
tensorflow实现resnet
先学习下如何自己完成一个resnet网络用于cifar100训练,后面在使用迁移学习训练。
如果不知道resnet具体的网络结构可以自己学习下,这里只进行实现。
1. BasicBlock实现
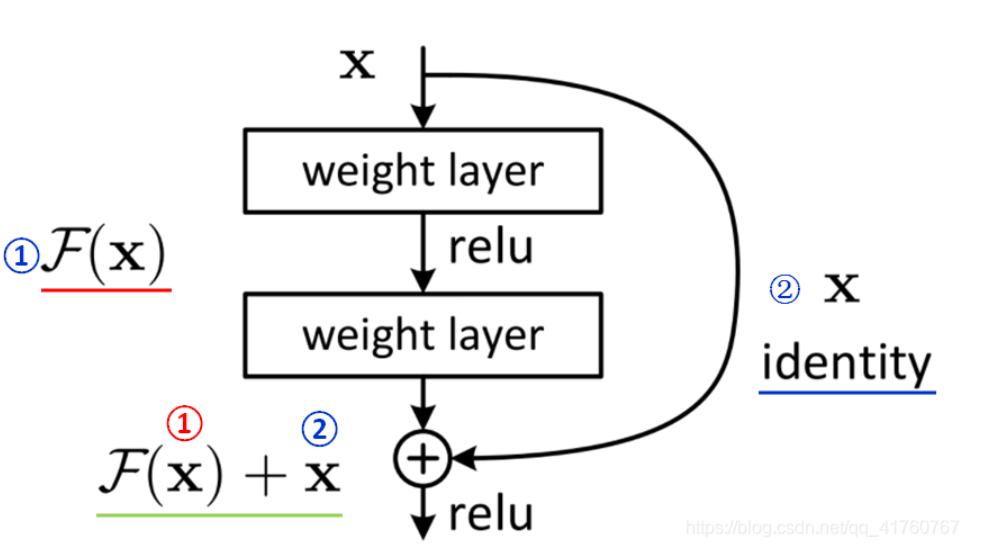
BasicBlock首先是继承layer.Layer
class BasicBlock(layers.Layer):
然后重写里面的init和call方法。
1)先在init定义Basic中的基础操作,由上图我们知道,就是两个Conv2D,如果第1个conv下采样了,第二个就不进行下采样。
这里的下采样指的是stride不等于1的情况。这里每个conv后,有个batchnormal操作,bn操作是会训练一个α和β参数的,
如果不是要共享权值,最好定义两个self.bn{$(num)}。relu层是没有训练的参数的,可以使用相同的,但是为了可以
更清晰的了解网络结构,建议分别定义。
def __init__(self,filter_num,stride):
super(BasicBlock,self).__init__()
self.conv1=layers.Conv2D(filter_num,kernel_size=(3,3),strides=stride,padding='same')
self.bn1=layers.BatchNormalization()
self.relu1=layers.Activation('relu')
self.cov2=layers.Conv2D(filter_num,kernel_size=(3,3),strides=1,padding='same')
self.bn2=layers.BatchNormalization()
self.relu2=layers.Activation('relu')
if stride % 2 != 0:
self.downsample=lambda x:x
else:
self.downsample=Sequential()
self.downsample.add(layers.Conv2D(filter_num,(1,1),strides=stride,padding='same'))
在BasicBlock中call定义调用逻辑,这里逻辑就是先进行第一次conv、bn、relu组合,再进行conv、bn;
另外一个分支就是如果没有进行下采样,返回值就是inputs,否则就进行一次1*1的卷积;
在将两个分支的结果进行相加,再进行一次relu.
