
pytorch的学习-B站跟学土堆版-学习视频网址(https://www.bilibili.com/video/BV1hE411t7RN/?spm_id_from=333.999.0.0)
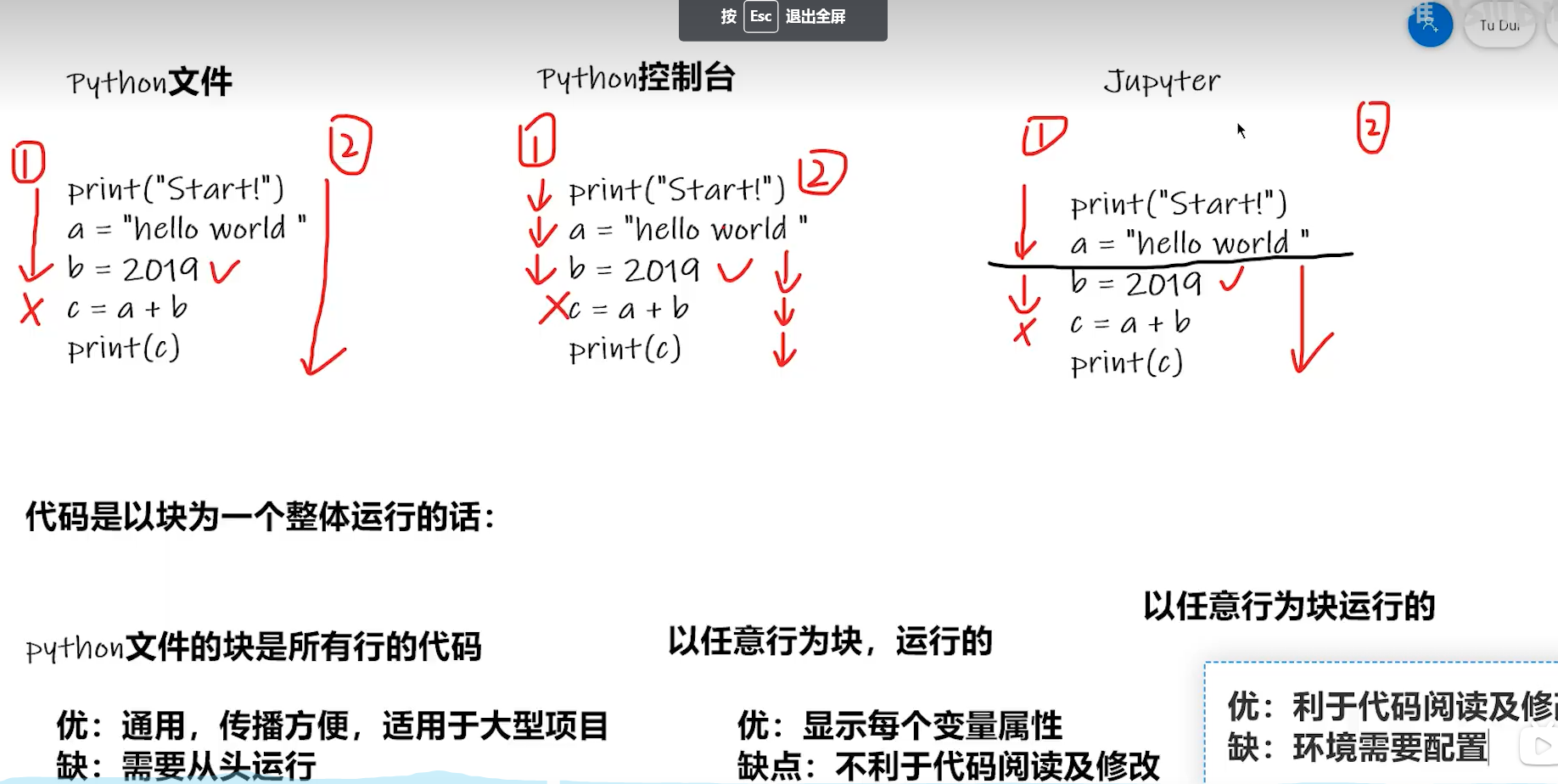
三种编译方式的优缺点
Pytroch中的加载数据
主要涉及了两个类,一个叫Dataset,一个叫Dataloader.
举一个不恰当的例子,我们要在诸多的垃圾(数据)中找到我们所需要的垃圾(数据),Dataset就是将其中的可回收垃圾提取出来,并且将它们进行编号,同时可以根据编号获取相对应的垃圾,同时获取相对应的label.总结就是提供一种方式去获取数据及其label.(包括1.如何获取每一个数据及其label,2.告诉我们总共有多少的数据)
Dataloader为后面的网络提供了不同的数据形式
下面是使用Dataset类的步骤及编码----(主要是重写两个方法)
def __getitem_(self, index): raise NotImplementedError def _add_(self, other): return ConcatDataset([self, other])
Dataset类代码实战
from torch.utils.data import Dataset
//引入图片的相关函数
from PTL import Image
//os库提供了基本的系统文件交互的功能,类似于访问系统文件夹中的内容。
import os
class MyData(Dataset):
//self相当于java中的this,可以理解为一个全局变量。
//root_dir就是指某个根文件夹的路径,相对地址
//label是数据的标签,同时也是存储数据的上一层路径
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.image_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len)(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
ants_dataset = MyData(root_dir, ants_label_dir)
1.os操作示例,比如,获取某一个文件下的所有文件,
dir_path="dataset/train/ants"
img_path_list = os.listdir(dir_path)
img_path_list中就是所有文件名称数组。
2.介绍一个os库下的一个函数--->os.path.join函数-->路径的拼接
root_dir = "dataset/train"
label_dir = "ants"
path = os.path.join(root_dir,label_dir)
TensorBoard的使用一1.TensorBoard使用
我们可以看到训练过程中losses的变化,从而判断我们的训练是否是正常的状态
From torch.utils.tensorboard import SummaryWriter
SummaryWriter类的作用:
官方文档翻译:
将条目直接写入 log_dir 中的事件文件以供 TensorBoard 使用。
`SummaryWriter` 类提供了一个高级 API,用于在给定目录中创建事件文件,并向其中添加摘要和事件。 该类异步更新文件内容。 这允许训练程序调用方法以直接从训练循环将数据添加到文件中,而不会减慢训练速度
具体使用例如绘制一个y=2x图像:
From torch.utils.tensorboard import SummaryWriter //创建实例 writer = SummaryWriter("log") //writer.add_image()
//y=2x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()
1.add_scalar()方法的使用
作用在于:給summary中添加scalar数据
参数有:tag(String):相当于图表标题,scalar_value(float or String/blobname):Value to save 相当于图表y轴,global_step(int):Global step value to record 相当于图表的横坐标
