使用pandas库实现csv行和列的获取
1、读取csv
import pandas as pd df = pd.read_csv('路径/py.csv')
2、取行号
index_num = df.index
举个例子:
import pandas as pd df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8') index_num = df.index print(index_num)

3、取出行
import pandas as pd df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None) # print(type(df)) df.columns = ['a','b','c','d','e','f'] # 获取行数 # index_num = df.index # print(index_num) # 取出某一行 # row_data_1 = df.iloc[0] # row_data_2 = df.iloc[[0]] # 取出连续的行 # row_data_3 = df.iloc[0:2] # row_data_4 = df[0:2] # 取出不连续的行 # row_data_5 = df.iloc[[0,2]] # print(row_data_5)
只取一行
可以使用df.iloc[行号],得到的是series
也可以使用df.iloc[[行号]],得到的是dataframe
row_data_1 = df.iloc[0] # pandas series
row_data_2 = df.iloc[[0]] # dataframe
loc是显式的索引,默认第一行的行号为1,行号从1计数
iloc是隐式的索引,默认第一行的行号为0,行号从0计数
row_data_1
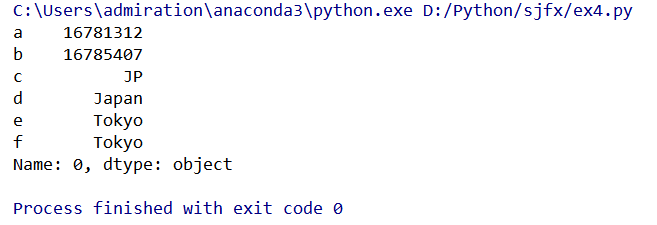
row_data_2

取连续的几行
可以用df.iloc[行号:行号],也可以用df[行号:行号],得到的都是dataframe
row_data_3 = df.iloc[0:2]
row_data_3 = df[0:2]
row_data_3

row_data_4

取出不连续的几行
使用df.iloc[[行号,行号]],特别注意是两个方括号,中间是逗号,得到的是dataframe
row_data_5 = df.iloc[[0,2]]
row_data_5

4、取出列
import pandas as pd df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None) # print(type(df)) df.columns = ['a','b','c','d','e','f'] # 只取一列 # col_data_1 = df['a'] # 单独一列是个series # col_data_2 = df.loc[:,'a'] # 同上,但比较复杂,一般不用 # col_data_3 = df.iloc[:,0] # 同上,可以在不知道列名的时候用 # # col_data_4 = df[['a']] # 单独一列是个df # col_data_5 = df.loc[:,['a']] # 同上,但比较复杂,一般不用 # col_data_6 = df.iloc[:,[0]] # 同上,可以在不知道列名的时候用 # print(col_data_4) # 获取指定的几列 # cols_data_1 = df[['a','b']] # DataFrame, 指定某几列,直接用列名 # cols_data_2 = df.loc[:,['a','b']] # 同上,但比较复杂,一般不用 # cols_data_3 = df.iloc[:,[0,2]] # 同上,可以在不知道列名的时候用 # print(cols_data_1) # 获取指定的连续列 # cols_data_4 = df.loc[:,'a':'d'] # 指定连续列,用列名 # cols_data_5 = df.iloc[:,0:4] # 指定连续列,用数字 # print(cols_data_4)
只取一列
col_data_1 = df['a']# 单独一列是个seriescol_data_2 = df.loc[:,'a']# 同上,但比较复杂,一般不用col_data_3 = df.iloc[:,0] # 同上,可以在不知道列名的时候用
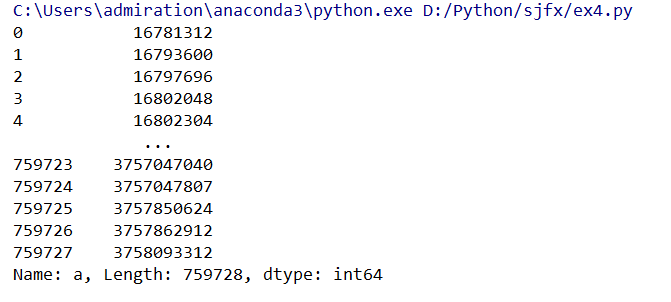
以上三种均为只取一列的操作,并且是等效的,获取的都是series类型
下面三种也是等效的,但是获取的是dataframe类型
col_data_4 = df[['a']] # 单独一列是个df col_data_5 = df.loc[:,['a']] # 同上,但比较复杂,一般不用 col_data_6 = df.iloc[:,[0]] # 同上,可以在不知道列名的时候用
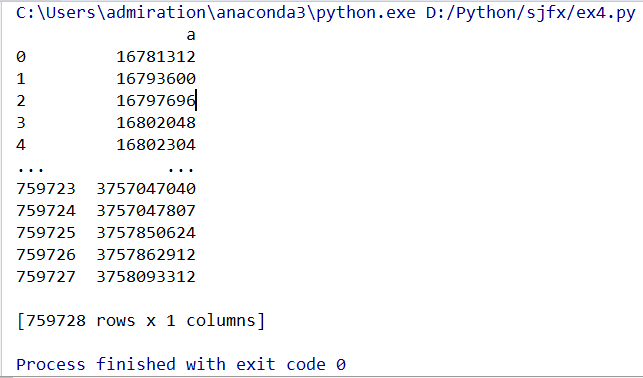
取指定的某几列
cols_data_1 = df[['a','b']] # DataFrame, 指定某几列,直接用列名 cols_data_2 = df.loc[:,['a','b']] # 同上,但比较复杂,一般不用 cols_data_3 = df.iloc[:,[0,2]] # 同上,可以在不知道列名的时候用

