

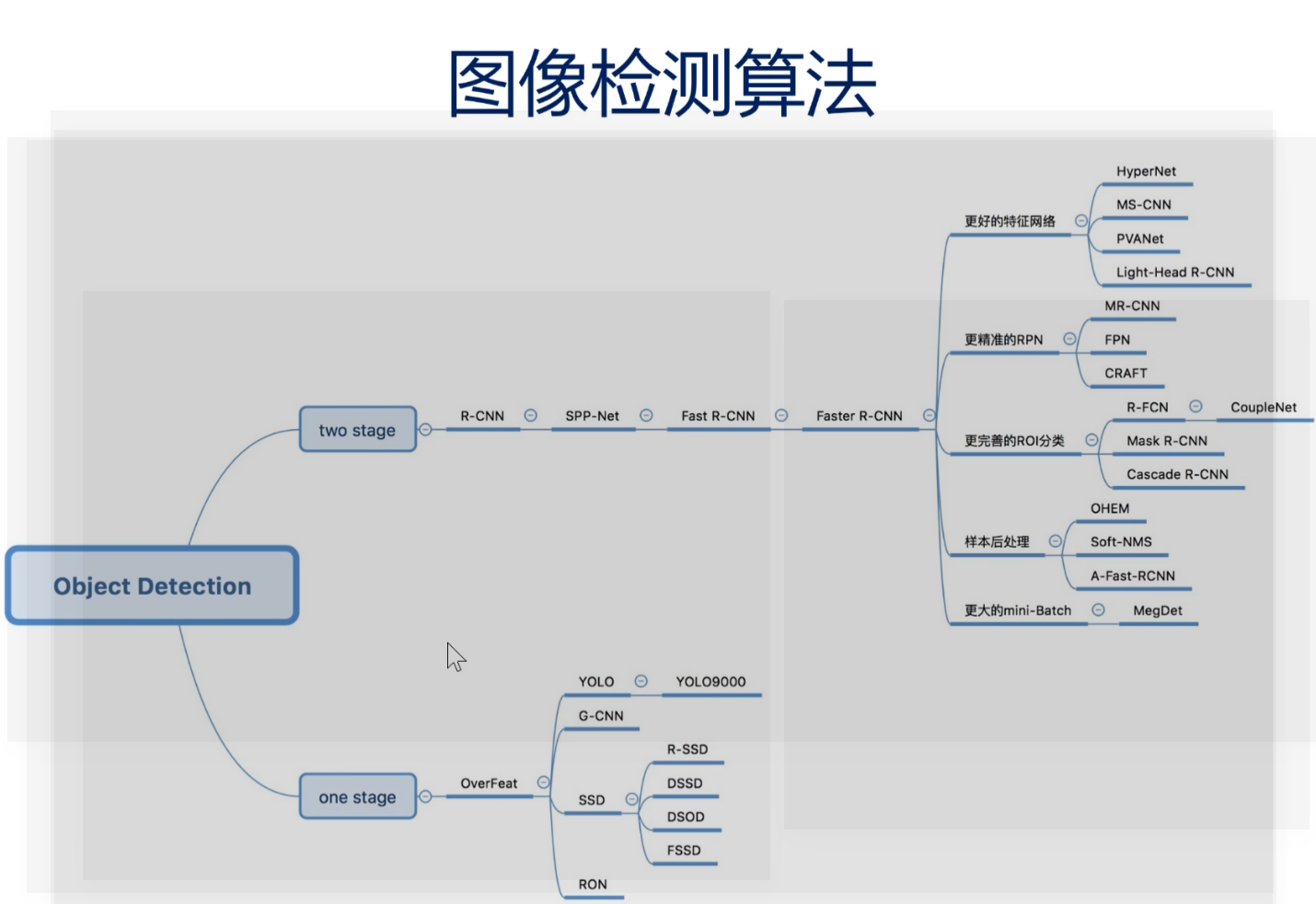
图像检测算法
分类:通常图像分类并没有什么用处,只是得出一张图片里面有什么。
定位+分类:知道图片中有个什么,也把这个物体定位出来了,但是也没啥用,因为日常生活中一张图片中可能有多个物体。
物体检测:做到这一步在实际中就有用处了。

IOU(交并比)
用于衡量定位的准确度, 一般IOU >= 0.5 可认为定位成功。
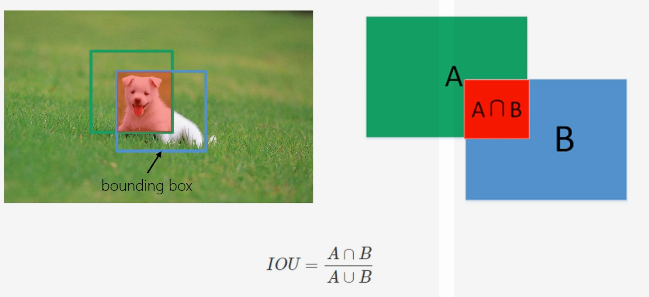
上图中真实的由蓝框标记,红框为算法框出来的。
mAP(mean Average Precision 平均精度均值)
* 用于衡量模型在测试集检测精度的优劣程度。
- 综合考虑召回率和精度,mAP越高表示检测结果越好。
mAP计算原理
- 召回率/查全率(recall):选的N个样本中选对的k个正样本,占总的M个正样本的比例 k/M;
- 精度/查准率(precision):选的N个样本中选对k个正样本的比例 k/N;
选择的样本N越多,召回率越高,查准率越低;

置信度(阈值)越低,选中的样本越多,精度越低,召回率越高。
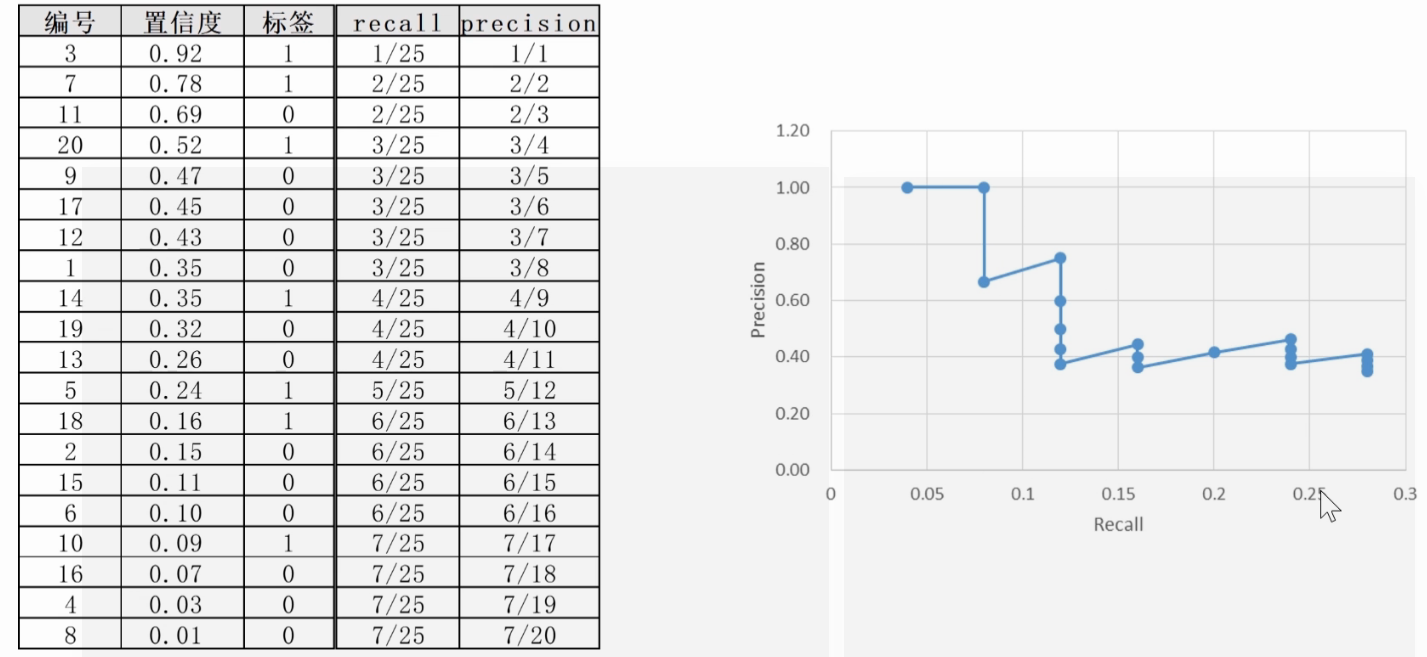
mAP就是计算上图中折线图与坐标轴之间的面积。
