哈希表(Hash Table)
哈希表(Hash Table)
数组加链表实现的一种数据结构(JDK 的 HashMap 会优化红黑树)
桶大小
数组长度怎么确定?根据需要可以自行设置,但是要设置为 2 的指数
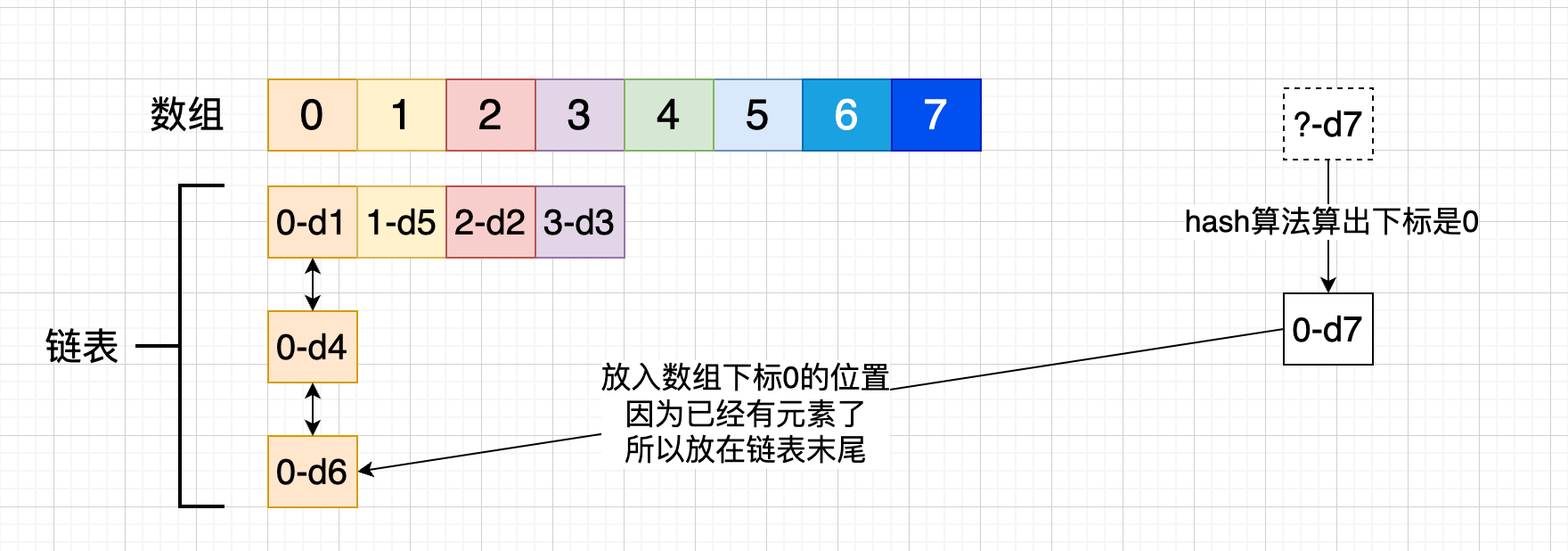
添加元素是会先通过哈希算法算出下标,然后根据下标放入到数组中
当算出的下标如果越界了,需要均匀的分布在数组中,怎么保证呢?
如果添加 d8 元素,算出下标是 8,就放在 arr[0] 处
如果添加 d9 元素,算出下标是 9,就放在 arr[1] 处
这个可以通过 % (取余)得到,但是除法效率不高,& (按位与运算)效率更高,结果也是相同的,但是要使用 & 运算,需要保证数组长度是 2 的指数
基于 2 的指数优化点:按位与、拆分链表、高低位异或
扩容
负载因子
元素个数(链表也是一个元素) 与 数组长度 的比值,这个值不宜过大也不易过小
- 太小的话,还没放几个元素就要扩容,浪费空间
- 太大的话,比如是1,数组已经放满了,这时再扩容可能已经晚了
JAVA 中的 HashMap 是 0.75,为什么是 0.75?去问高斯林吧(一个根据经验得出来的值)
扩容多少?
