
实验一贝叶斯分类器的设计以及应用试验
实验目的:
理解朴素贝叶斯分类器的原理;
能够独立实现贝叶斯分类器的设计;
能够评估分类器的精度。
实验步骤:
1.朴素贝叶斯分类器原理理解
- 贝叶斯决策理论
假设有一个数据集,由两类组成,对于每个样本分类如下:
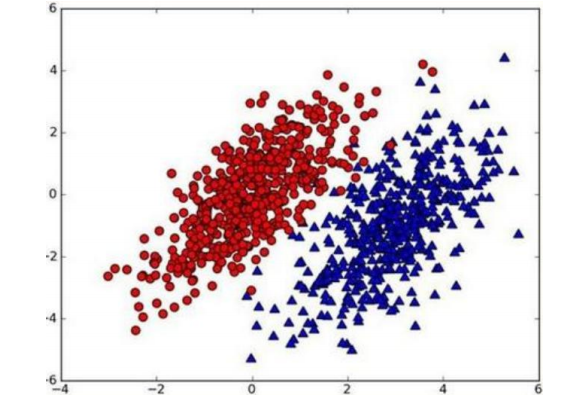
现在有一个新的点new_point(x,y),其分类未知。用p1(x,y)表示点(x,y)属于红色分类的概率,p2(x,y)表示该点为蓝色的分类的概率、
制定以下规则:
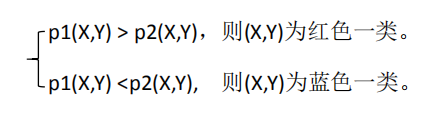
用等价的条件概率表示如下:

将p(red|x)记录为p(c1|x),p(blue|x) 记录为p(c2|x),那么贝叶斯公式如下:
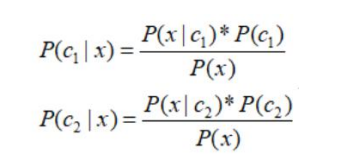
出现一个新的需要分类的点时候。我们只需要计算
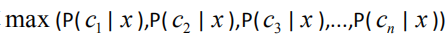
2. 朴素贝叶斯分类
朴素贝叶斯分类的正式定义如下:

