。
ALL的作用和SELECT子句里面的DISTINCT可选项刚好相反。
1.SQL集合运算符也提供了允许重复和不允许重复的两种用法,如果直接使用UNION或者INTERSECT,结果里就不会出现重复的行。
如果想在结果里面留下重复行,可以加上可选项ALL。写作UNION ALL。
2. 集合运算符为了排除掉重复行,默认地会发生排序,而加上可选项ALL之后,就不再排序,所以性能会有提升。这是常用的非常有效地用于优化查询性能的方法,
所以如果不关心是否存在重复行,或者确定结果里面不会产生重复行,加上可选项ALL会更好些。
2.集合运算符有优先级
标准SQL规定,INTERSECT比UNION和EXCEPT优先级更高,因此,当同事使用UNION和INTERSECT,又想让UNION优先执行时,必须用括号明确地指定运算顺序。
3.各个DBMS提供商在集合运算的实现程度上参差不齐。
早期的SQL对集合运算的支持程度不是很高,受到这一影响,各个数据库提供商的实现程度也参差不齐。
SQL Server从2005版开始支持INTERSECT 和EXCEPT,而MySQL还都不支持。 还有像Oracle这样,实现了EXCEPT功能但是却命名为MINUS的数据库。
4.除法运算没有标准定义。
四则运算里面的 和(UNION) 差(EXCEPT) 积(CROSS JOIN) 商都被引入了标准的SQL,但是商并没有标准化,需要自己写SQL实现。
5.比较表和表
在迁移数据库的时候,或者需要比较备份数据和最新数据的时候,我们需要调查两张表是否是相等的。
这里所说的“相等”指的是行数和列数以及内容都相同,即“是容一个集合”的意思。
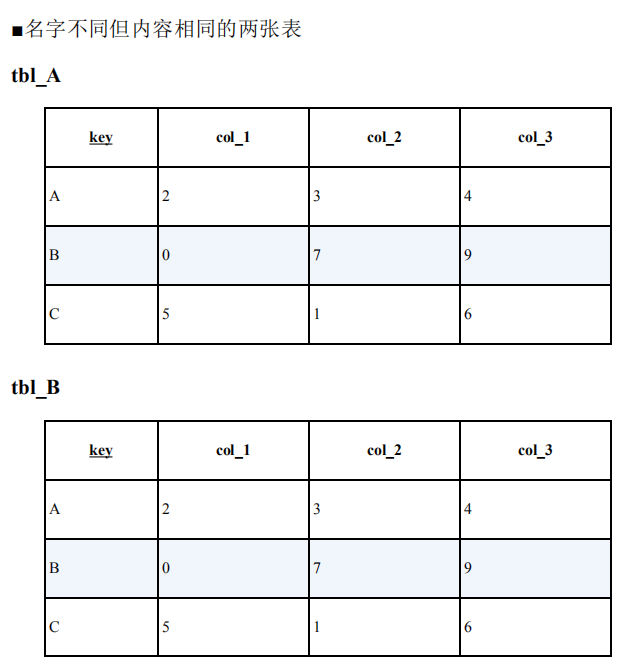
如何使用SQL确定两张表是相等还是不相等呢?
方法一:假设已经实现确定了tbl_A和tbl_B的行数是一样的,如果行数不一样,就不需要再比较其他的了。
SQL:
SELECT COUNT(*) AS row_cnt FROM (SELECT * FROM tbl_A UNION ELECT * FROM tbl_B) TMP;
如果此函数的执行结果与A或者B的行数不一致,说明A与B是不相等的,否则两张表相等。
我们也可以只比较表里的一部分列或者一部分行,在WHERE子句中加入过滤条件就可以比较了。
需要注意的是,此条SQL语句对于一个自身拥有重复行的表是不生效的,由此,我们应该明白主键对表来说是多么的重要。
方法二:
在集合里,判定连个集合是否相等时,一般使用下面这两种方法:
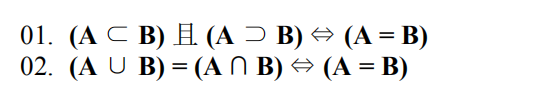
如果集合A和集合B相等,那么 A UNION B = A = B = A INTERSECT B 都是成立的,剩下的问题是对A和B 分别进行UNION运算和INTERSECT运算后,如何比较这两个结果。
因为我们能够确定的是![]()
因此只要判定 (A UNION B)EXCEPT (A INTERSECT B) 的结果集是不是空集就可以了,如果A=B,则这个结果集是空集,否则这个结果集里面肯定有数据。
SELECT CASE WHEN COUNT(*) = 0 THEN '相等' ELSE '不相等' END AS result FROM ( (SELECT * FROM tbl_A UNION SELECT * FROM tbl_B) EXCEPT (SELECT * FROM tbl_A INTERSECT SELECT * FROM tbl_B) )
