

基于CNN的图像分类算法
* 1 对卷积神经网络的研究可追溯到1979和1980年日本学者福岛邦彦发表的论文和“neocognition”神经网络。
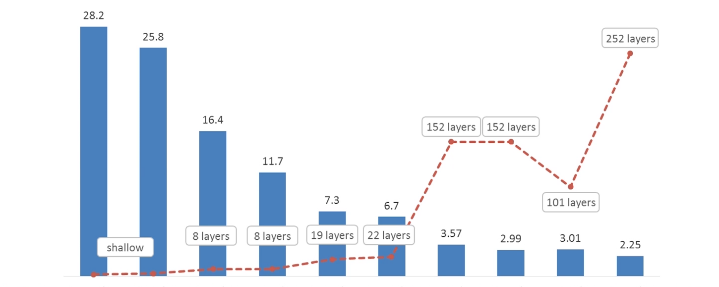
* 2 AlexNet使用卷积神经网络解决图像分类问题,在ILSVR2012中获胜并大大提升了state-of-start的准确率(大概16%左右)。(在11年top5的错误率在25.8%左右)
分类的四个里程碑
1.AlexNet
8layer 2012年
- Paper: ImageNet Classification with Deep Convolutional Neural Networks(2012)
- Author: Alex KrizheVsky, llya Sutskever, Geoffrey E. Hinton
- Test:error rate on ImageNet, top1:37.5%, top5:17.0%
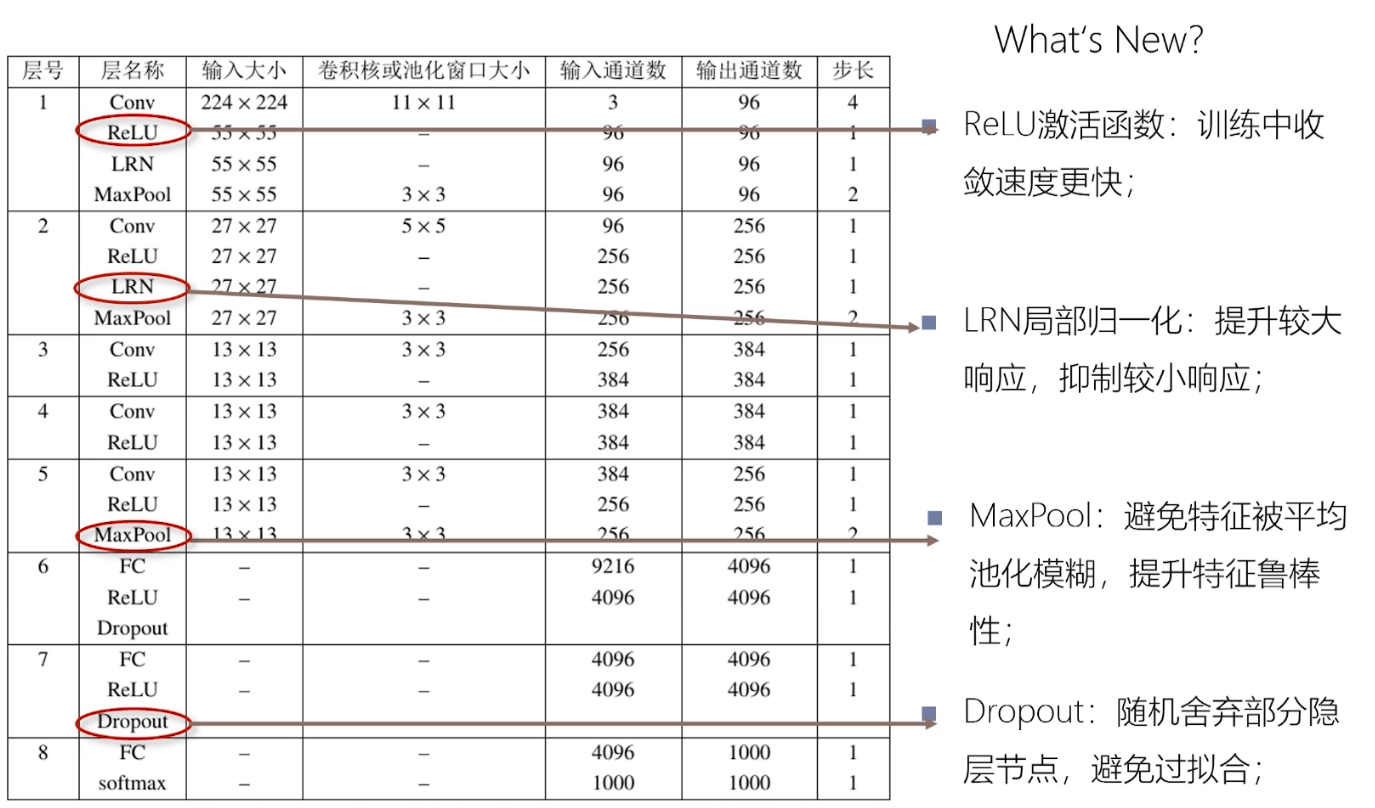
论文给出的网络结构(用两台GPU训练的),输入图片为\(224*224*3\), 先用的\(11*11\),步长为4的卷积核进行卷积,得到48个\(55*55\)的feature_map,然后使用5*5的卷积核和Max pooling得到128个\(27*27\)个feature_map,
后面都是使用\(3*3\)的卷积核,最后得2048个特征向量,然后对1000类物体进行分类。
1.1 AlexNet取得成功的原因
这是陈老师给出的四点理由
1.Relu激活函数:训练收敛比较快。
2.LRN局部归一化:提升较大响应,抑制较小响应。(后面证明LRN可能没啥作用)
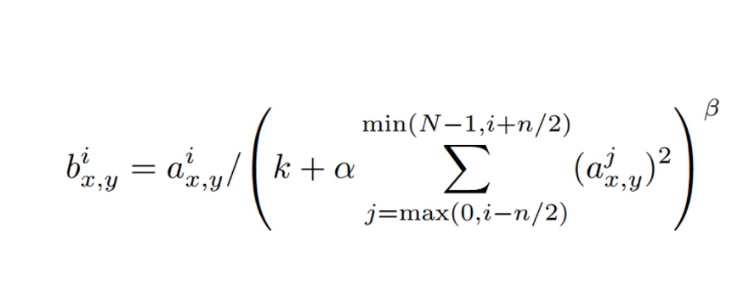
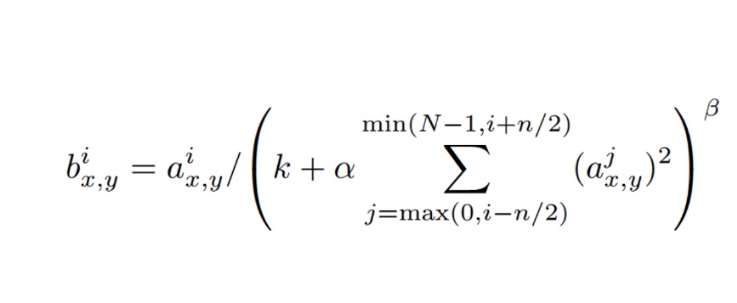
这个想法来自对于每个层可能有多个feature map,不同特征图的同一个位置上做局部响应的归一化。举个例子,比如在某一层有三个feature map,分别用于提对角线,三角形,正方形特征,在第一个fm中体现是否具有对角线特征,第二个体现是否具有
三角线特征,第三个体现是否具有正方形特征。然后对这三个结果进行局部响应归一化。比如参与三角形比较强,其他比较弱,然后就强化三角形特征,弱化其他的特征。