遇到的问题:爆出错误,版本低,需要安装tensorboard,
安装tensorboard:1.打开anaconda Prompt黑窗口,2.进入pytorch环境(conda activate pytorch,3.使用pip install tensorboard进行安装。4.安装成功
运行文件,会出现一个Logs文件夹下带有一个新文件。
如何打开这个文件==》步骤如下:在pycharm控制台输入tensorboard --logdir=logs --port=6007
注意:当你修改了绘图的x,y轴关系时候,重复的写入,会造成图像的混乱,解决办法:每当训练一个新的模型,就把以往的文件删除;或者官方給的解决办法,可以在此基础上创建一个新的文件夹。
2.add_image()方法的使用
作用在于:給summary中添加image数据
参数有:tag(String):相当于图表标题,img_tensor(torch.Tensor, numpy.array, or string/blobname):Image data,global_step(int):Global step value to record 相当于图表的横坐标
使用numpy对图片进行转换,将图片转换成为numpy类型
具体步骤如下:
import numpy as np from PIL import Image writer = SummaryWriter("logs") image_path = "data/train/ants_image/0013035.jpg" img_PIL = Image.open(image_path) img_array = np.array(img_PIL) print(type(img_array)) print(img_array.shape) writer.add_image("test", img_array, 1, dataformats= 'HWC')
从PIL到numpy,需要在add_image()中指定shape中每一个数字/维表示的含义
torchvision中的transforms
1.transforms的结构及用法
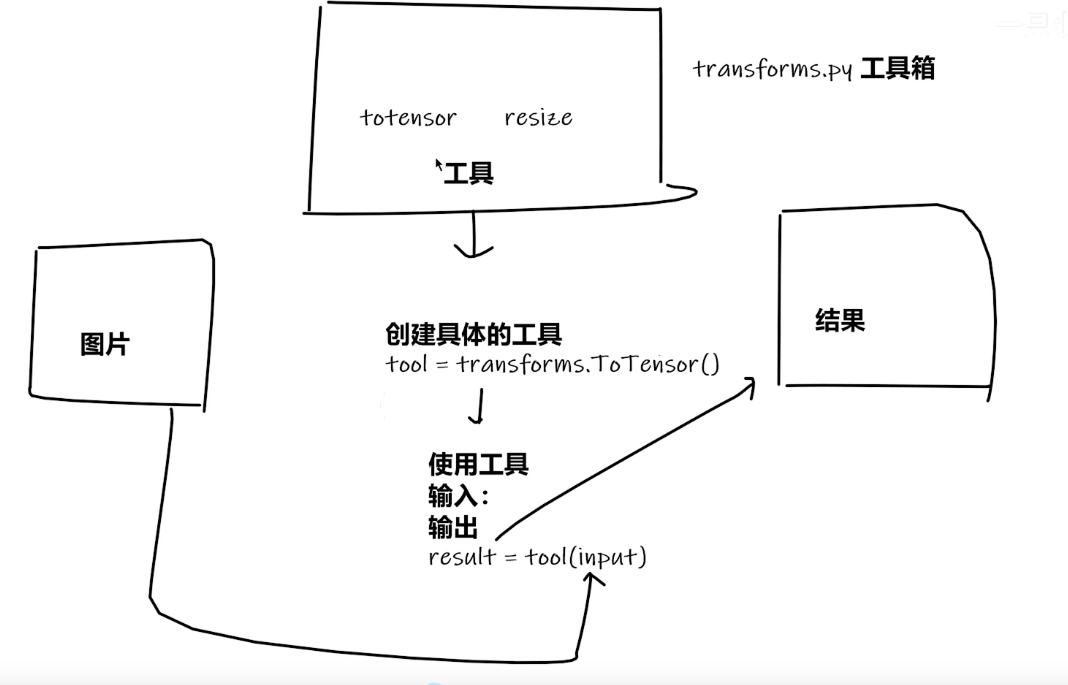
2.transforms该如何使用(python)
from PIL import Image from trochvision import transforms img_path = "dataset/train/ants_image/0013035.jpg" img = Image.open(img_path) //transforms该如何使用(python) tensor_trans = transforms.ToTensor() tensor_img = tensor_trans(img) print(tensor_img)
3.为什么我们需要使用Tensor数据类型
包装了我们神经网络所需要的一些参数
numpy.ndarray类型使用opencv来进行处理
常见的tranforms
有三种输入
1.PIL 使用python自带的Image.open()
2.tensor 使用Totensor()
3.narray 使用opencv的cv.imread()
python中_call_的用法
class Person: def __call__(self, name): printf("__call__"+"hello"+ name) def hello(self,name): print("hello"+ name) person = Person() person("zhangsan") person.hello("lisi")
ctrl加p获取提示,看函数里需要什么参数
对__call__的理解就是说我们可以通过将参数直接放入类的构造函数中进行调用,
Totensor的使用通过方法Totensor()将一个PIL数据类型的图片转换成为了一个tensor数据类型的图片
通过Normalize()将数据进行归一化处理,
Resize()的使用
修改PIL类型图片的大小,如果所给参数是(h,w),那就会按等比例对图片进行缩放,如果所给参数是一个,就会按照最短边进行一个等比缩放
Compose()用法
Compose()中的参数需要的是一个列表,python中,列表的表示形式为[数据1,数据2,....]