Two-stage
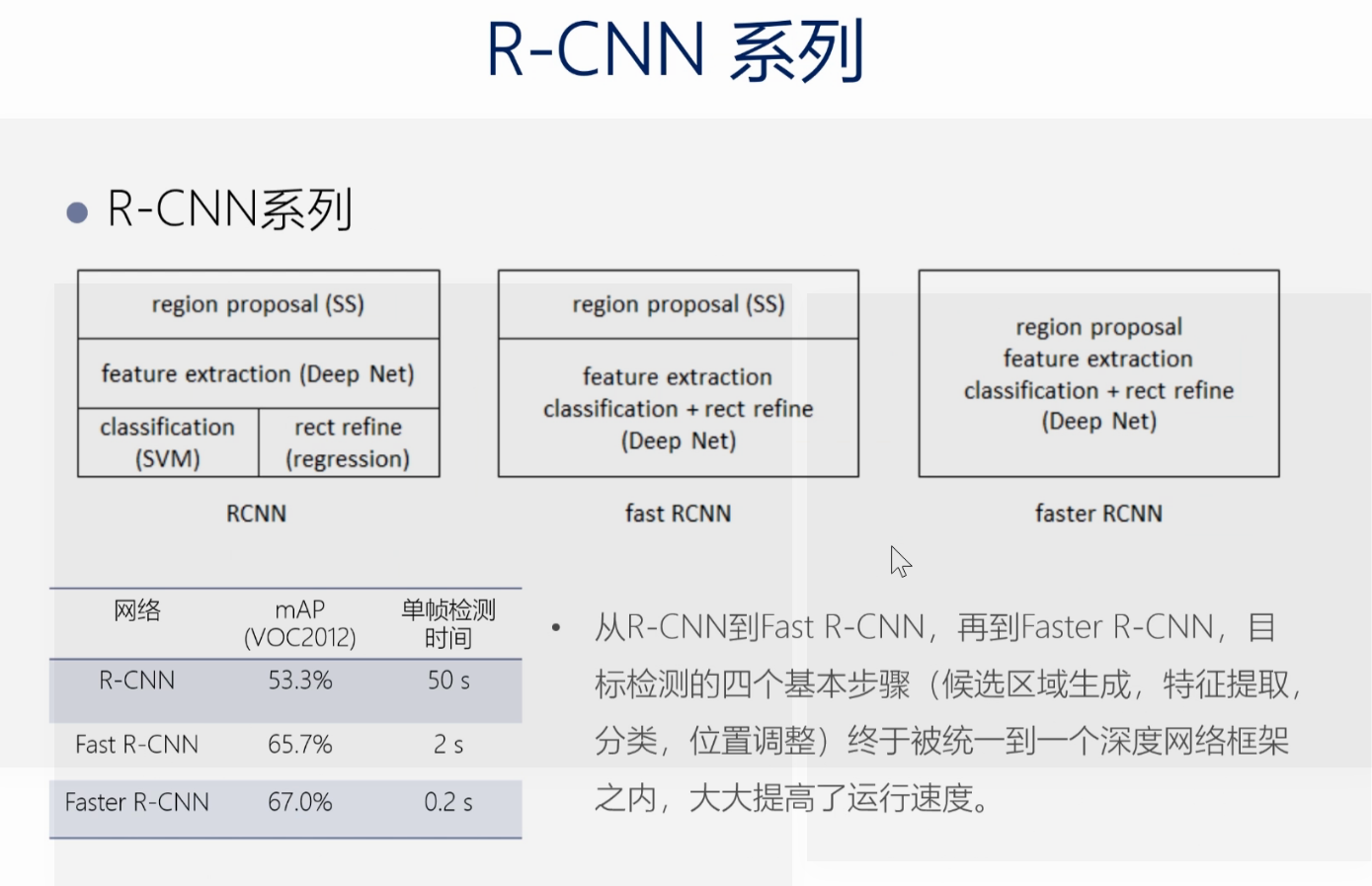
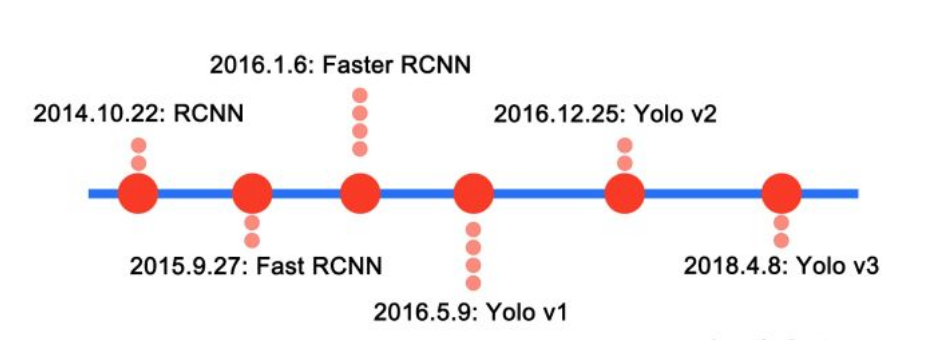
R-CNN系列
R-CNN系列变化的主要特征是将越来越多的部分交給神经网络做。
- R-CNN : Girshick R, Donahue J, Darrell T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C].2014.
- Fast R-CNN:Girshick R, Fast R-CNN[j].Computer Science, 2015
- Faster R-CNN : Ren S, He Km Girshick R,et al. Faster R-CNN:towards real-time object detection with region proposal networks[C], 2015:91-99

R-CNN
R-CNN的主要步骤
- 候选区域提取:使用Selective Search 从输入图片中提取2000个左右的候选区域
- 特征提取: 首先将所有的候选区域裁剪缩放为固定大小,再用AlexNet(5conv + 2FC)提取图像的特征。