- 朴素贝叶斯有一个很强的条件假设 * , 当Yi确定时 ,yi的各个特征之间相互独立。

二、使用朴素贝叶斯进行文本分类(词集模型)
文本中的特征来自于文本的词条 (token),一个词条是字符的任意组合。
1. 准备数据: 从文本中构建词向量
确定将那些词纳入词汇集合,然后将每一篇输入文本转换为与词汇表同纬度的向量。
####### 1. 创建实验样本,这些文本被切分为一系列词条集合,将标点从文本中去除。另外返回类别标签集合。
def loadDataSet():
postingList = [['my','dog','has','flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid'],
]
classVec = [0,1,0,1,0,1]
return postingList, classVec
2、创建词汇表 词集模型 即包含所有词的列表
def createVocabList(dataSet):
vocab_set = set([])
for document in dataSet:
vocab_set = vocab_set | set(document)
return list(vocab_set)
3、结合词汇表 将输入文档转换为文档向量
### 结合词汇表 将输入文档转换为文档向量
### 返回值类似[1,0,1,0 ....]
def setWordsToVect(vocabList,inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet: #遍历输入的每个词条
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word:%s not in vocabList" % word)
return returnVec
4、训练算法
### 训练算法
def trainNBO(trainMatrix,trainGategory):
"""
:param trainMatrix 文件的单词矩阵[[0,1,0,1],....[0,1,1]]
:param trainGategory 文件对应的标签类别 [0,1,1...],对应1代表侮辱,0代表不是侮辱
return:
: p0Vect: 各单词在分类0下的概率
:p1Vect: 各单词在分类1下的概率
:pAbusive : 文档属于分类1的概率
"""
numTrainDocs = len(trainMatrix) #文件数
numWords = len(trainMatrix[0])# 单词数
pAbusive = sum(trainGategory)/float(numTrainDocs) #初始化文件数
#p0Num = np.zeros(numWords); p1Num = np.zeros(numWords)
p0Num = np.ones(numWords); p1Num = np.ones(numWords)
#p0Denom = 0.0; p1Denom = 0.0
p0Denom = 2.0; p1Denom = 2.0
for i in range(numTrainDocs):
if trainGategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom
p0Vect = p0Num/p0Denom
return p0Vect, p1Vect,pAbusive
6.
"""
将所有的单词出现数初始化为1, 将分母初始化为2 将trainNBO()的第4和第五行修改如下:
pAbusive = sum(trainCategory)/float(numTrainDocs) #初始化文件数
#p0Num = np.zeros(numWords); p1Num = np.zeros(numWords)
p0Num = np.ones(numWords); p1Num = np.ones(numWords)
#p0Denom = 0.0; p1Denom = 0.0
p0Denom = 2.0; p1Denom = 2.0
"""
7.朴素贝叶斯分类函数
### 朴素贝叶斯分类函数
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
"""
:param vec2Classify 测试向量文档
:param p0Vec:非侮辱词汇 在词汇表中单词的概率
:param p1Vec: 侮辱性词汇
:param pClass1: 侮辱性的先验概率
"""
#做对数映射
p1 = sum(vec2Classify * p1Vec) + math.log(pClass1)
p0 = sum(vec2Classify * p0Vec) + math.log(pClass1)
if p1 > p0:
return 1
else:
return 0
8.打印函数
def printClassierResult(sentense,sentenseType):
print(sentense)
if sentenseType ==1:
print("这是侮辱性语句")
else:
print("这不是侮辱性语句")
9. 加载测试数据
def loadTestSet():
testList = [['It`s','worthless','to','stop','my','dog','eating','food'],
['Please','help','me','to','solve','this','problem'],
['This','dog','is','so','stupid',',','But','that','one','is','so','cute'],
]
return testList
10. 开始测试
if __name__ == '__main__':
## 训练
postingList,classVec = loadDataSet()
vocab_set = createVocabList(postingList)
messageMatrix = []
for sentence in postingList:
message = setWordsToVect(vocab_set,sentence)
messageMatrix.append(message)
p0Vect,p1Vect,pAbusive = trainNBO(messageMatrix,classVec)
##test 词汇集
testList = loadTestSet()
for sentence in testList:
sVec = setWordsToVect(vocab_set,sentence)
sType = classifyNB(sVec,p0Vect,p1Vect,pAbusive)
printClassierResult(sentence,sType)
运行结果:



修改分类器 词袋模型
### 使用朴素贝叶斯进行文本的分类(词袋模型)
### 在词袋模型中每个单词可以出现多次,当遇到一个单词时,就会增加词向量的对应值,而不是将
### 将对应的一个数值设为1
### 其中词集模型 setOfWord2Vec()被替换成bagOfWord2Vec()
def bagOfWord2Vec(vocbList,inputSet):
"""
param:vocabList 词汇列表
param: inputSet 文档
return:词汇向量
"""
returnVec = [0] * len(vocbList)
for word in inputSet:
if word in vocbList:
returnVec[vocbList.index(word)] +=1 #记录单词出现出现的次数,而不是出现与否
return returnVec
####### 添加词袋模型的测试函数
### test 词袋模型
for sentence in testList:
sVec = bagOfWord2Vec(vocab_set,sentence)
sType = classifyNB(sVec,p0Vect,p1Vect,pAbusive)
printClassierResult(sentence,sType)
运行结果:

评价
1、首先朴素贝叶斯有一个很强的假设:各特征之间有很强的独立性。但实际上语义之间是有上下文联系的。比如当一句话中出现太多贬义词,
但实际是表达褒义的时候,可能有错误分类。比如这里:

2、word2vec 这种算法 会考虑上下文,比Embedding效果要好,维度更少,通用性也强。但是由于词和向量是一一对应的,所以无法解决一词多义的问题。
而且这种静态方法,无法针对特定任务做动态优化。
3.选用词袋模型,当某个单词出现多次时,可以增加该单词在某类别的权重,这里数据太小。实验效果没有明显修正。比如这里:

4. 注意这里的修改:
#p0Num = np.zeros(numWords); p1Num = np.zeros(numWords)
p0Num = np.ones(numWords); p1Num = np.ones(numWords)
#p0Denom = 0.0; p1Denom = 0.0
p0Denom = 2.0; p1Denom = 2.0
这里是避免如果出现训练集未出现的词汇,可能导致概率为0的情况,影响分类效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号