在Compose中,数据需要的是transforms类型,所以得到,Compose([transforms参数1,transforms参数2])
RandomCrop()用法
from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import tranforms writer = SummaryWriter("logs") img = Image.open("images/pytorch.png") print(img) #ToTensor trans_totensor = transforms.ToTensor() img_tensor = trans_totensor(img) writer.add_image("ToTensor",img_tensor)
#Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,2)
#Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
#Img PIL ->resize->img_resize PIL
img_resize = trans_resize(img)
#img_resize PIL ->totensor->img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
print(img_resize)
#Compose -resize -2
trans_resize_2 = transforms.Resize(512)
#PIL ->PIL ->tensor
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1)
#RandomCrop
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()
总结用法
使用transforms,首先,关注输入和输出类型,其次,多看官方文档。关注方法需要什么参数即可。
不知道返回值的时候,
*print,*print(type()),*debug
核心:看pytorch官网
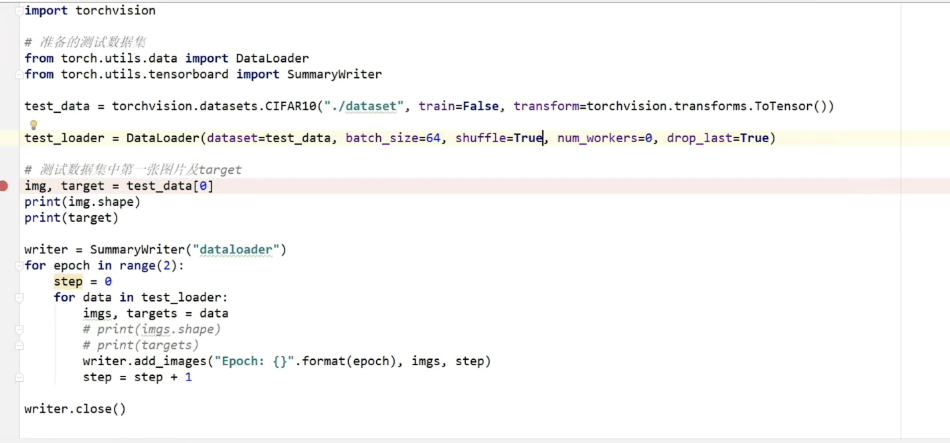
torchvision中的数据集使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #此时采用的是datasets下的CIFAR10数据集 train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set",img,i)
dataset就相当于一副扑克牌,里面放有各种我们所需要的扑克牌。
dataloader数据加载器将数据加载到我们的神经网络当中去。dataloader所做的事情就是每次从dataset中取牌(数据),怎么取,取几张,取决于dataloader中的参数。(看官网)
网络的搭建
Pytorch--->打开官方文档Pytorchl,所有pytorch中的神经网络信息包装在torch.nn类的下面。
torch.nn。nn是指Neural network的缩写。
对于神经网络的搭建。主要在于torch.nn下的Containers中。Containers下的Module中。官网的样例如下:

class Model(nn.Module)相当于继承Module类,规定必须写__init__()和forward()方法。
__init__是初始化函数。而forward()就相当于神经网络对所接收进来的数据进行各种运算,统称为forward()
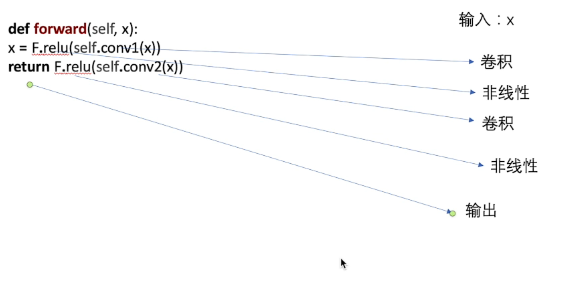
例子如下:
卷积操作--神经网络中基本神经结构的使用。Convolution Layers
CONV2D
参数如下:

stride:指的是每次卷积核在输入图像上走的步长,一步走多长。
逻辑解释类似于
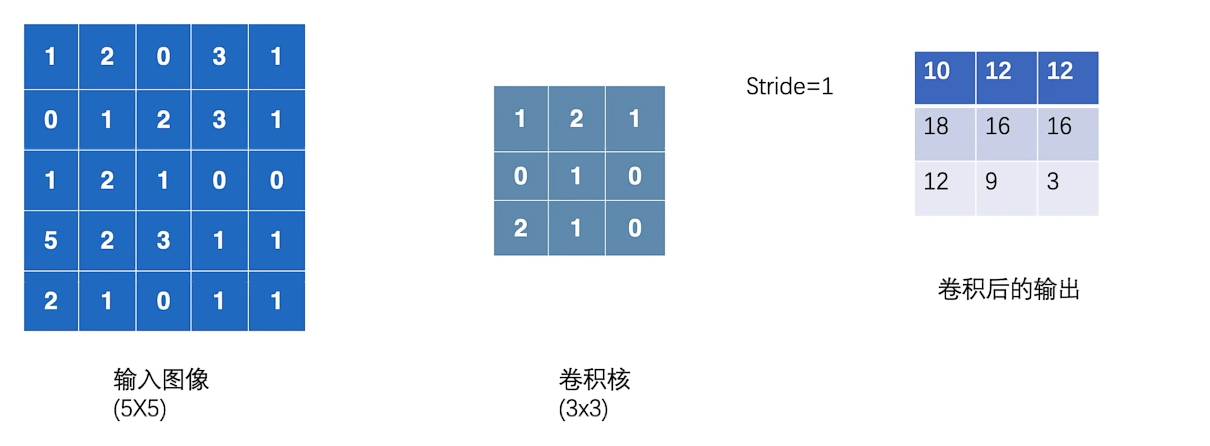
卷积核随机初始化,网络训练的就是卷积核。