def call(self, inputs, training=None):
#input[N.H,W,C]
out=self.conv1(inputs)
out=self.bn1(out)
out=self.relu1(out)
out=self.cov2(out)
out=self.bn2(out)
identity=self.downsample(inputs)
output=layers.add([out,identity])
output=tf.nn.relu(output)
return output
2 实现一个ResBlock
这里要明白一个ResBlock中包含一个或多个BasicBlock
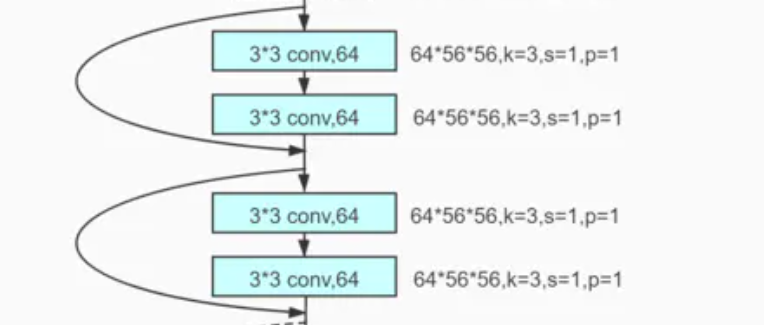
比如这里的由两个BasicBlock组成了一个ResBlock
1)定义一个类RestNet
ResNet继承kears.Model
class Resnet(tf.keras.Model):
2)定义ResBlock方法
def build_resblock(self,filter_num,blocks,stride=1):
res_block=Sequential()
res_block.add(
BasicBlock(filter_num,stride)
)
for _ in range(1,blocks):
res_block.add(BasicBlock(filter_num,stride=1))
return res_block
这里输入为filter_num,就是N,N就是有多少个卷积核,对应输出的c。
第二个参数blocks对应这里包含几个BasicBlock.
第一步,先创建一个容器
第二步,向容器里添加第一个BasicBlock.这里要区别对待,因为一般一个ResBlock只进行一次下采样。
所以剩余的BasicBlock的stride为1。
2)在init方法中定义我们这个网络中会使用的结构
对于每个resnet网络的定义一般会有一个conv,bn加上一个maxpool。这个不算在ResBlock中
self.stm=Sequential([layers.Conv2D(64,kernel_size=(3,3),strides=1,padding='same'),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2,2),strides=1,padding='same')])
然后我们根据我们的网络结构创建resblock比如我们先看左边的resnet18,包含有8个resblock,有降采样的也有没有降采样的。
这里我简单写了个全是降采样的``[2,2,2,2]```的结构
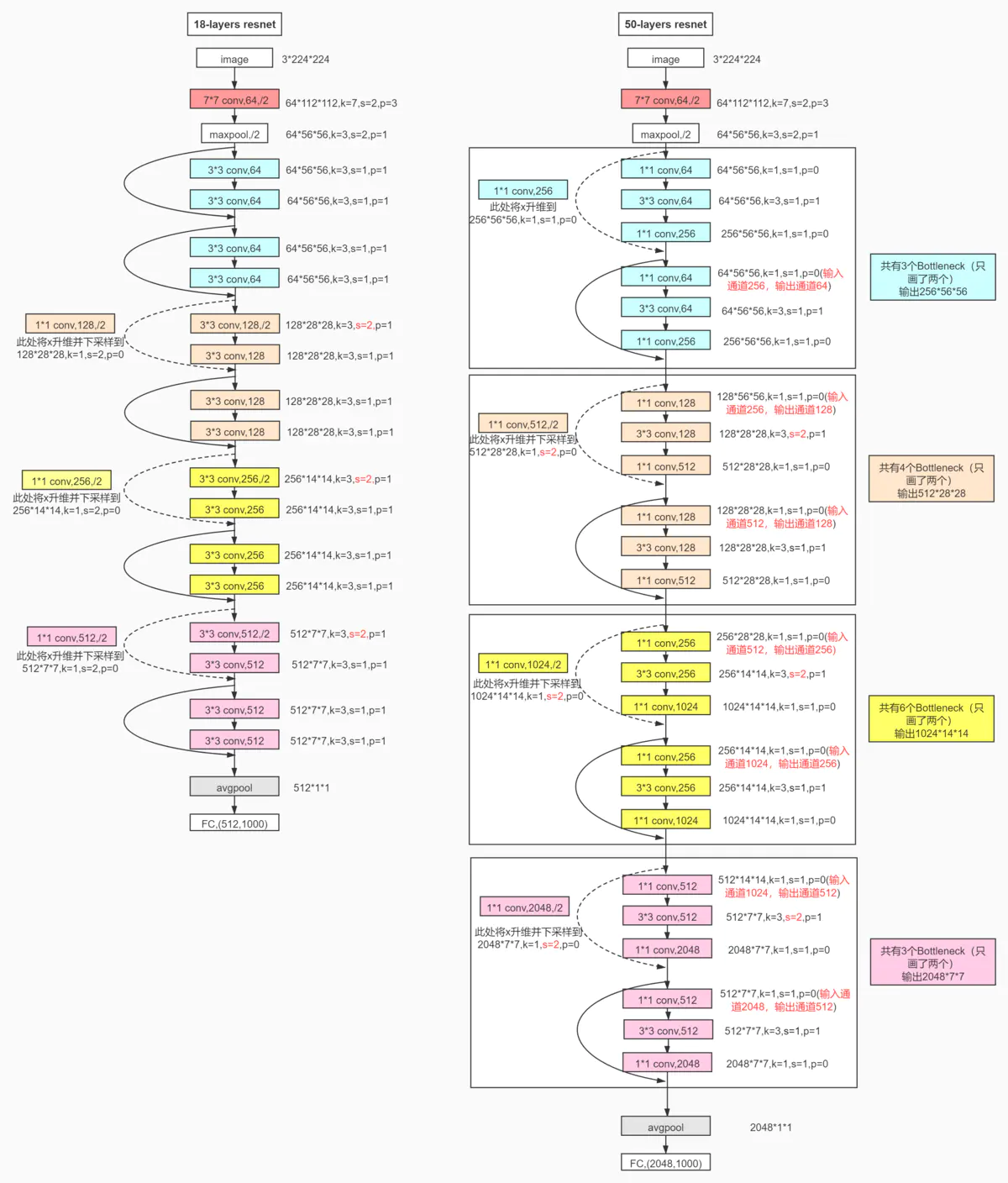
self.layer1=self.build_resblock(64,layer_dim[0])
self.layer2 = self.build_resblock(128, layer_dim[1],stride=2)
self.layer3 = self.build_resblock(256, layer_dim[2],stride=2)
self.layer4 = self.build_resblock(512, layer_dim[3],stride=2)
self.fc=layers.Dense(num_classes)
3)现在是添加全连接层进行分类
这里可以添加多个全连接层也可以只添加一个。
这里还增加了一个
self.avgpool=layers.GlobalAveragePooling2D()
这是因为为了支持自定义网络输入,比如输入图片较大,卷积完成后没有成为[b,N,1,1]的情况,做个全局的AveragePooling,然后再进行分类。
4)在call方法中设置调用逻辑,这段很简单,就是一个拼积木。
def call(self,inputs,training=None):