缺点:可能有的地方就是参与到了多个特征的提取。
3.MaxPool: 避免特征被平均池化模糊,提升特征鲁棒性。
4.Dropout:随机舍弃部分隐层节点,避免过拟合。
- 随机丢弃部分神经元。
- 在模型训练过程中,以一定的概率舍弃某些隐层神经元。在反向传播更新权重的时候,不更新与该神经元相关的权重.使用训练的好的网络是所有的神经元都要使用的。
- 被舍弃神经元相关的权重得保留下来(只是暂时不更新),另一批样本输入时继续使用与该神经元相关的权重。
- 防止训练数据中复杂的co-adaptation,抑制过拟合。
5.使用多个卷积层,有效提取图片的特征。
2.VGG
比AlexNet更深的网络。
2014年
- Paper: Very Deep Convolutional Networks for Large-Scale Image Recognition(2014)
- Author: K.Simonyan, A.Zisserman
- Test: error rate on ImageNet, top1:24.7%, top5:7.5%
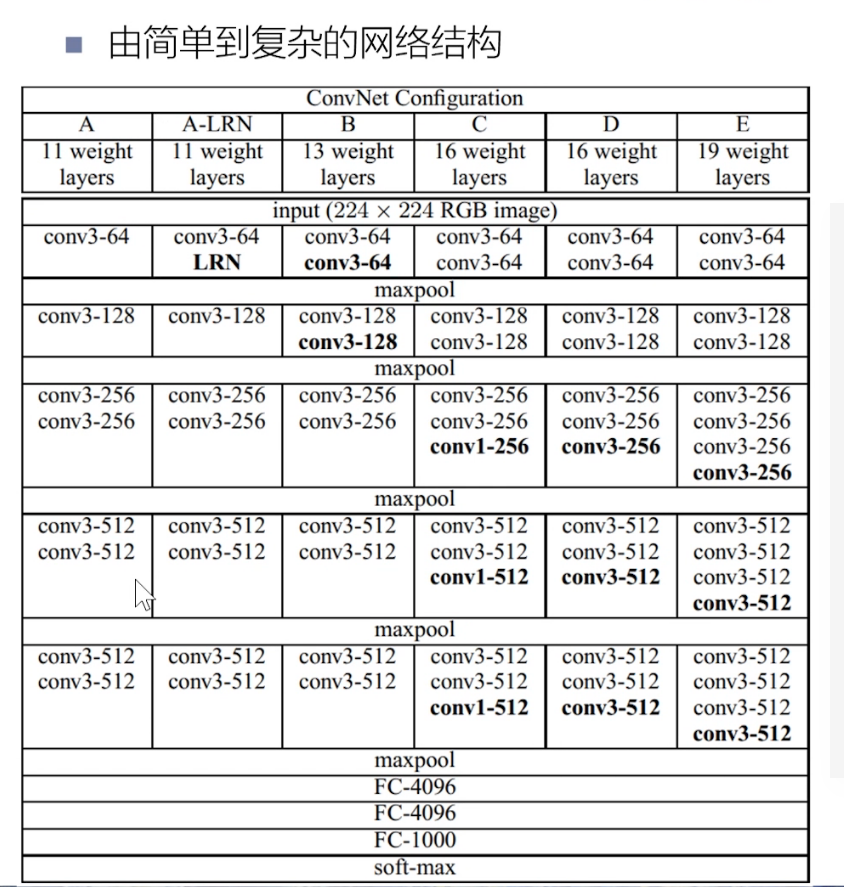
VGG有很多版本,常见的有VGG16,VGG19。
VGG16
对于更深的网络可能出现梯度爆炸和梯度消失的情况,对于离损失函数比较近的地方的层可能在反向传播中可以得到很好的训练,但是较远的层可能只受到微小的影响(偏导比较小),很难训练好。
所以VGG先训练11层网络。用收敛后的前四个卷积层和后3个全连接层的权重作为更深神经网络的前四个卷积层和后3个全连接层的初始权重,其余层的权重随机初始化。
比如上图中先训练A(11layer),选择其中的conv3-64,conv3-128,conv3-256,conv3-256, FC-4096,FC-4096,FC-1000作为更深的网络(16,19)的相应层的初始权重,中间加的层权重随机权重,重新开始训练。
11层的训练比较快。


2.1 VGG实验结果
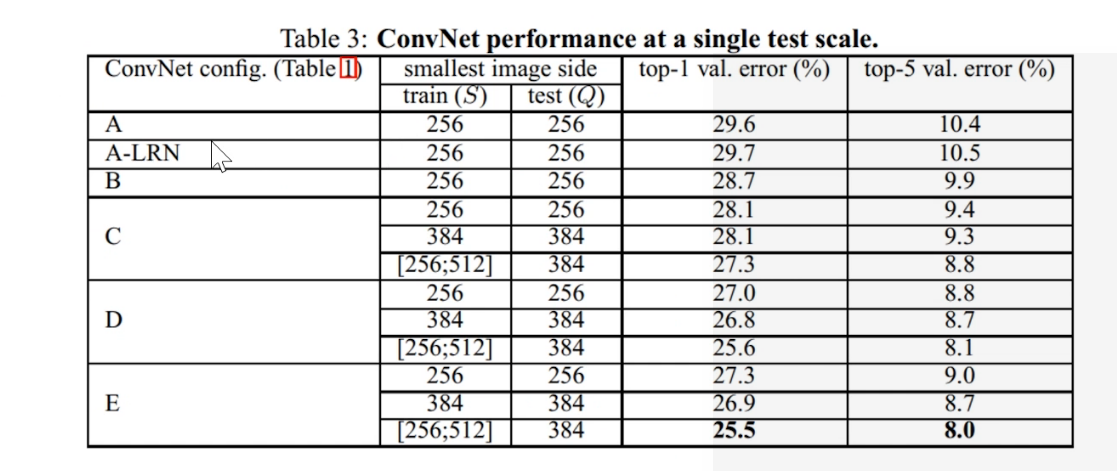
结论
A(11)B(13) C D (16) E(19)
- 1 A/A-LRN: 加LRN准确率无明显的提升。
- 2 A/B/D/E: 层数越多准确率越高;
- C/D: conv33 比conv11准确率更高。
- Multi-scale training可明显提高准确率。
2.2 问题
为什么VGG没有更深的层?