input = torch.tensor([[1,2,0,3,1], [0,1,2,3,1], [1,2,1,0,0], [5,2,3,1,1], [2,1,0,1,1]]) #卷积核 kernel = torch.tensor([[1,2,1], [0,1,0], [2,1,0]]) #由于input与kernel的类型(shape)不是四维的,不符合conv2d的数据类型要求,因此需要修改类型,所以要用到,torch的reshape方法。 input = torch.reshape(input,(1,1,5,5)) kernel = torch.reshape(kernel,(1,1,3,3)) print(input.shape) print(kernel.shape) output = F.conv2d(input,kernel,stride=1) print(output)
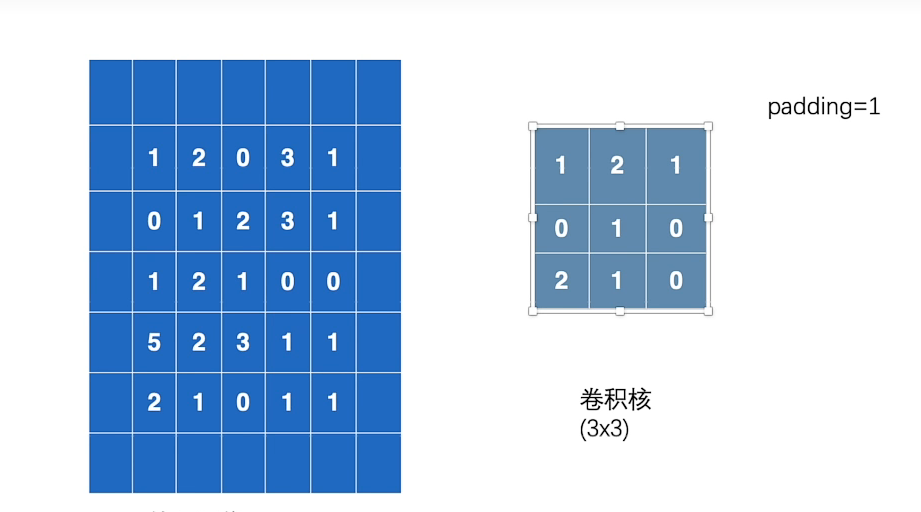
padding的使用
神经网络---卷积层的使用
打开官网---->pytorch--->DOCS-->torch.nn-->Convolution Layers
nn.Conv1d(一维卷积),依次类推。
文章主要以跟学视频中的所举Conv2d为例

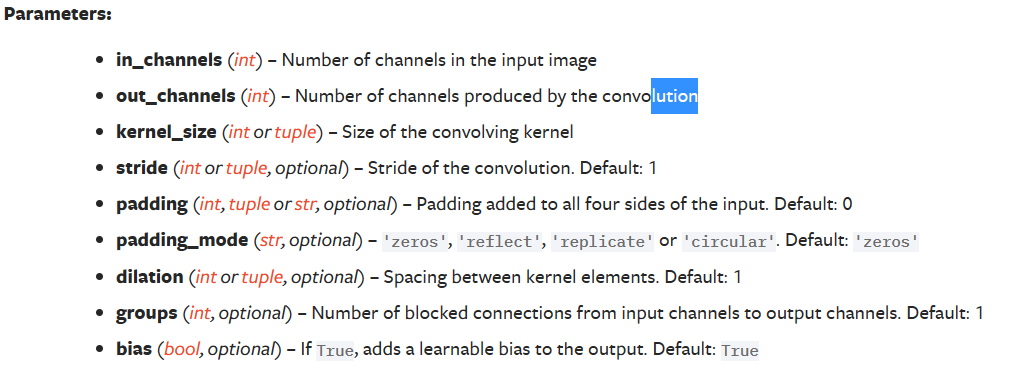
参数说明:
in_channels:你输入的通道数--int
out_channels:输出的通道数--int
kernel_size:卷积核的大小--int 或者tuple
stride:卷积的过程中路径的大小
padding:卷积过程中的一个选项
dilation:卷积核的一个对应位
groups=1:如果改动,就叫做分布卷积。
bias:常年设置为true,就是说我们是否对卷积的结果进行一个加减常数
padding_mode:指我们设置padding之后,会选择咋样的padding模式。
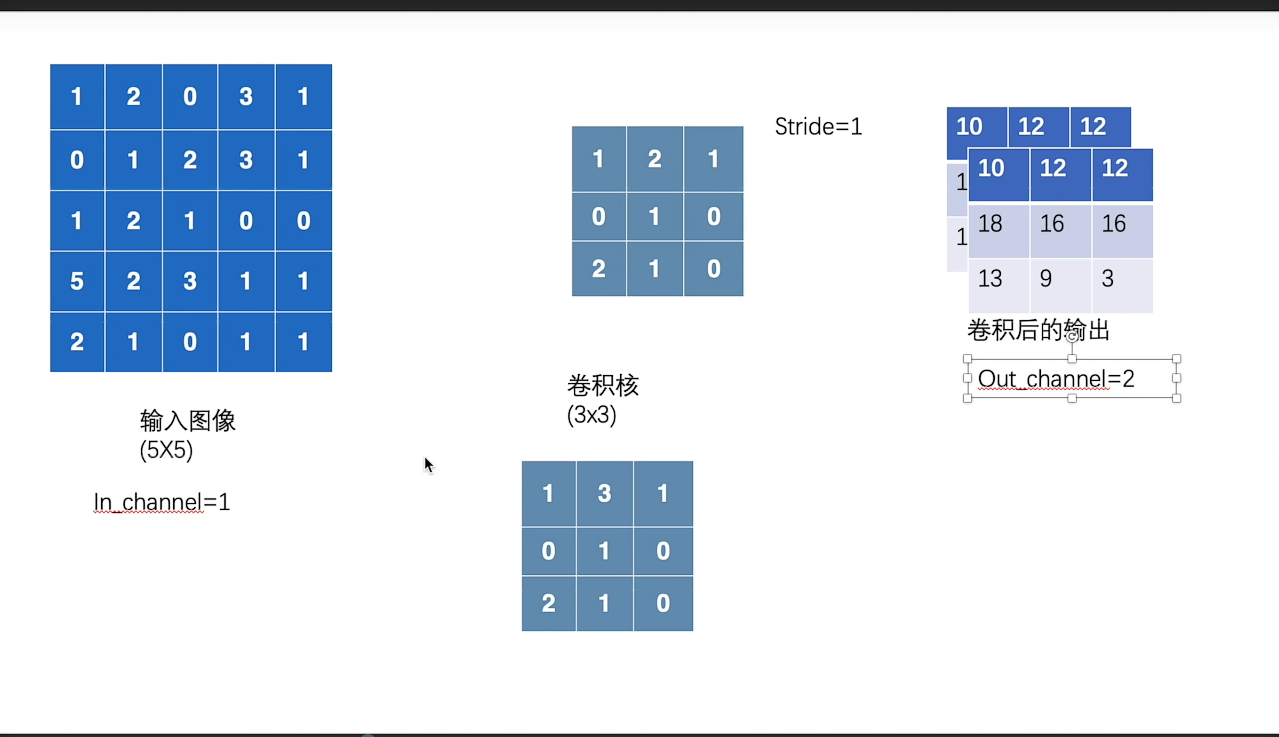
关于in_channels, 与out_channels的理解补充:
in_channels为1的时候,他的输入图像只有一个,当out_channels为1的时候,它会产生一个卷积核,对输入图像数据进行卷积操作;
同样道理,当out_channels为2的时候,它会产生两个卷积核,分别对输入图像数据进行卷积操作,产生两个矩阵,合起来作为卷积的输出。如下图所示:
conv2d二维卷积示例代码
如下:
import torch import torchvision #数据集的下载 dataset = torchvision.dataset.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=False)
#dataloader
dataloader = DataLoader(dataset,batch_size=64)
#编写神经网络
class Cy(nn.Moudle):
def __init__(self):
super(cy,self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6,kernel_size=3.stride=1,padding = 0)
def forward(self, x):
x = self.conv1(x)
return x
#真正创造一个神经网络
cy = Cy()
pirint(cy)
#对dataLoader中的数据进行卷积操作
for data in dataLoader:
imgs, targets = data
output = cy(imgs)
print(output)

神经网络名称叫做Tudui,里面有个卷积层名称叫做conv1,
神经网络----最大池化的使用
打开官方文档,打开DOCS---Torch--torch.nn--Pooling layers(池化层)
nn.MaxPool2d(最大池化)--也被称为下采样。---最常用
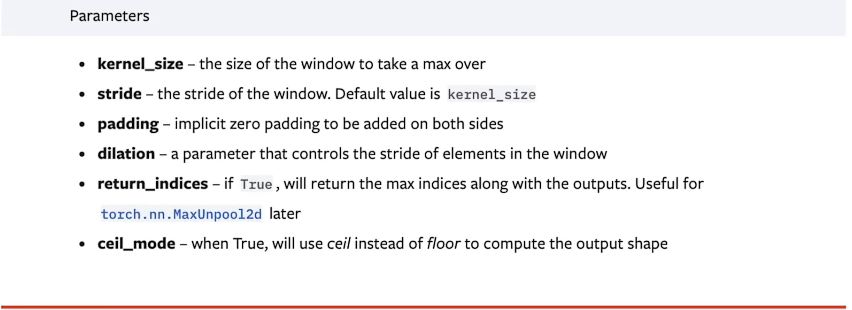
ceil_mode:当它为true的时候,会使用ceil(天花板)就是向上取整,比如2.3会取成3;换句话说就是它会对数据进行保留,即使它不满足.