- 线性分类: 用特定类别的线性SVMs 对每个候选区域做分类。
* 边界框回归:用线性回归修正边界框的位置与大小,其中每个类别单独训练一个边界框回归器。
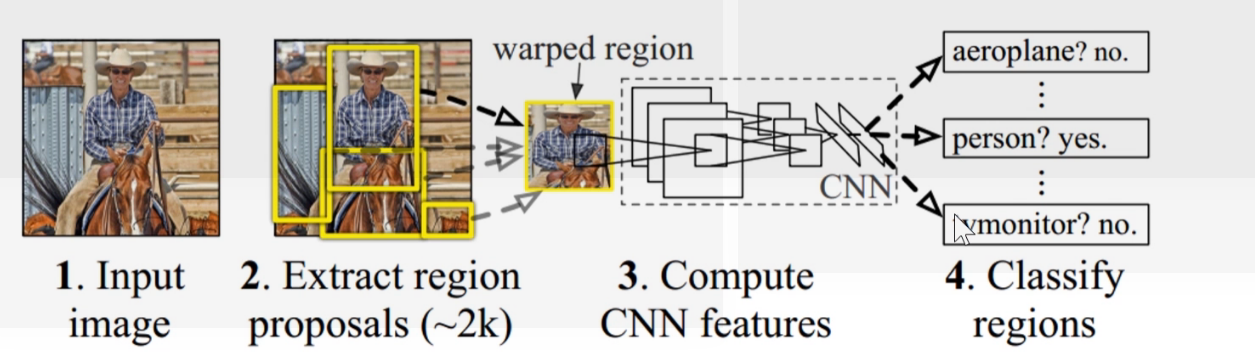
这里只有特征提取用到深度学习。
1.候选区域提取 步骤

- 层次化分组算法
1)用基于图的图像分割方法创建初始区域。
2)计算所有的相邻区域的相似度。
3)每次合并相似度最高的两个相邻的图像区域,并计算合并后的区域与其相邻区域的相似度。重复改过程,直到所有的图像合并
成一张完整的图像。
(前面的三步是不是聚类的操作)
4)提取所有图像区域的目标位置框,并按层级排序(覆盖整个图像的区域的层级为1)。 - 在不同图像分割阈值、不同色彩空间、以及不同的相似度(综合考虑颜色、纹理、大小、重叠度)下。调用层次化分组算法,对所有合并策略下得到的位置框按层级*RND排序,去掉冗余框。
- 取一定个数的候选区域作为后续卷积神经网络的输入。(R-CNN取2000个)。
NMS(非极大值抑制 Non-Maximum Suppression) 用于去掉冗余选框。

分类与回归
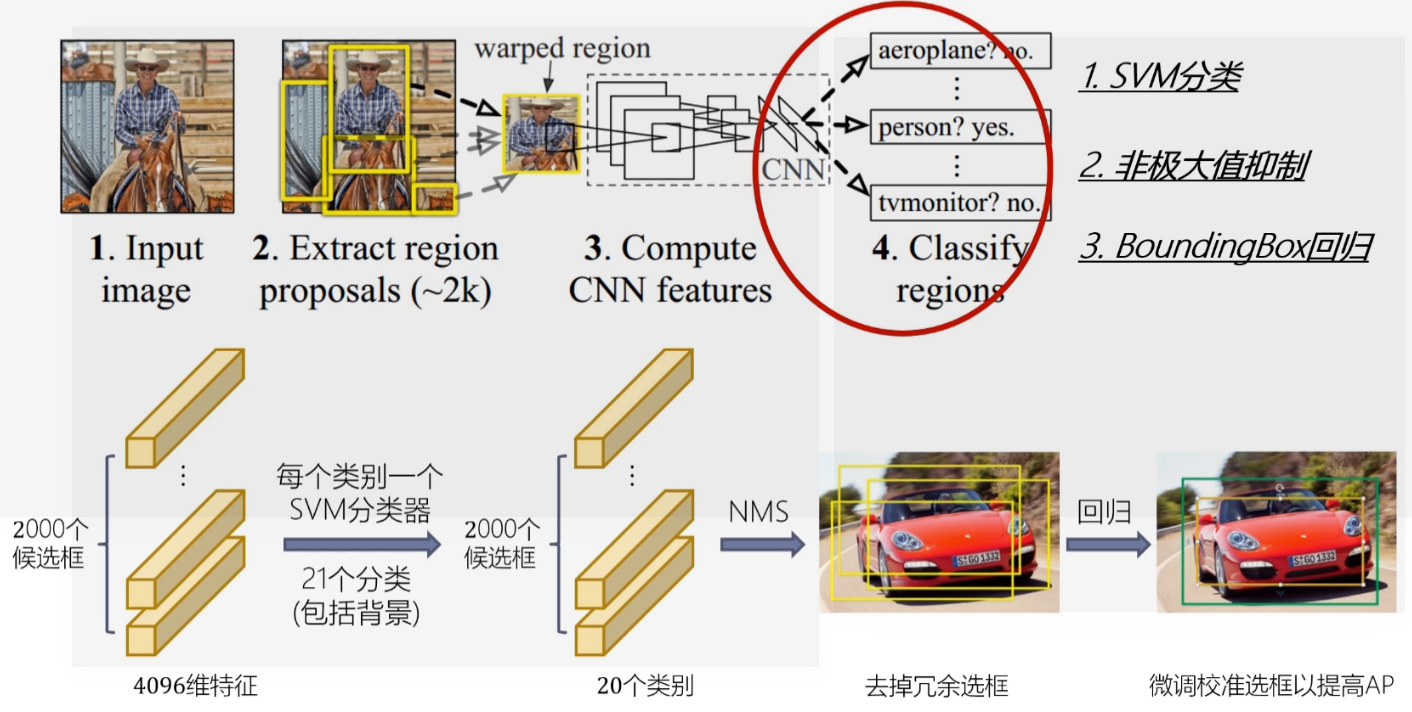