陈老师的观点是,作者可能试过更深的网络,但是采取这种训练方式,19层可能已经是极限了,以VGG这种方式训练再深的网路收益已经很低了,或者可能错误率还会上升。
2.3 VGG中规整的卷积-池化结构
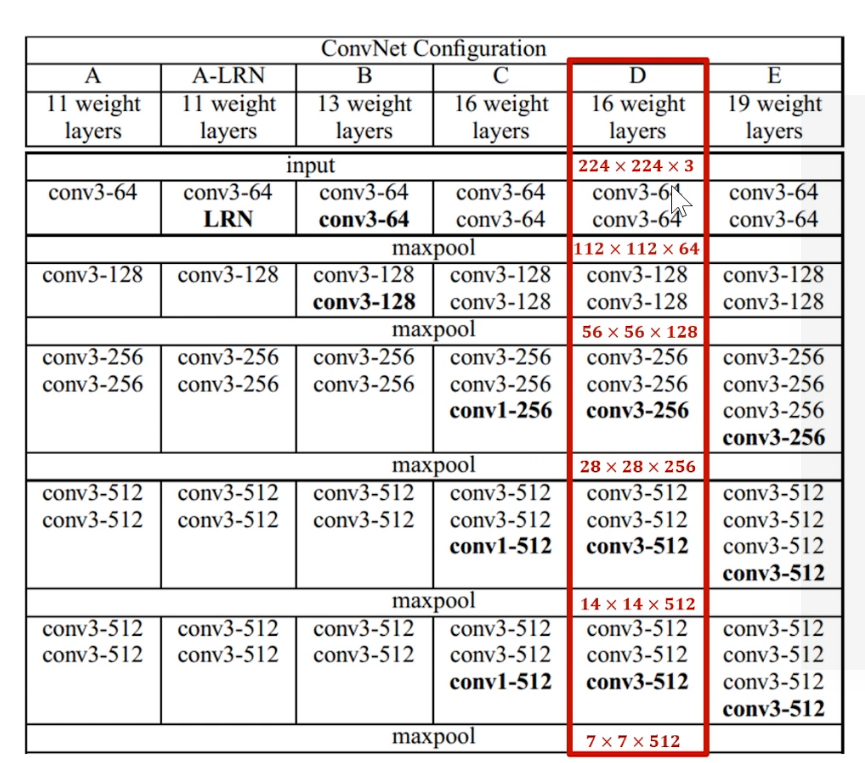
- Conv
- 所有的卷积层filter = \(3*3\), stride = 1, pad = SAME
pad = SAME : pad至输出的图像大小等于输入的图像大小
pad = VALID : pad = 0
- Maxpool
- 所有的池化层filter大小/stride/pad相同
- filter = \(2*2\), stride = 2, pad = 0
卷积层: 负责数据体深度变换(控制特征图数量)
池化层: 负责数据体长宽变换(控制特征图的大小)
2.3 知识点
1.使用多层小卷积比单层大卷积效果好
实验 使用两层\(3*3\)conv代替\(5*5\) conv
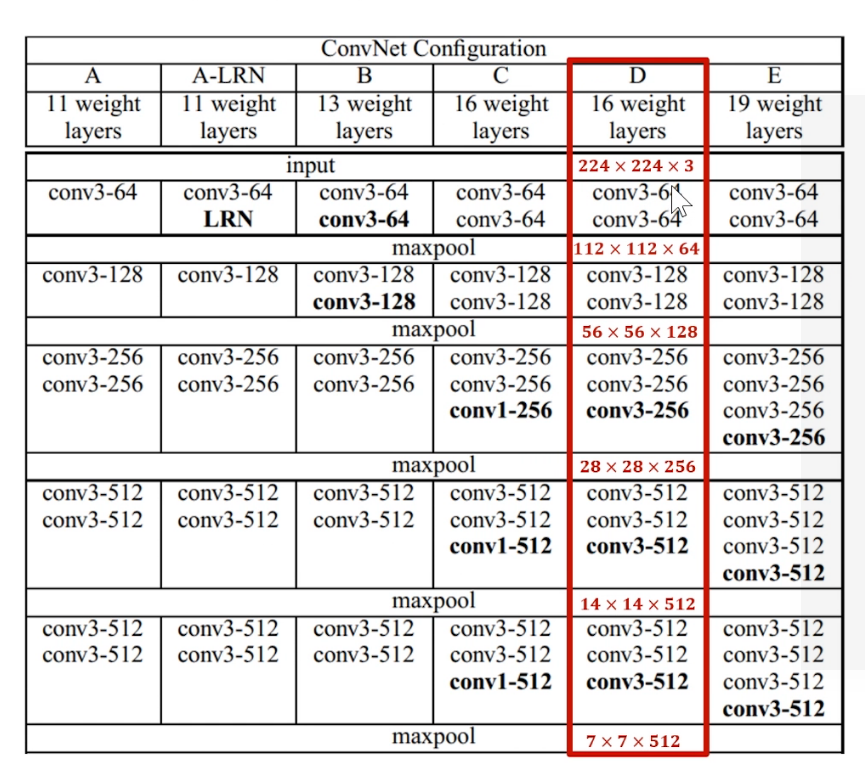
原因:是一个\(5*5\)conv和两个\(3*3\)conv的感受野大小相同;每个卷积层加入Relu,两层\(3*3\)conv决策函数区分能力更强。
结果:\(5*5\)conv网络比两个\(3*3\)conv网络在top1准确率低7%。
相同感受野,多层网络权值更少
2.4 VGG成功的原因
- 更深的卷积神经网络,更多的卷积层和非线性激活函数,提升分类准确率。
* 使用规则的多层小卷积替代大卷积,减少参数数量,提高训练收敛速度。 - 部分网络参数的预初始化,提高训练收敛的速度。
2.5 问题
卷积核还能不能更小?网络还能不能更深?