一般是翻倍,为什么要翻倍,也去问高斯林吧
如果非要不翻倍,也要保证数组长度仍然是 2 的指数
扩容过程
- 创建一个新数组,扩大一倍( << 也是翻倍,比 * 2 效率高)
- 原来的数据放到新的数组中,每个元素(包括链表中的元素)重新根据哈希算法算新的下标
- 因为是扩大两倍,所以如果原来元素是链表,这个链表最多拆分成 2 个链表,可以使用下面的公式快速拆分
哈希值 & 新数组长度的值可能是1个也可能是2个,如果是2个那就是要拆分成两个链表- 一组下标不变,一组下标加上数组长度(如果想不通,每次就硬算下标,结果肯定是一致的)
哈希算法
也叫 摘要算法、散列算法
将一种任意长度的数据通过一个算法,变成固定长度,这个固定长度就是 hash 值
说人话就是通过一个算法能给任意数据分配一个编号,这个编号就是 hash 值,编号是一个有限范围内的数字
一个好的哈希算法是要尽量避免产生的 hash 值重复(但是避免不了)
JDK 提供的 hash 算法是 Object 类的 hashcode 方法,这是一个 native 方法
算出来的 hash 值很大,通过取余换算成数组下标
哈希冲突
当不同数据的 hash 值一样,就是 hash 冲突了,取模后放入数组时怎么处理
- 拉链法:形成链表,缺点就是链表中的数据可能不连续(数组是连续的,数组中的链表保证不了连续)
- 开放寻址:按照某种探测方法寻找下一个空闲位置(尽量都放入数组,不让数组元素形成链表)
- 线性探测:找下一个下标位置是否为空,如果不为空就放进去。挨着找
- 二次探测:每次跳过一定的位置,如果不为空就放进去。跳着找
- 双重hash:再来另一个哈希算法来降低冲突
开放寻址的弊端就是冲突传递,比如你的车应该停在 5 号车位,去停车时发现 5 号车位已经有车了,那就找别的空闲车位,没车就停进去
当你选择的车位本来的车位主人来停车时发现:好家伙,给我占了,那我去占别人的(一旦有人占位,可能全都乱来)
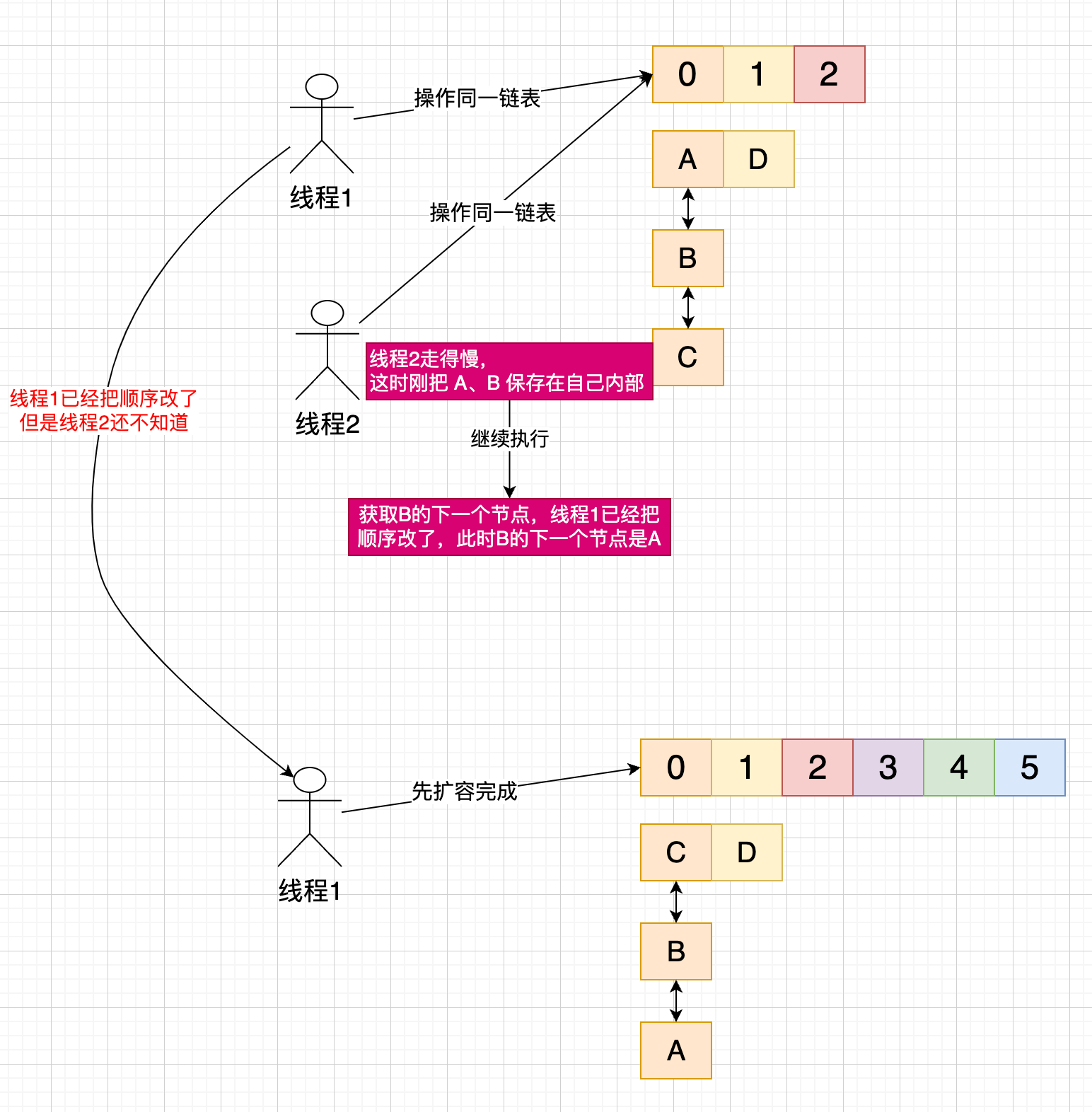
头插法 VS 尾插法
当使用链表解决 hash 冲突时,元素放在队尾(尾插)还是队首(头插)
JDK8 以前 HashMap 采用头插法在多线程极端情况下(多线程同时扩容,同时操作同一链表)有可能形成死链

 浙公网安备 33010602011771号
浙公网安备 33010602011771号