2000个候选框得到4096个特征,然后每个类别有一个21个分类(包括一个背景分类器)得到20个类别,然后去掉冗余框,微调校准选框。
R-CNN缺点
重复计算:需要对两千候选框做CNN,计算量很大,而且有很多的重复计算。
SVM模型:在标注数据足够的时候不是最好的选择。
多个步骤:候选区域提取,特征提取,分类,回归都要单独训练,大量中间数据需要保存。
检测速度慢:GPU处理一张图片需要13秒,cpu上则需要53秒。
改进:能否避免候选框特征提取过程的重复的计算?
fast R-CNN
Fast R-CNN的主要步骤
- 候选区域的提取: 通过Selective Search 从原始图片中提取2000个左右的区域候选框。(与R-CNN相比没有变化)。
- 特征提取: 原始图像输入CNN网络,得到特征图。(与R-CNN相比,这里是将原始图片进行了一次特征提取)。
- ROI-Pooling: 根据 映射关系,将 不同尺寸的候选框 在 特征图上的对应区域 池化 为 维度相同的特征图 (因为全连接层要求输入的尺寸固定)。
- 全连接层:将维度相同的特征图转化为ROI特征向量(ROI feature vector)。
- 分类与回归:经过全连接层,再使用softmax分类器进行识别,用回归器修正边界框的位置与大小,最后对每个区域做NMS.