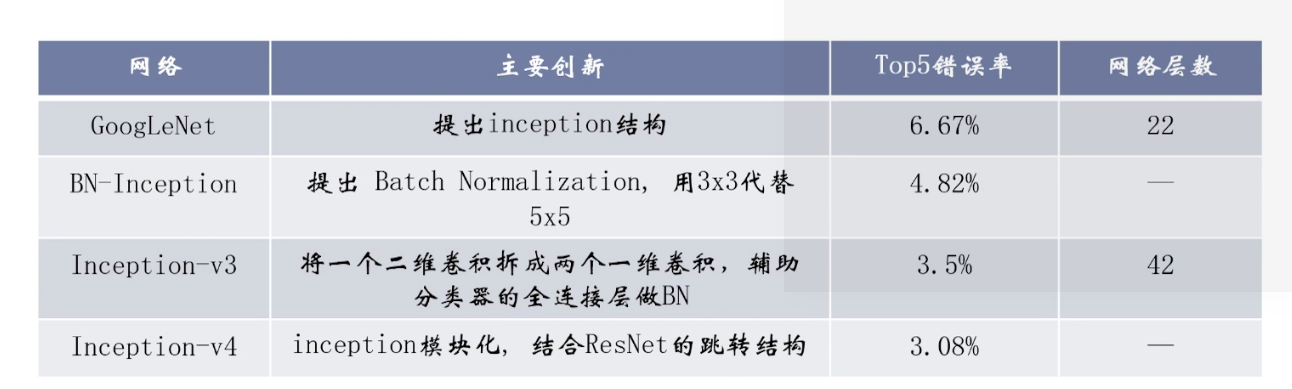
3 inception系列
- Inception-v1(GoogleNet):Szegedy C, Liu W, Jia Y, et al.Going deeper with convolutions, CVPR2015:1-9.
- BN-Inception: loffe S, Szegedy C, Batch normalization:accelearating deep network training by reducing internal covariate shift. ICML, 2015:448-456.
- inception-v2,Inception-v3: Szegedy C, Vanhoucke V, loffe S, et al.Rethinking the Inception Architecture for Computer Vision[C] //CVPR, 2016:2818-2826.
- Inception-v4:Szegedy C, loffe S, Vanhoucke V,et al. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning AAAI`2017。
