
B+Tree
B+Tree
B+Tree 是 B-Tree 的变种,所以 B+Tree 有很多 B-Tree 的特性。这里只说两者区别和 B+Tree 优势的地方
| 特性 | B-Tree | B+Tree |
|---|---|---|
| 非叶子节点存储内容 | 键(Key) + 子节点指针 | 同左 |
| 叶子节点存储内容 | 键(Key) + 数据 | 同左 |
| 叶子节点连接方式 | 无 | 通过双向链表串联所有叶子节点 |
| 数据存储位置 | 仅叶子节点存储数据 | 同左 |
| 键冗余 | 无(全局唯一) | 某些键同时出现在叶子结点和非叶子节点 |
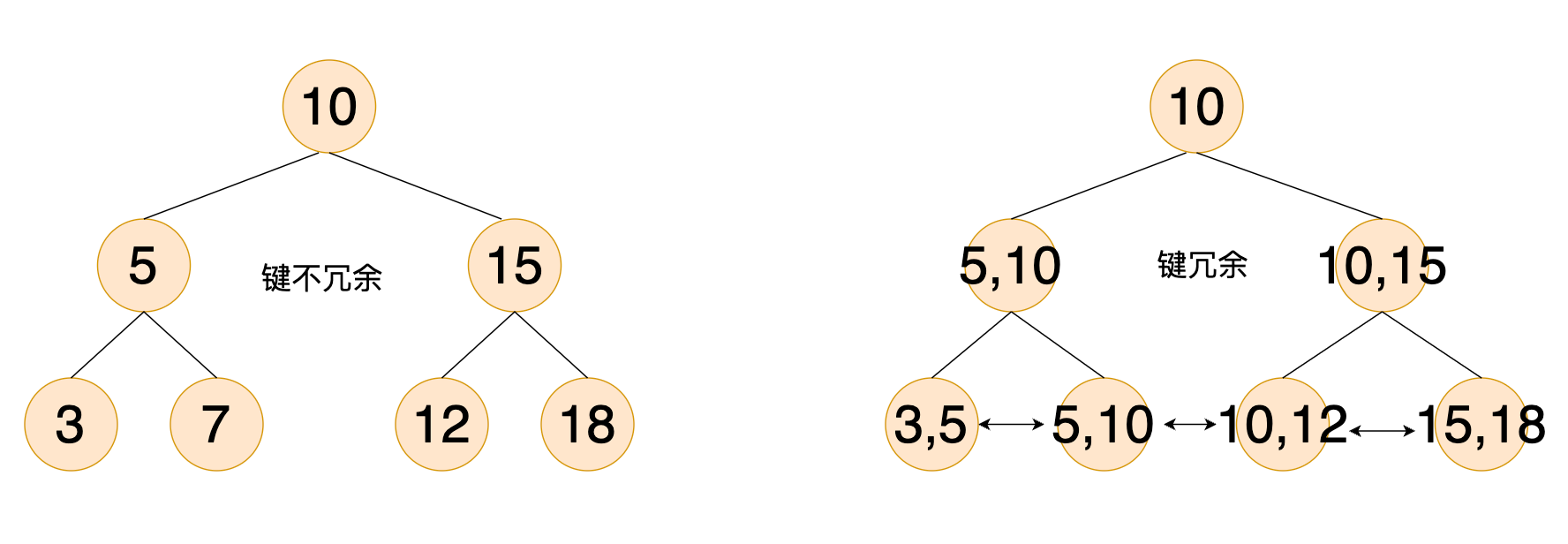
为什么 B+Tree 要设计为键冗余和叶子结点链表串联?
当范围查询时,比如 5 <= key <= 15,先定位到 5 所在的叶子节点,然后遍历链表就能得到数据(顺序I/O)。如果叶子节点不串联,只能回到上层再定位下层
当不是范围查询而是精确查找时,两者就是一样的了,典型的空间换时间
网上查找资料比较 B+Tree 和 B-Tree 时,几乎全网都站在 B-Tree 非叶子节点也存放数据的观点上,所以 B+Tree 比 B-Tree 优势就很多,比如
- B-Tree 非叶子节点也存放数据,所以相比 B+Tree 能存的键就少(数据页大小是固定的),所以树高更高,I/O 次数会更多
- B-Tree 非叶子节点也存放数据,B+Tree 一定到叶子节点才能拿到数据,所以 B+Tree 查询路径更稳定
- B-Tree 非叶子节点也存放数据,B+Tree 数据都是在叶子节点,所以 B-Tree 数据更分散
- ......
感觉都是疯了,因为前提都不成立,怎么能这样对比呢?
- MySql 使用了 B-Tree 吗?为什么使用 MySql 对比 B+Tree 和 B-Tree 就说非叶子节点也存放数据?
- B-Tree 这种数据结构定义时也没说 B-Tree 要包含数据,为啥要自我 YY 说非叶子结点放数据呢?
- 《MySQL 技术内幕:InnoDB 存储引擎》:InnoDB 使用 B+Tree 索引,所有数据记录都存储在叶子节点中
- 《算法导论》(第3版):B-Tree 的内部节点仅包含键和子节点指针,不存储卫星数据
- MySQL 官方文档:InnoDB 索引是 B+Tree 结构,非叶子节点仅用于导航
不过 MongoDB 使用 B-Tree 时非叶子节点确实存放了数据,但这并不是标准的 B-Tree 结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号