此条SQL语句不用事先知道表的行数,但是有一些缺陷
1.性能有所下降,因为这里需要进行4次排序:3次集合运算加上1次DISTINCT
2.因为这里使用了INTERSECT 和EXCEPT,所以目前这条SQL不能在MySQL中执行。
输出两张表中不同的部分:
(SELECT * FROM tbl_A EXCEPT SELECT * FROM tbl_B) UNION (SELECT * FROM tbl_B EXCEPT SELECT * FROM tbl_A)
6.用差集实现关系除法运算
进行除法运算,方法比较多,其中具有代表性的是下面三个:
1.嵌套使用NOT EXISTS;
2.使用HAVING子句转换成一对一关系;
3. 将除法变成减法;
将除法变成减法:
SELECT DISTINCT emp FROM EmpSkills ES1 WHERE NOT EXISTS (SELECT skill FROM Skills EXCEPT SELECT skill FROM EmpSkills ES2 WHERE ES1.emp = ES2.emp);
关联子查询是为了使SQL能够实现类似面向过程语言中的循环功能引入的。上面这条SQL语句的处理方法与面向过程语言里面的循环、终端控制处理很像。
将两张表当成两个文件,然后一行行循环处理,针对某一个员工循环判断各种技术的掌握情况。如果存在企业需求的技术,就进行减法运算;如果不存在就中止
该员工的循环,继续对下一个员工执行同样的处理。
7.寻找相同的子集
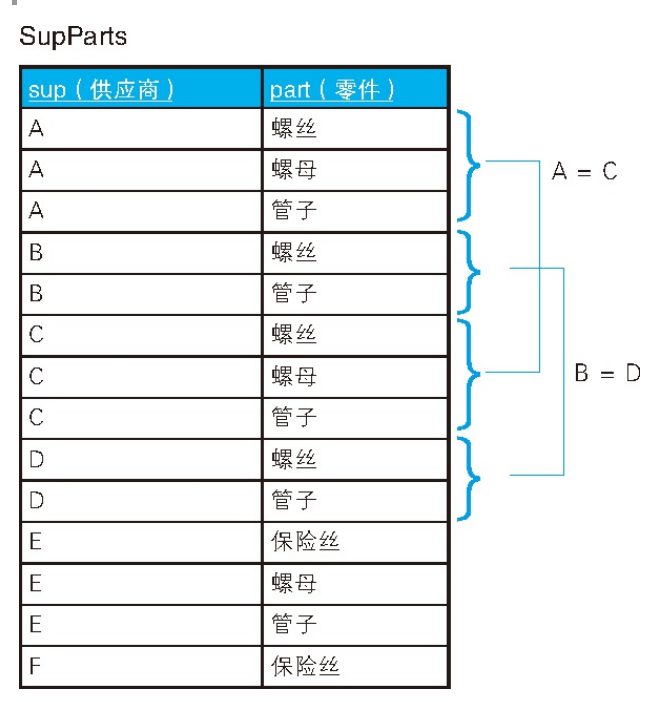
现在想要找出,经营的零件在种类数和种类上都完全相同的供应商组合,答案是A-C B-D这两组。
SQL并没有任何用于检查集合的包含关系或者相等性的谓词,IN谓词只能用来检查元素是否属于某个集合,而不能检查集合是否是某个集合的子集。
对于连个不同的供应商,我们应该判断下面这两个条件:
1.连个供应商都经营同种类型的零件;
2.两个供应商经营的零件种类数相同。
SELECT SP1.sup AS s1, SP2.sup AS s2 FROM SupParts SP1, SupParts SP2 WHERE SP1.sup < SP2.sup -- 生成供应商的全部组合 AND SP1.part = SP2.part -- 条件1 :经营同种类型的零件 GROUP BY SP1.sup, SP2.sup HAVING COUNT(*) = (SELECT COUNT(*) -- 条件2 :经营的零件种类数相同 FROM SupParts SP3 WHERE SP3.sup = SP1.sup) AND COUNT(*) = (SELECT COUNT(*) FROM SupParts SP4 WHERE SP4.sup = SP2.sup);
对于Having中的两组Count(*)比较,每组Count(*)比较中:
前面的COUNT(*)是SP1和SP2不同供应商但是供应相同类型的零件的数量,后面的COUNT(*)是SP1或者SP2中该供应商供应的所有配件数量
COUNT(*)的比较充分告诉我们,SQL在比较两个集合时,并不是以行为单位来比较的,而是将集合当做整体来处理的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号