获取指定的连续几列
cols_data_4 = df.loc[:,'a':'d'] # 指定连续列,用列名 cols_data_5 = df.iloc[:,0:4] # 指定连续列,用数字
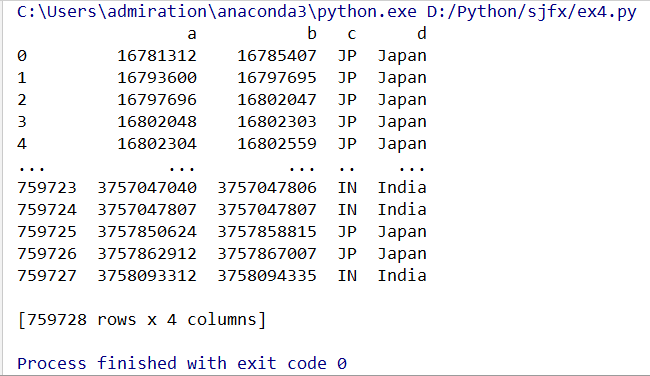
5、取指定行和列
import pandas as pd df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None) # print(type(df)) df.columns = ['a','b','c','d','e','f'] # 获取指定行列 # 第一种,列索引用数字表示 # data_1 = df.iloc[[1,3],[0]] # data_2 = df.iloc[[1,3],0] # data_3 = df.iloc[[1,3],1:3] # data_4 = df.iloc[[1,3],[1,3]] # print(data_4) # 第二种,列索引直接引用列名 # data_5 = df.loc[1,['a','d']] # data_6 = df.loc[[1],['a','d']] # data_7 = df.loc[[1,3],'a':'d'] # data_8 = df.loc[[1,3],['a','d']] # print(data_8)
列索引用数字表示
第一种情况是列索引用数字表示, df.iloc[行索引表达,列索引表达],规则跟上面行索引一模一样。
data_1 = df.iloc[[1,3],[0]]

data_2 = df.iloc[[1,3],0] # series
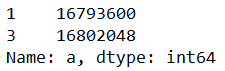
data_3 = df.iloc[[1,3],1:3]

data_4 = df.iloc[[1,3],[1,3]]
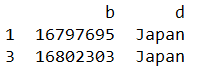
列索引直接引列名
第二种情况是列索引直接引列名(行索引不存在这个问题,因为pandas没有所谓'行名'),就要用df.loc[行索引,列名索引。
data_5 = df.loc[1,['a','d']] # series

data_6 = df.loc[[1],['a','d']]
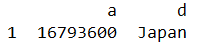
data_7 = df.loc[[1,3],'a':'d']

data_8 = df.loc[[1,3],['a','d']]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号