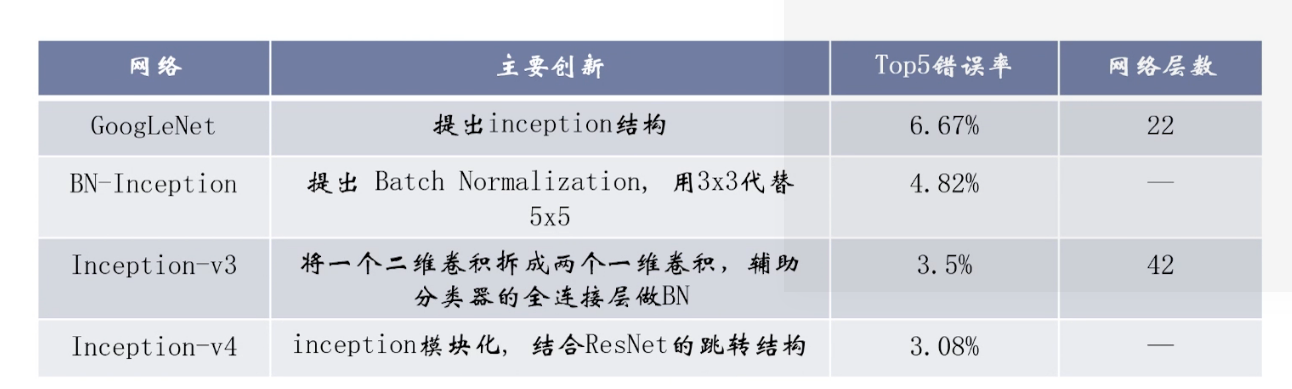
核心创新:更小的卷积以及BN(用于缓解梯度消失问题)
3.1 Inception V1
- Inception 模块
- Naive version: 叠加多种尺寸的卷积层和池化层,获取不同尺度的特征,提升网络对不同尺寸特征的适应性。
- Dimension redutions : 使用1*1 的卷积层来缩减维度(减少channel),形成“瓶颈层”,减少参数。
(不同的特征的尺度是不一样的)
1*1卷积的作用,调整channel的数量。
跨通道聚合,进一步起到降维(或者升维)的作用,减少参数。
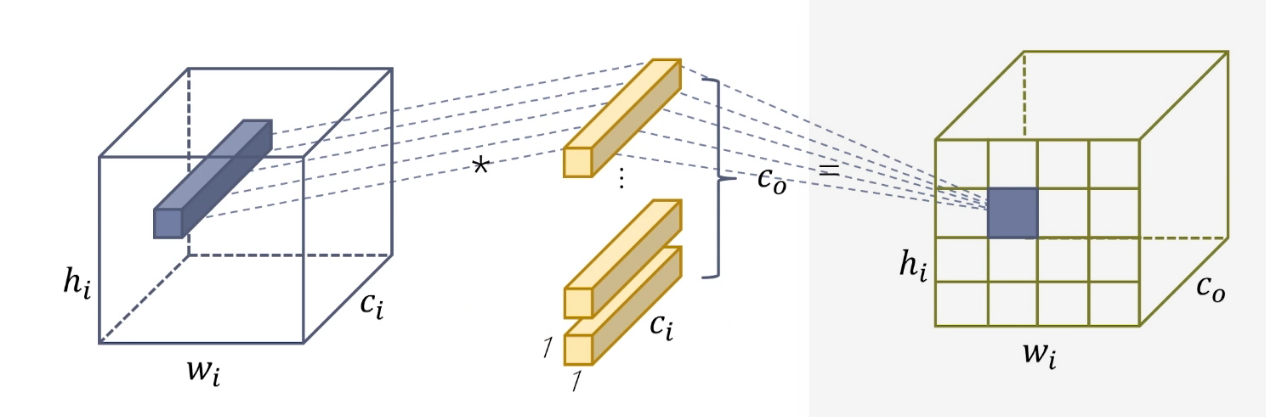
相当于在输入和输出之间做一个特征上的全连接,提取非线性的特征。
同时当co < ci 时,维度降低,参数减少。

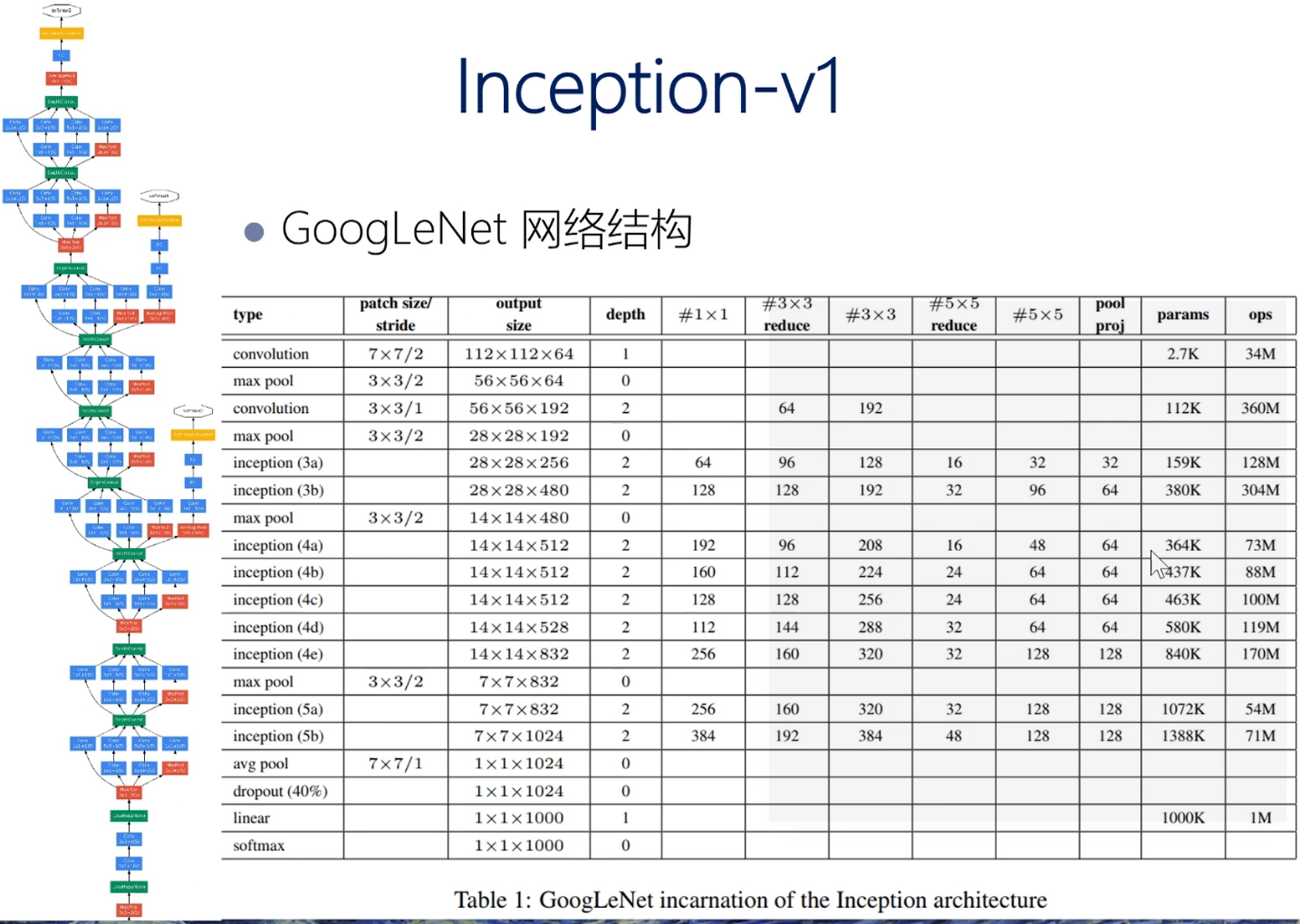
这里有9个Inception,后面接的是softmax
Softmax辅助分类网络
上面的图中有两个Softmax辅助分类网络
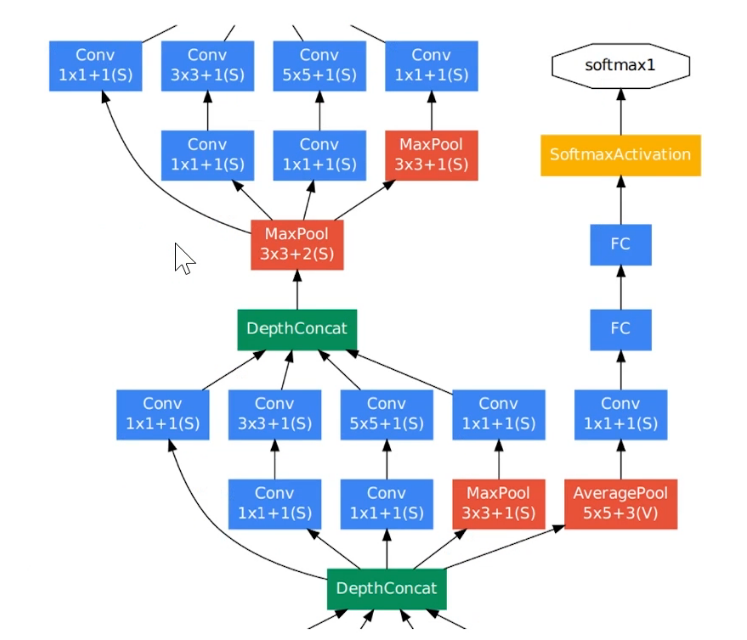
- 训练时,让中间某一层的输出经过softmax得到分类结果,并按照较小的权重(大概是0.3)加到最终的分类结果中,相当于模型融合.