使用floor就是向下取整,比如2.3会取成2.对多出来的数据不会进行保留。
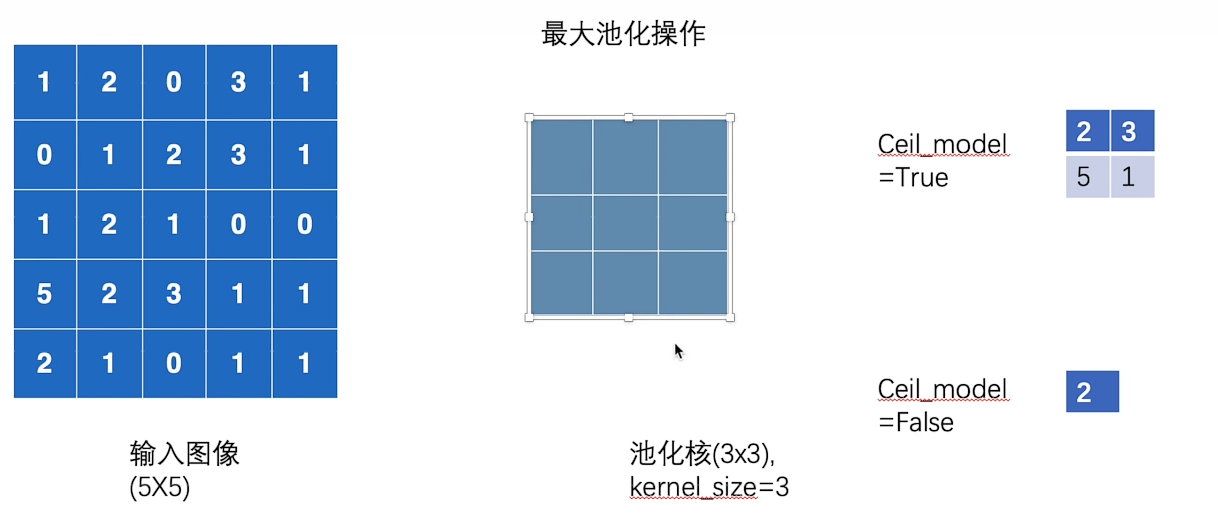
最大池化代码示例:
nn_maxpool
import torch from torch import nn from torch.nn import MaxPool2d #二维矩阵,就使用两个方括号,直接按照图像所示进行输入 input = torch.tensor([[1,2,0,3,1] [0,1,2,3,1] [1,2,1,0,0] [5,2,3,1,1] [2,1,0,1,1] ],dtype=torch.float32) #利用reshape函数,进行形式改变 input = torch.reshape(input, (-1,1,5,5)) print(input.shape)
//从网络上下载数据集
dataset = torchvision.dataset.CIFAR10("../data",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataLoader = DataLoader(dataset,batch_size=64) #神经网络的搭建 class Tudui(nn.Module): def __init__(self): #固定写法,继承存在的声明函数 super(Tudui,self).__init__() #最大池化操作 self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True) def forward(self, input): output = self.maxpool1(input) return output #创建神经网络 tudui = Tudui() #利用TensorBoard,描写日志
writer = SummaryWriter("../logs_maxpool")
for data in dataLoader:
imgs, target = data
writer.add_images("input",imgs,step)
output = tudui(imgs)
writer.add_images("output",output.step)
为什么要最大池化,最大池化的作用在哪?