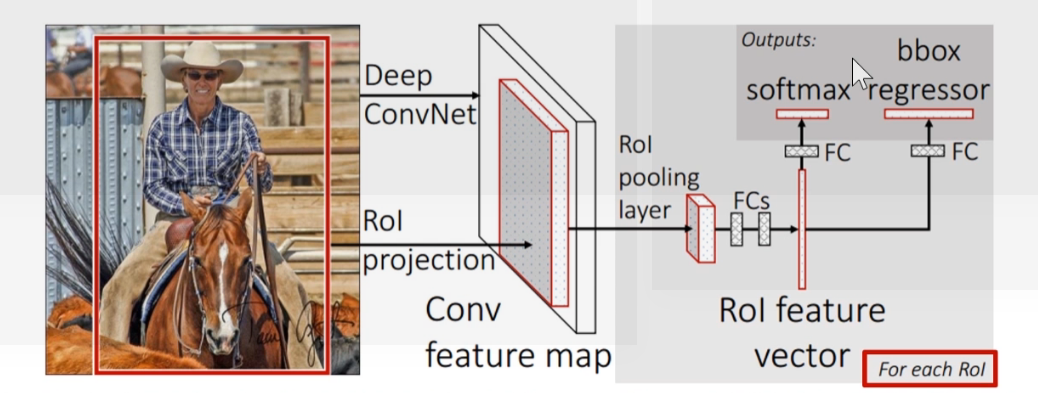
ROI Pooling

Fast R-CNN改进之处
- 直接对整张图片做卷积,不再对每个候选区域分别做卷积,从而减少大量的重复计算。
- 用ROI pooling对不同的候选框做尺寸的归一化。
- 将边界回归器放进网络一起训练,每个类别对应一个回归器。
- 用softMax代替SVM分类器。
Fast R-CNN缺点: - 候选区域的提取依旧使用Selective search,目标检测时间大多都消耗在这上面。(region proposal 2-3 s,而特征分类只需要0.32s)。