防止多层神经网络训练过程中梯度消失。 - 推理时,softmax辅助分类网络会被去掉。
作用:可以用来比较深的网络(可以理解为观察中间结果怎么样)。
BN-Incption
- 1 学习VGG使用两个\(3*3\)的卷积代替\(5*5\)的卷积。

- 2 使用BatchNorm, 并在每个卷积层之后、激活函数之前插入BN层。

normalize

- 在一个batch类不同样本之间,在激活层的输入调整为标准正态分布(均值为0,方差为1).
- 激活层输入分布在激活函数敏感部分,输入有小的变化就能引起损失函数的较大的反应。避免梯度消失,加快训练速度。
Scale and shift
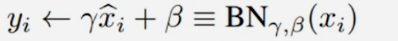
这里的γ和β可以调节
- 标准化后的输入使得网络的表达能力下降。
- 为保持网络的表达能力,增加两个可训练参数。
不仅仅再是层的调节,现在涉及到batch之间的调节。
####### BatchNorm效果

- BN可替代LRN/Dropout/L2 Normalization
- 可提高收敛速度,训练速度。
- 可选择更高的学习率,方便调参。
Inception-v3
- Factorization思想
- 将\(3*3\)的卷积拆分成\(1*3\)和\(3*1\)的卷积。
- 减少参数数量,同时通过非对称的卷积结构拆分增加特征多样性。