相当于将1080p的视频变成了720p的视频,既保留了视频数据特征,但减少了数据量,文件尺寸会大大缩小。
神经网络-非线性激活
打开官网Pytorch-打开DOCS-pytroch-torch.nn--Non-liner- Activations
举例:nn.RELU
import torch from torch import nn from torch.nn import ReLU #数据集下载
dataset = torchvision.dataset.CIFAR10("./data",train=False,download=True,transform=torchvision.transforms.ToTensor()) dataLoader = DataLoader(dataset,batch_size=64) class Tudui(nn.module): def __init__(self): super(Tudui,self).__init__() self.relu1 = RELU()
self.sigmoid1 = Sigmoid()
def forward(self,input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("../logs_relu")
step = 0
for data in dataLoader:
imgs,targets = data
writer.add_images("input",imgs,global_step=step)
output = tudui(imgs)
writer.add_images("output",output,global_step=step)
神经网络-线性层及其他层介绍
Recurrent layers-循环层--用于文字识别情况中。
Transformer Layers-变压器层---目标检测
Linear Layers-线性层
Linear Layers-线性层示意图
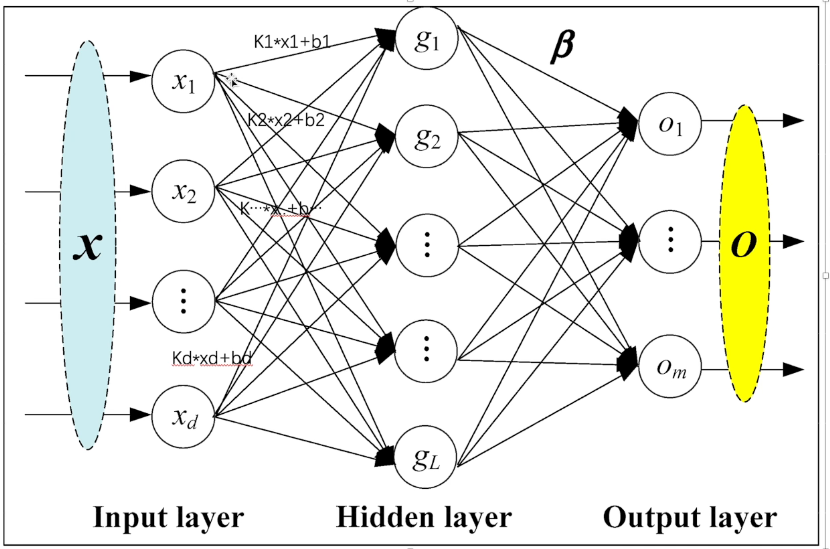
weight相当于k,bias相当于b

CIFAR-10model结构
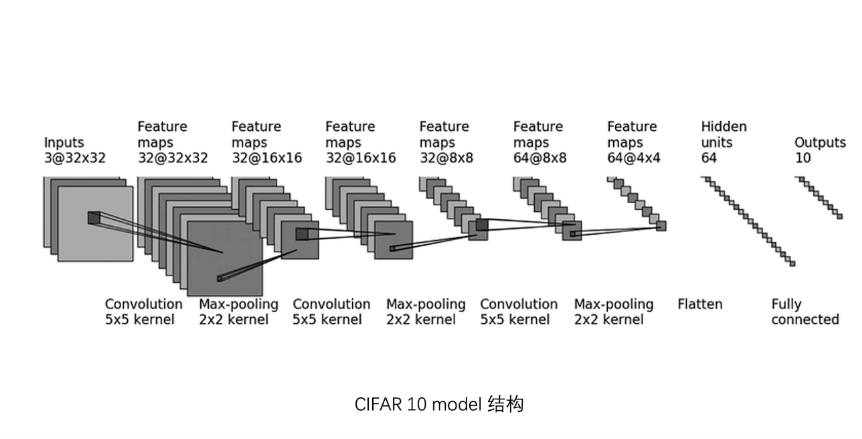
nn_seq_CIFAR代码示意图:
from torch import nn class Cy(nn.module): def __init__(self): super(Cy,self).__init__() self.model1 = Sequential( Conv2d(3,32,5,padding=2) MaxPool2d(2) Conv2d(32,32,5,padding=2) MaxPool2d(2) Conv2d(32,64,5,padding=2) MaxPool2d(2) Flatten() Linear(1024,64) Linear(64,10) ) def forward(self, x): x = self.model1(x) return x cy = Cy() print(cy) input = torch.ones((64,3,32,32))
output = cy(input)
print(output.shape)
writer = SummaryWriter("../logs_seq")
writer.add_graph(cy,input)
writer.close()
损失函数与反向传播torch.nn里面的Loss Functions
Loss Functions的含义:举例说明:我们的一张卷子,满分100分,分为选择30,填空20,解答50.我们实际考的分数为选择10,填空10,解答10;而Loss Functions就是用来帮助我们进行计算二者之间的误差。

也就是指经过神经网络模型后,output与我们的target之间的误差,误差越小结果越好。根据Loss来提高我们的神经网络模型。
1.计算实际输出和目标之间的差距。
2.为我们更新输出提供一定的根据(反向传播backward)
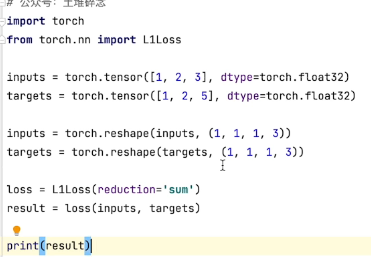
交叉熵(CROSSENTROPYLOSS)通常用来解决伴随多种类别的分类问题-----比较难理解,有点绕
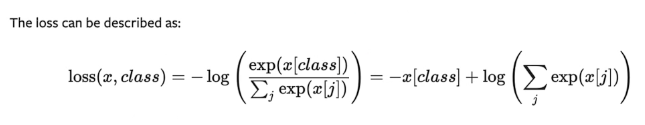
举例子如下:
x = torch.tensor([0.1,0.2,0.3]) y = torch.tensor([1]) #因为x的类别与交叉熵的input输入形式不同,所以使用reshape函数进行修改 x = torch.reshape(x,(1,3)) #新建交叉熵 loss_cross = nn.CrossEntropyLoss() result_cross = loss_cross(x,y) print(result_cross)
利用交叉熵建立了神经网络例子:
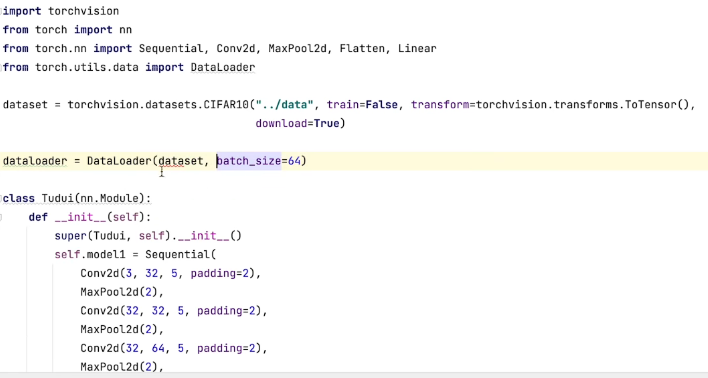
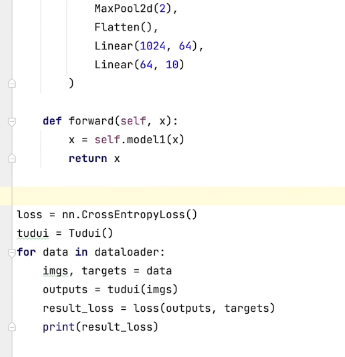
反向传播:給每一个卷积核的参数设置了一个grad(梯度),每次优化,根据梯度进行参数优化,最终loss降低。具体使用:result__loss.backward()
梯度下降:
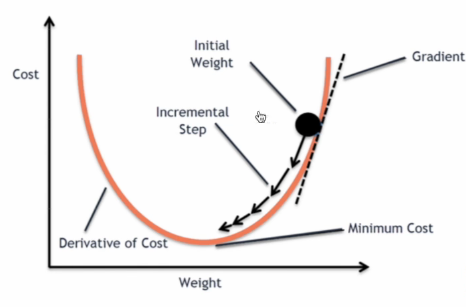
优化器
集中在torch.optim

optim.SGD是每个优化器的算法,其中的参数需要放入模型的参数,lr(学习效率),momentum.