faster R-CNN
寻找更加高效的候选区域生成方法? 如何将所有的东西都用神经网络处理?
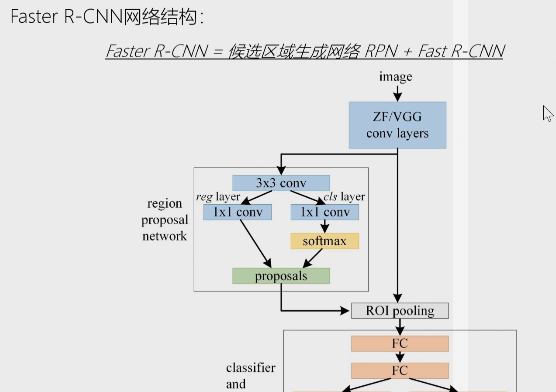
faster R-CNN主要的步骤:
1. 卷积层:输入图片经过多层卷积神经网络(ZF,VGG),提取卷积特征图,供给RPN网络和Fast R-CNN使用,RPN网络和Fast R-CNN 共享
特征提取网络可减少计算时间。
2. RPN层:生成候选区域,并用softmax判断候选框是前景还是背景,从中选取前景候选框并利用bounding box regression调整候选框的位置,得到候选区域。
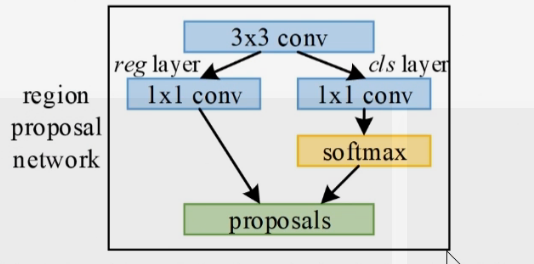

3. ROIPooling层:同Fast R-CNN一样,将尺寸不同的候选框,在特征图上的对应的区域池化为维度相同的特征图。
4.分类与回归 :同fast R-CNN ,用softmax分类器判断图像的类别,同时用边界框回归修正边界框的位置和大小。
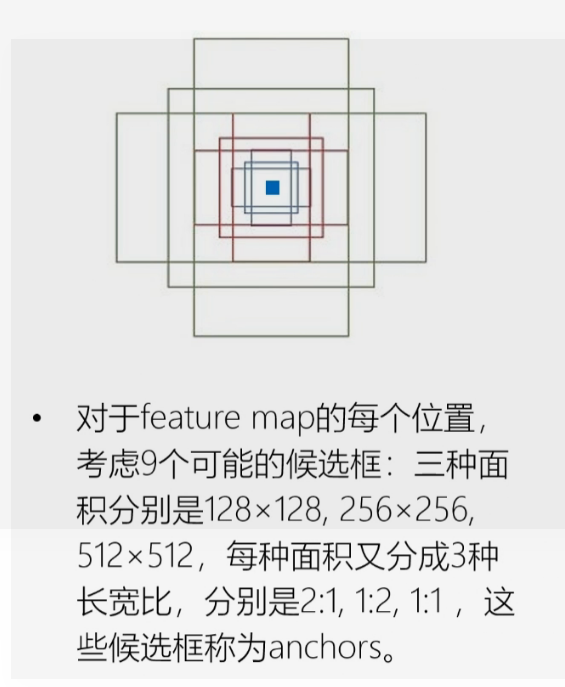
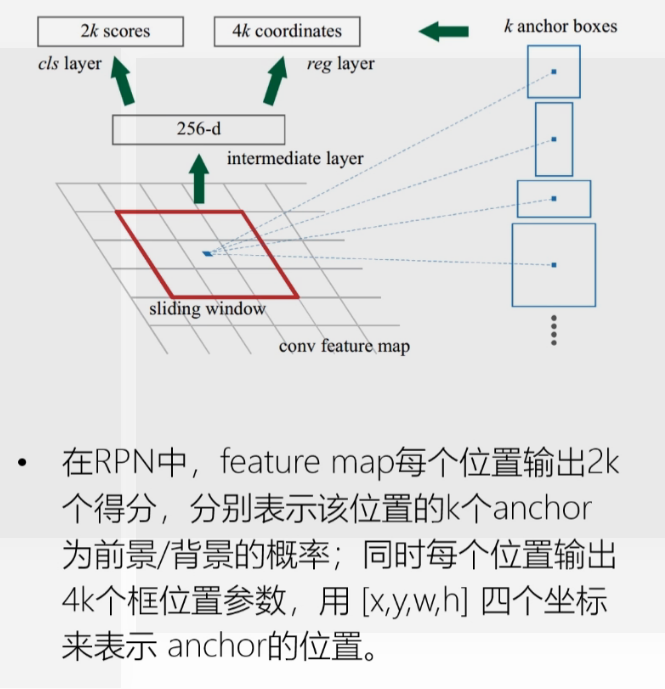