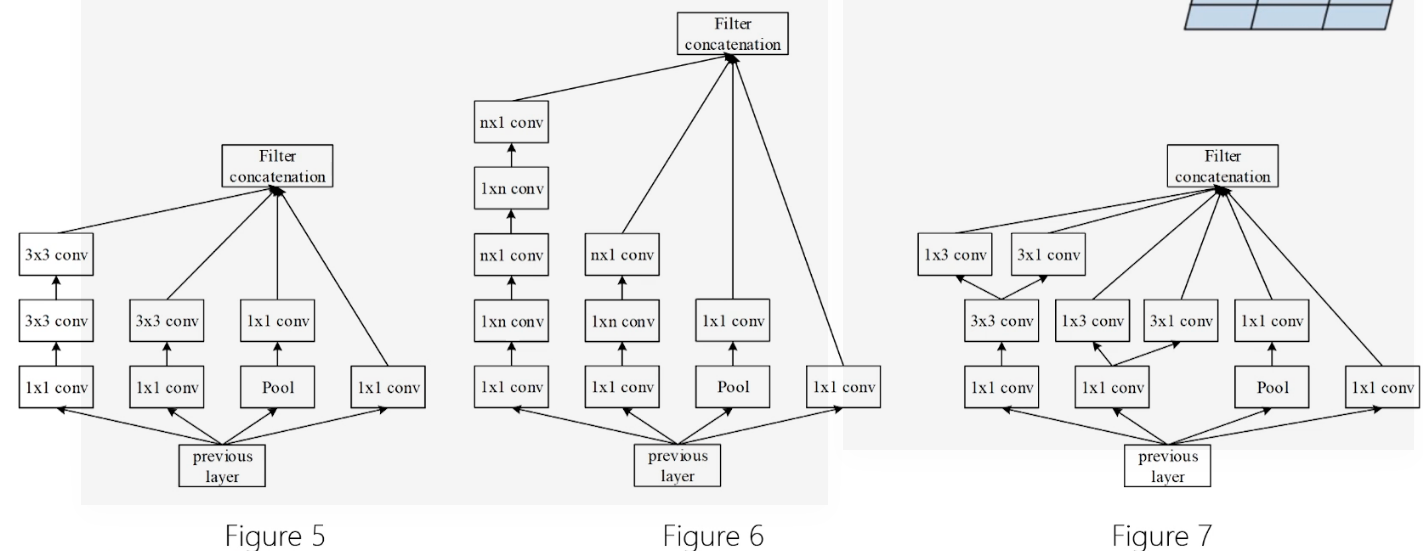
- 网络结构
- 将前面三种Iception结构组合起来
- GoogleNet中\(7*7\)的卷积拆分\(3*3\)的卷积
- 卷积层和辅助分类器的全连接层做BN
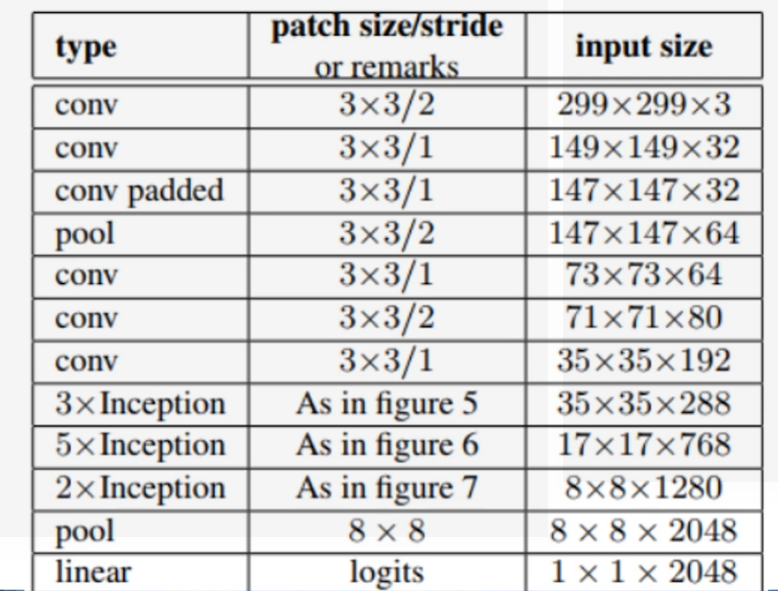
4 ResNet
- Paper: Deep Residuak Learing for Image Recognition(2015)
- Auther: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- Test: error rate on ImageNet, top5:3.57%(resnet152)
层数深度的革命
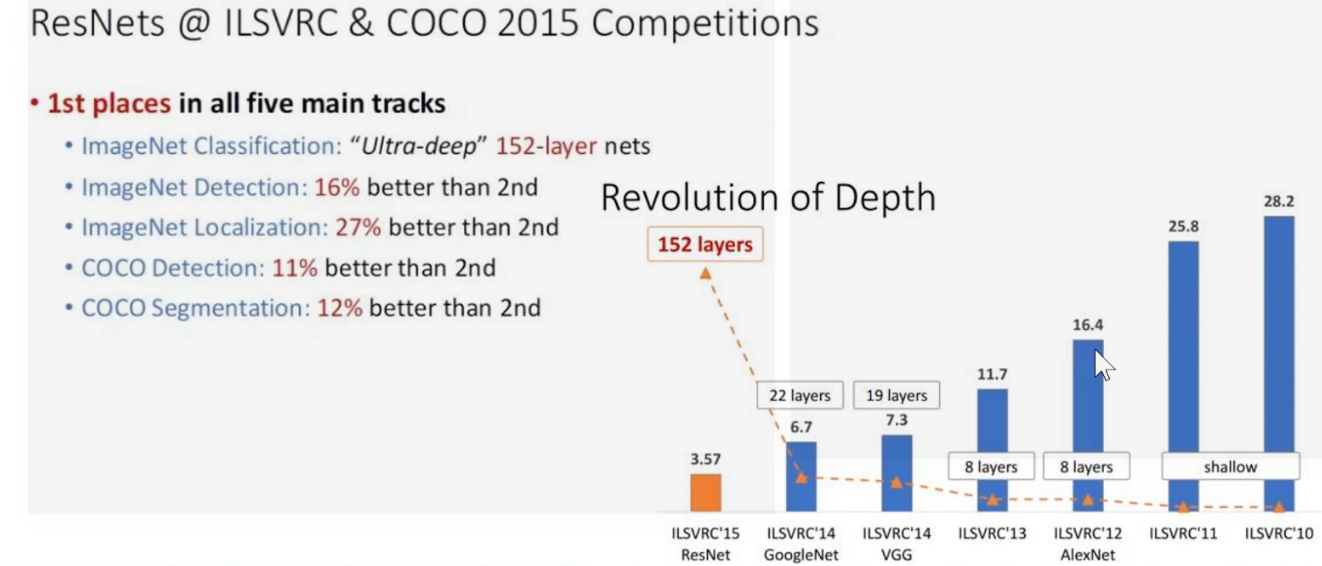
问题:卷积层的堆积就能提升图像分类的准确率吗?
实验:分别用20层和56层卷积神经网络在cifar10数据集上进行训练和测试,发现更深的网络的错误率更高,在ImageNet数据集上也同样如此。
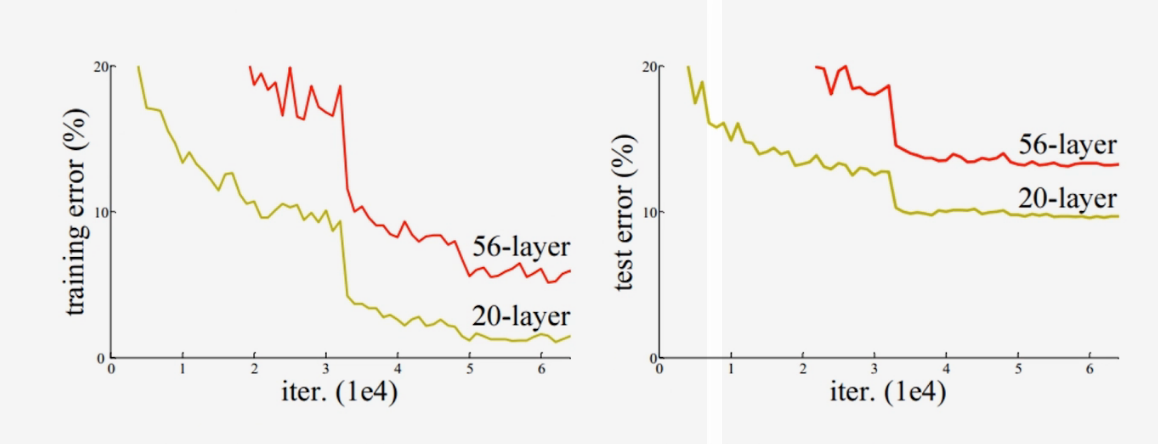
- 原因: 梯度消失? NO,使用BN可以有效的缓解梯度的消失;