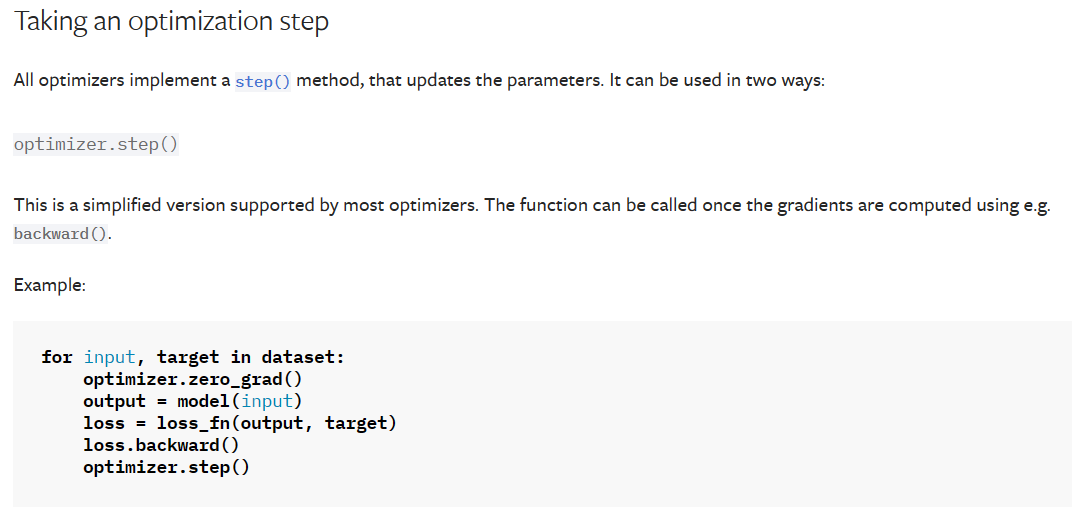
对dataset中的数据进行遍历,1.对优化器中的梯度进行清零,2.输入的数据经过model后,获得输出数据output,3.使用loss_fn函数计算output与target之间的误差,4.进行反向传播,5.进行优化器的step方法。
具体示例如下:
import torchvision from torch import nn from torch.nn import Sequential,Conv2d,MaxPool2d,Flatten,Linear from torch.utils.data import DataLoader dataset = torchvision.dataset.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True) dataLoader = DataLoader(dataset,batch_size=1) class Cy(nn.Module): def __init__(self): super(Cy,self).__init__() self.model1 = Sequential( Conv2d(3,32,5,padding=2), MaxPool2d(2), Conv2d(32,32,5,padding=2), MaxPool2d(2), Conv2d(32,64,5,padding=2), MaxPool2d(2), Flatten(), Linear(1024,64), Linear(64,10) ) def forward(self,x): x=self.model1(x), return x loss = nn.CrossEntropyLoss() cy = Cy() optim = torch.optim.SGD(cy.parameters(),lr=0.01) for epoch in range(20): running_loss =0.0 for data in dataLoader: imgs, tragets = data outputs = cy(imgs) result_loss = loss(outputs,targets) optim.zero_grad() result_loss.backward() optim.step() running_loss = running_loss +result_loss.data print(running_loss)
现有网络模型的使用及修改
与图像相关的torchvision,打开torchvision--->打开torchvision.models
例子:数据集为torchvision.dataset.CIFAIR10,所以使用torchvision.models中的VGG模型

当pretrained为true的时候,说明模型中已经有训练好的数据集。如果为false,就说明是初始化的参数,没有进行任何的训练。
当progress为true的时候,会显示一个下载进度条
数据集的下载:找到torchvision.dataset
示例如下:
import torchvision vgg16_false = torchvision.models.vgg16(pretrained=False) vgg16_true = torchvision.models.vgg16(pretrained=True) print(vgg16_true) train_data = torchvision.dataset.CIFAR10('../data',train=True,transform=torchvision.transforms.ToTensor(),download=True) vgg16_true.add_module('add_linear',nn.Linear(1000,10))
#或者加到classfier下面
#vgg16_true.classfier.add_module('add_linear',nn.Linear(1000,10)) print(vgg16_true)
#修改vgg16_false最后一行
vgg16_false.classfiter[6] = nn.Linear(4096,10)
print(vgg16_false)

网络模型的保存和修改
model_save.py-----模型保存文件
import torch import torchvision vgg16 = torchvision.models.vgg16(pretrained=False) #保存方式1,这种方式不仅保存了模型结构,还保存了网络模型参数 torch.save(vgg16, "vgg16_method1.pth")
#保存方式2,把模型中的参数保存成了python中的字典形式(官方推荐,模型参数)
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
#陷阱
class Cy(nn.Module):
def __init__(self):
super(Cy,self).__init__()
self.conv1 = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x):
x = self.conv1(x)
return x
cy = Cy()
torch.save(cy, "tudui_method1.pth")
model_load.py-----模型加载文件
import torch from model_save import * #方式1-->保存方式1,加载模型 load的参数为文件路径。 model1 = torch.load("vgg16_method1.pth") print(model1)
#方式2--->加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
#model2 = torch.load("vgg16_method2.pth")
#print(vgg16)
#陷阱1
#class Cy(nn.Module):
# def __init__(self):
# super(Cy,self).__init__()
# self.conv1 = nn.Conv2d(3,64,kernel_size=3)
# def forward(self,x):
# x = self.conv1(x)
# return x
model1 = torch.load('tudui_method1.pth')
print(model1)完整的模型训练套路(以CIAR10数据集)
#train.py
import torchvision from model import * #1.准备训练集,并且将其转换为tensor数据类型
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.dataset.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),downLoad=True) #2.准备测试集 test_data = torchvision.dataset.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),downLoad=True) #length长度 train_data_size = len(train_data) test_data_size =len(test_data)
#如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
#利用dataLoader加载
train_dataLoader = DataLoader(train_data,batch_size=64)
test_dataLoader = DataLoader(test_data,batch_size=64)
#创建网络模型
cy = Cy()
#损失函数
#使用交叉熵
loss_fn = nn.CrossEntropyLoss()
#优化器
learning_rate = 0.01
#learning_rate = 1e-2
#1e-2=1 (10)^(-2) = 1 / 100 = 0.01
optimizer = torch.optim.SGD(cy.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10
#添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("----第{}轮训练开始----".format(i+1))
#训练步骤开始
tudui.train()
for data in train_dataLoader:
imgs,targets = data
outputs = tudui(imgs)
#计算误差
loss = loss_fn(outputs,targets)
#开始优化
optimizer.zero_grad()#梯度清0
loss.backward()#反向传播