x=self.stm(inputs)
x=self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x=self.avgpool(x)
x=self.fc(x)
return x
3实现自己的resnet
def MyRest():
return Resnet([2,2,2,2],100)
这里随便怎么定义了。
下面我们使用cifar100进行测试了
1)加载cifar100
def load_data():
(x,y),(x_test,y_test)=datasets.cifar100.load_data();
y=tf.squeeze(y)
y_test=tf.squeeze(y_test)
db=tf.data.Dataset.from_tensor_slices((x,y))
db=db.map(preprocess).shuffle(50000).batch(64)
db_test=tf.data.Dataset.from_tensor_slices((x_test,y_test))
db_test=db_test.map(preprocess).batch(64)
return db,db_test
2)将cifar100进行预处理
def preprocess(x,y):
x=tf.cast(x, dtype=tf.float32)/255.
y=tf.cast(y,dtype=tf.int32)
return x,y
(db,db_test)=load_data()
3)通过我们的刚才定义的网络结构定义网络
network=Resnet.MyRest()
network.build(input_shape=(None, 32,32,3))
4)设置优化器
optimizer=optimizers.Adam(learning_rate=1e-4)
5)开始训练
这里使用交叉熵作为损失函数
for epoch in range(20):
for step,(x,y) in enumerate(db):
with tf.GradientTape() as tape:
out=network(x)
#print("y_one_hot shape",y_onehot.shape)
loss=tf.losses.categorical_crossentropy(y_onehot,out,from_logits=True)
loss=tf.reduce_mean(loss)
greds=tape.gradient(loss, network.trainable_variables)
optimizer.apply_gradients(zip(greds,network.trainable_variables))
if step % 100 == 0:
print('loss:',float(loss))
6)每一个epoch计算一下准确率
total_number=0
correct_number=0
for step,(x,y) in enumerate(db_test):
out=network(x)
y=tf.cast(y,dtype=tf.int32)
prod=tf.nn.softmax(out,axis=1)
pred=tf.argmax(prod,axis=1)
pred=tf.cast(pred,dtype=tf.int32)
correct=tf.reduce_sum(tf.cast(tf.equal(pred,y),dtype=tf.int32))
correct_number += correct
total_number+=x.shape[0]
print("acc:",float(correct_number/total_number))
看看效果
完结
后面 将学习如何使用迁移学习和resnet进行分类。为什么要使用迁移学习?你懂得。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号