过拟合? NO,更深的网络在训练集上的误差同样更高;
神经网络退化:收敛到极值点而非最值,误差大。
残差网络
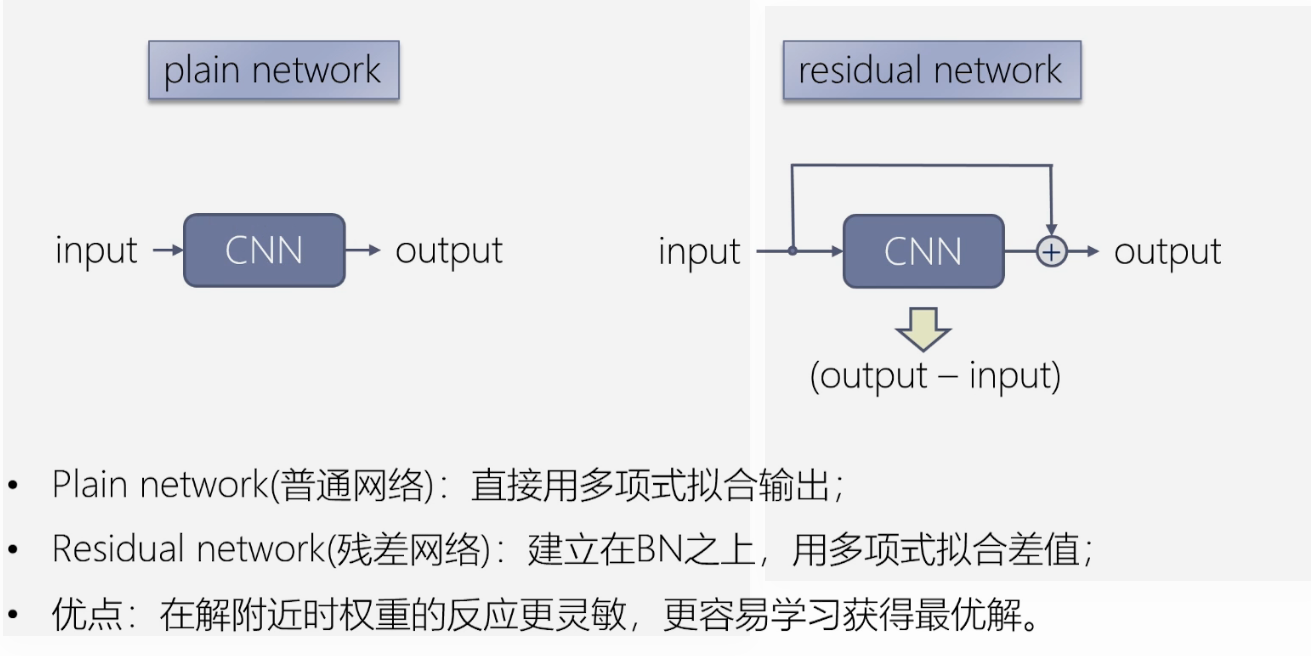
算出输入与输出的差值,这个建立在BN之上。
残差块
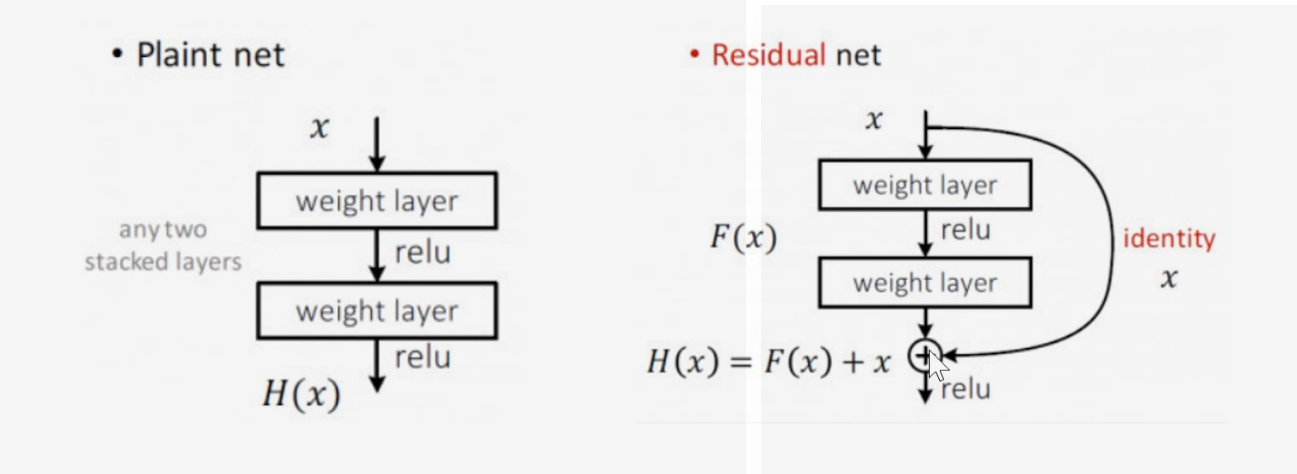
- 残差网络在训练时更容易收敛。
在H(x)对x求导时,至少有个1保底。
将残差块应用到普通的网络。
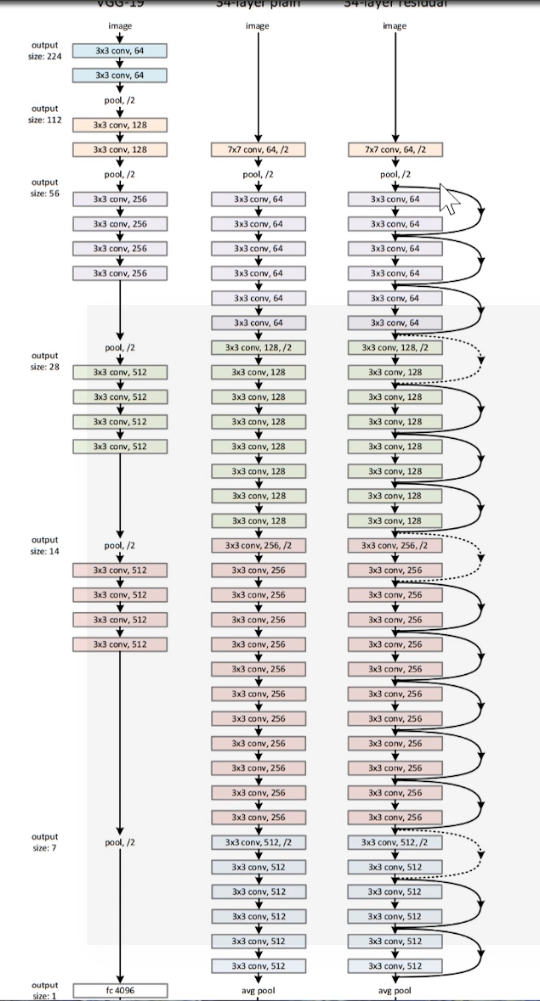
1. 改造VGG得到plain-network。
- plain-network:无跳转链接的普通网络。
- 基本全部由卷积层构成:filter = \(3*3\), stride = 1, pad = SAME;
- 特征图的尺寸的减小有stride = 2 的卷积层完成。
- 如果特征图的尺寸不变,则特征的数量不变;如果特征图的尺寸减半,则特征图的数量翻倍。
2.增加跳转连接得到Renet
- 实线: 特征尺寸和特征数量不变,直接相连。
- 虚线: 特征图尺寸减半,特征图数量翻倍。
- 特征图数量翻倍的两种方法:
a. 以stride = 2直接取值,不够的特征补0(不引入额外的参数)
b.以stride = 2,特征数量翻倍的1*1卷积做映射,卷积的权重经过学习得到,会引入额外的参数。

