爬虫的基本原理
通用网络爬虫的实现原理及过程如下图所示:
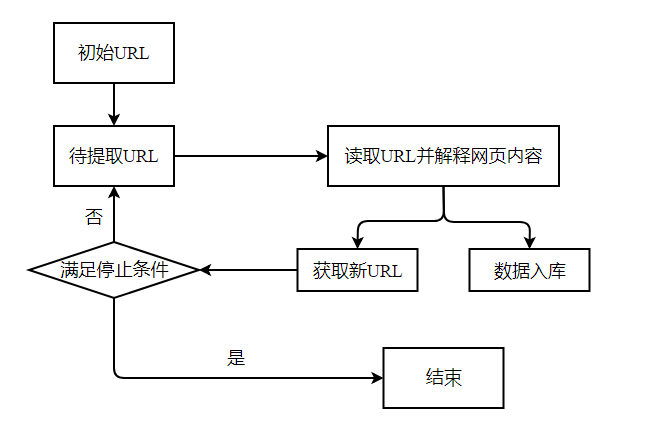
通用网络爬虫的实现原理:
(1)获取初始的URL。初始的URL地址可以人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。
(2)根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,先爬取当前URL地址中的网页信息,然后解析网页信息内容,将网页存储到原始数据库中,并且在当前获得的网页信息里发现新的URL地址,存放于一个URL队列里面。
(3)从URL队列中读取新的URL,从而获得新的网页信息,同时在新网页中获取新URL,并重复上述的爬取过程。
(4)满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件,爬虫则会在停止条件满足时停止爬取。如果没有设置停止条件,爬虫就会一直爬取下去,一直到无法获取新的URL地址为止。
聚焦网络爬虫的执行原理和过程与通用爬虫大致相同,在通用爬虫的基础上增加两个步骤:定义爬取目标和筛选过滤URL。原理如下图所示:

聚焦网络爬虫的实现原理:
(1)制定爬取方案。在聚焦网络爬虫中,首先要依据需求定义聚焦网络爬虫爬取的目标以及整体的爬取方案。
(2)设定初始的URL。
(3)根据初始的URL抓取页面,并获得新的URL。
(4)从新的URL中过滤掉与需求无关的URL,将过滤后的URL放到URL队列中。
(5)在URL队列中,根据搜索算法确定URL的优先级,并确定下一步要爬取的URL地址。因为聚焦网络爬虫具有目的性,所以URL的爬取顺序不同会导致爬虫的执行效率不同。
(6)得到新的URL,将新的URL重现上述爬取过程。
(7)满足系统中设置的停止条件或无法获取新的URL地址时,停止爬行。
摘自《实战Python网络爬虫》