关于anchor box
One-stage
对输入的图像直接处理
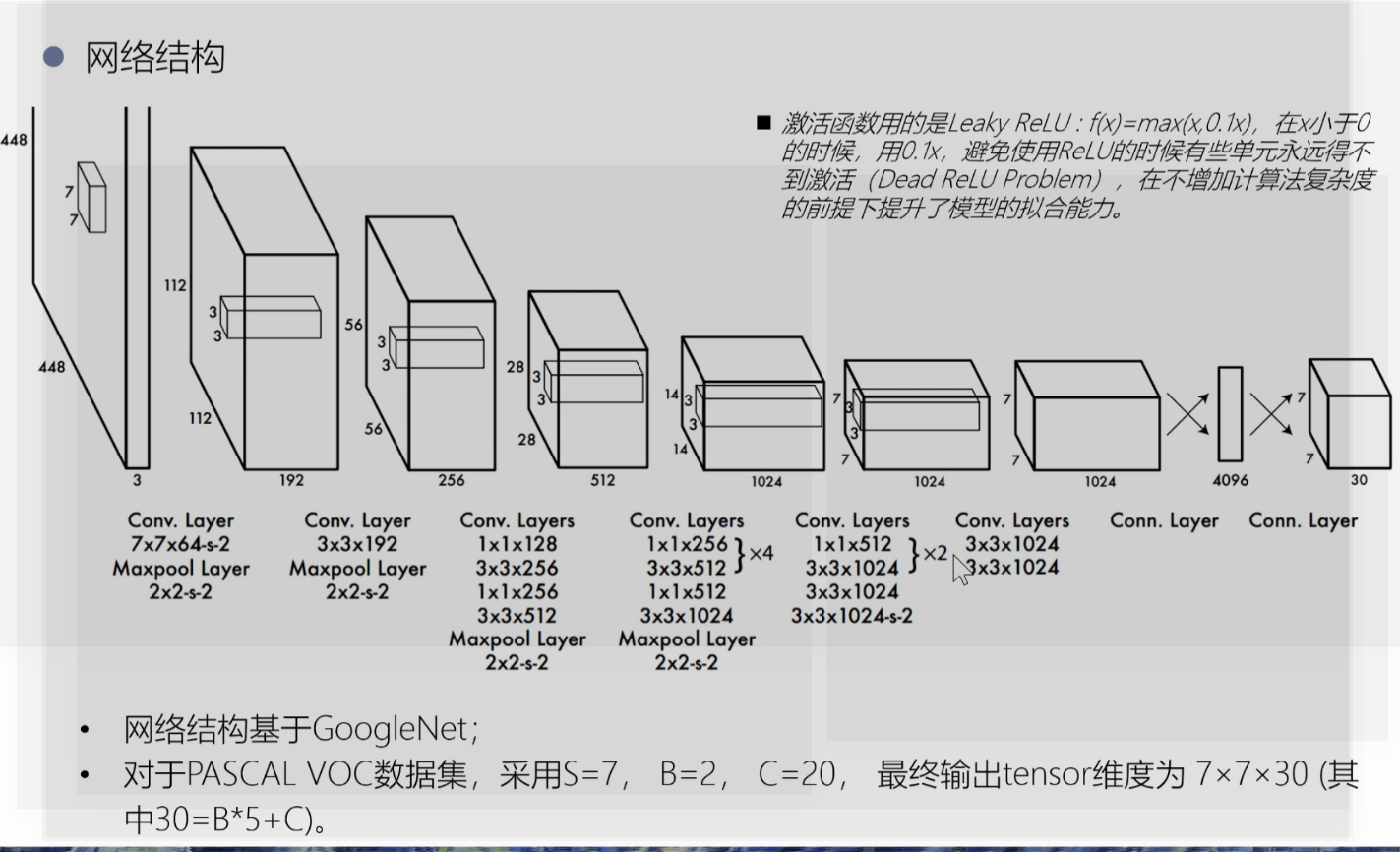
yolo




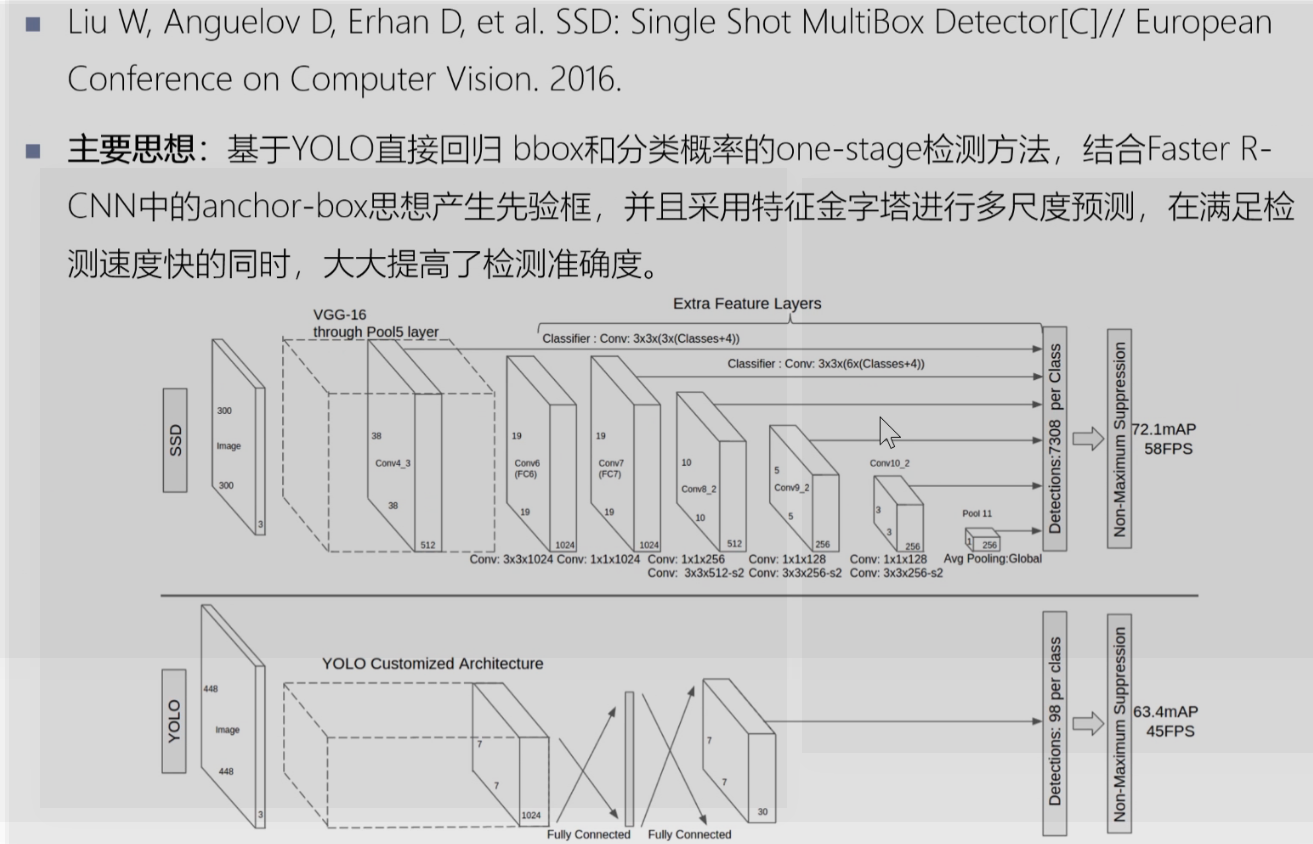
ssd
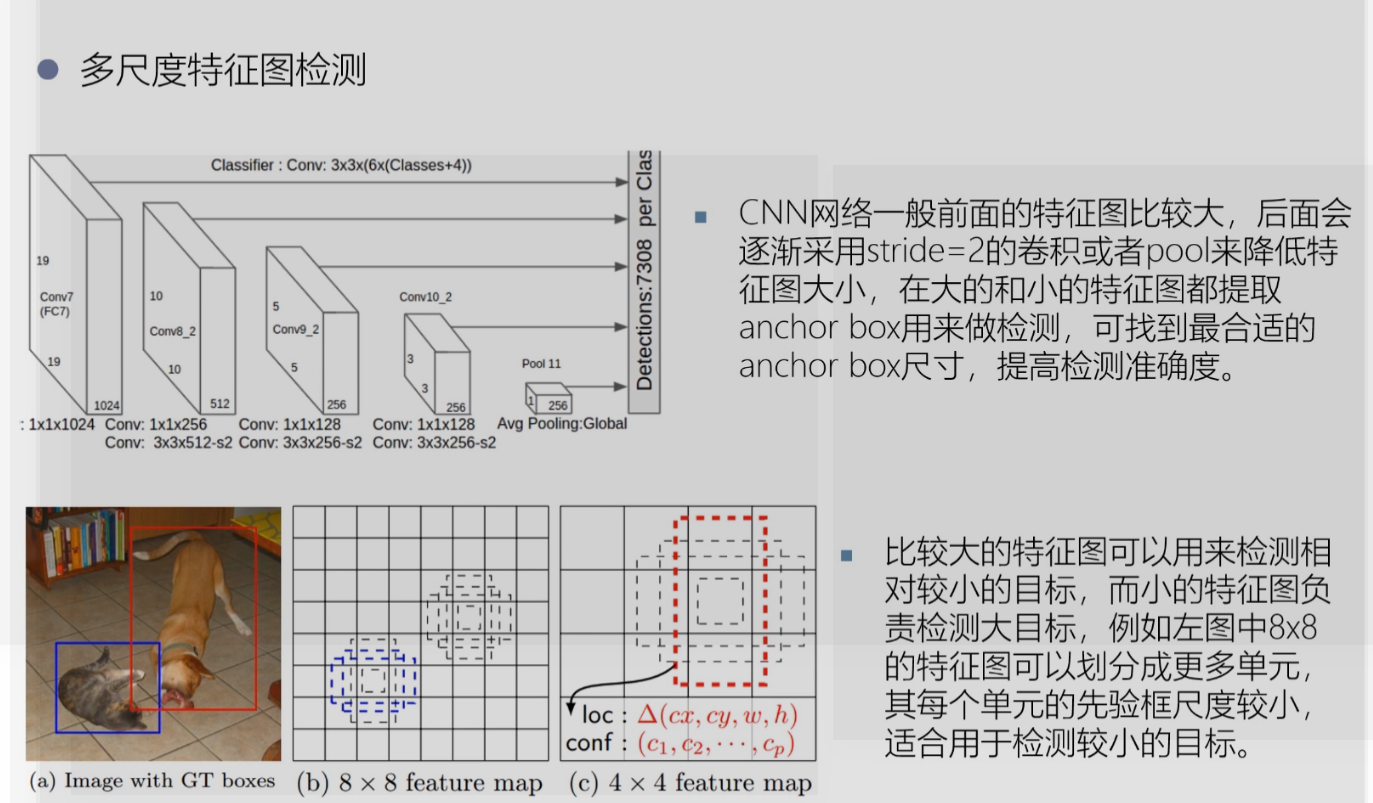
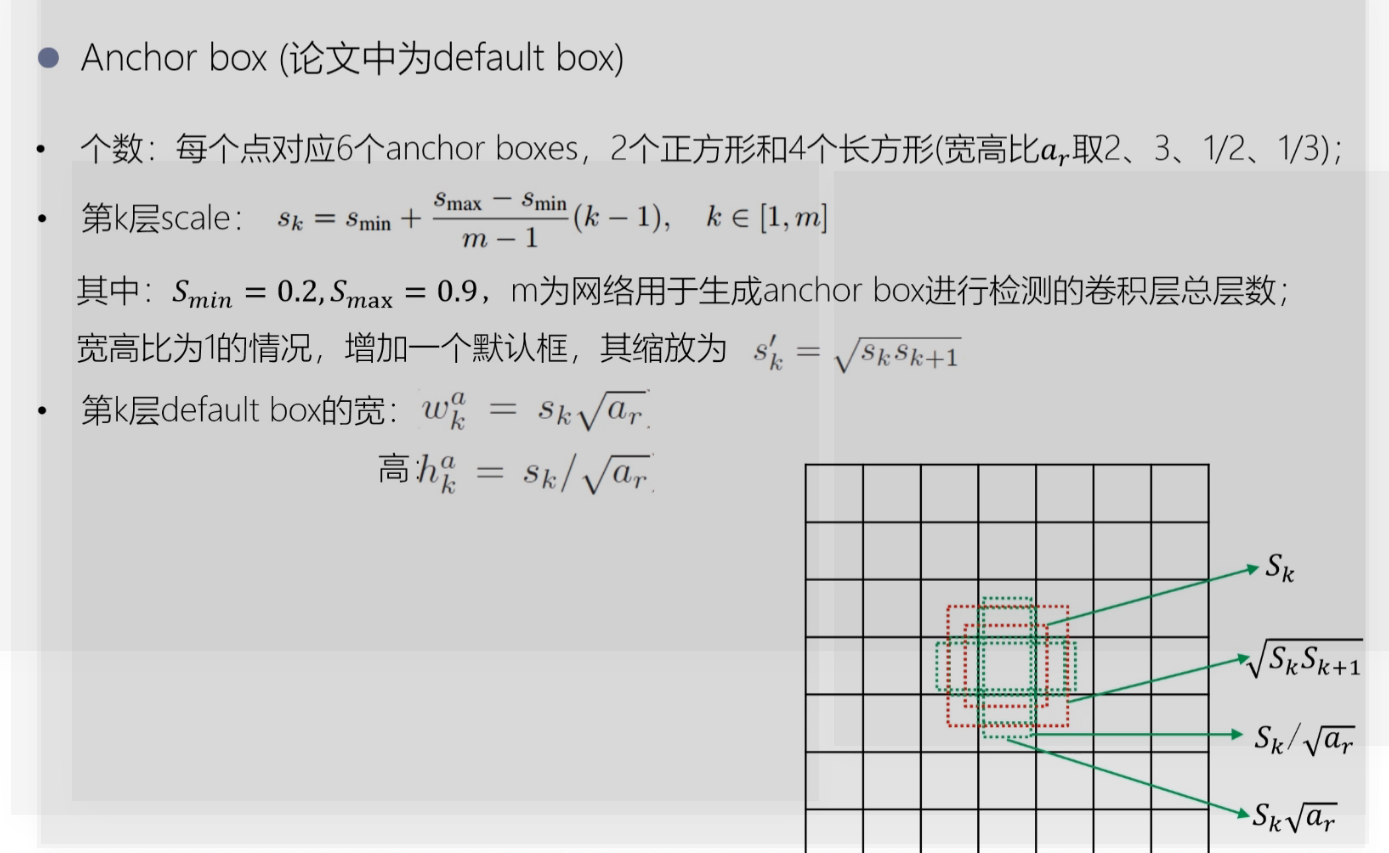

图像检测算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号