optimizer.step()#优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#调优,利用现有模型进行测试,测试步骤开始
tudui.eval()
total_test_step = 0
#整体正确的个数
total_accuracy = 0
#测试不需要对梯度进行调整,也不需要利用梯度优化。
with torch.no_grad():
for data in test_dataLoader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == target).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率为:{}"。format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step +1
torch.save(tudui,"tudui_{}.pth".format(i))
#torch.save(tudui.state_dict(),"tudui_{}.pth".format(i))
print("模型已经保存")
writer.close()
如果将搭建神经网络单独拎出来,示例代码如下:
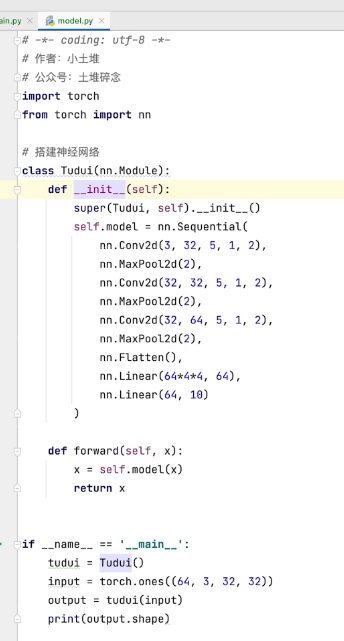

如果是两个分类,outputs为tensor数据类型,
举例:
outputs = torch.tensor([[0.1,0.2],
[0.05,0.4]])
print(outputs.argmax(1))
将outputs利用argmax进行转换,当argmax中的参数为1时候,判断横向的大小序号,即:[1][1]
当argMax中的参数为0的时候,判断竖向的大小序号,即:[0][1]

可以计算出对应位置相等的个数
如何利用GPU进行训练
GPU有两种训练方式
下面进行第一种的示例代码:
#train_gpu_1.py #具体内容包括:网络模型,数据(输入、标注),损失函数,然后调用.cuda()即可。
#1.准备训练集,并且将其转换为tensor数据类型
from torch import nn
from torch.utils.data import DataLoader
#定义训练的设备
device = torch.device("cpu") train_data = torchvision.dataset.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),downLoad=True) #2.准备测试集 test_data = torchvision.dataset.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),downLoad=True) #length长度 train_data_size = len(train_data) test_data_size =len(test_data)
#如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
#利用dataLoader加载
train_dataLoader = DataLoader(train_data,batch_size=64)
test_dataLoader = DataLoader(test_data,batch_size=64)
#创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2)
nn.MaxPool2d(2)
nn.Conv2d(32,32,5,1,2)
nn.MaxPool2d(2)
nn.Conv2d(32,64,5,1,2)
nn.MaxPool2d(2)
nn.Flatten()
nn.Linear(64*4*4,64)
nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
tudui = Tudui()
#if torch.cuda.is_available():
#tudui = tudui.cuda()
tudui = tudui.to(device)
#损失函数
#使用交叉熵
loss_fn = nn.CrossEntropyLoss()
#if torch.cuda.is_available():
#loss_fn = loss_fn.cuda()
loss_fn = loss_fn.to(device)
#优化器
learning_rate = 0.01
#learning_rate = 1e-2
#1e-2=1 (10)^(-2) = 1 / 100 = 0.01
optimizer = torch.optim.SGD(cy.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10
#添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("----第{}轮训练开始----".format(i+1))
#训练步骤开始
tudui.train()
for data in train_dataLoader:
imgs,targets = data
#if torch.cuda.is_available():
#imgs = imgs.cuda()
#targets = targets.cuda()
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
#计算误差
loss = loss_fn(outputs,targets)
#开始优化
optimizer.zero_grad()#梯度清0
loss.backward()#反向传播
optimizer.step()#优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#调优,利用现有模型进行测试,测试步骤开始
tudui.eval()
total_test_step = 0
#整体正确的个数
total_accuracy = 0
#测试不需要对梯度进行调整,也不需要利用梯度优化。
with torch.no_grad():
for data in test_dataLoader:
imgs, targets = data
#if torch.cuda.available():
#imgs = imgs.cuda()
#targets = targets.cuda()
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == target).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率为:{}"。format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step +1
torch.save(tudui,"tudui_{}.pth".format(i))
#torch.save(tudui.state_dict(),"tudui_{}.pth".format(i))
print("模型已经保存")
writer.close()
完整的模型验证(测试、demo)套路-利用已经训练好的模型,然后給它提供输入。
首先,寻找一张网络上的图片,将他进行本地保存。
然后,进行test.py的编写
import torchvison from PIL import Image image_path = "../imgs/dog.png" image = Image.open(image_path) print(image) transform = torchvision.transforms.Compose([torchvision.transforms.Resize(*(32,32)),torchvision.transforms.ToTensor()]) image = transform(image) print(image.shape)
#创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2)
nn.MaxPool2d(2)
nn.Conv2d(32,32,5,1,2)
nn.MaxPool2d(2)
nn.Conv2d(32,64,5,1,2)
nn.MaxPool2d(2)
nn.Flatten()
nn.Linear(64*4*4,64)
nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
#加载已经训练好的网络模型
model = torch.load("tudui_0.pth")
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with.torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
学习开源项目
将基础配置中的require中的项进行删除,然后修改成为default="./dataset/maps",就可以运行。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号