mysql 存储引擎和索引
存储引擎
| 引擎 | 特性 | 文件 |
|---|---|---|
| InnoDB | 默认,支持事务,支持外键,支持行锁和表锁 | .frm 文件存储表结构 .ibd 文件存储数据和索引 |
| MyISAM | 不支持事务,不支持外键,只支持表锁不支持行锁 专门维护了一个常量保存每个表的总记录数(count 很快) MyISAM 强调的是性能,所以性能上优于InnoDB,但安全性和并发性较低 |
.frm 文件存储表结构 .MYD 文件存储数据 .MYI 文件存储索引 |
| Memory | 数据存在内存中,所以性能上来看是最好的,缺点也很明显,一旦宕机数据就没了 | 只有表结构文件(只有 frm 文件) |
索引
索引是一种数据结构,目的是提高检索数据的效率,减少磁盘I/O,也是一个文件存放在磁盘中(Memery 这种引擎数据都在内存中,索引也不可能有实质的文件了)
有利有弊,索引也是需要维护的,所以索引越多维护的成本也增大
按照不同的规则可以划分出不同的类型,比如按照字段个数:单列索引,复合索引;是否主键:主键索引,非主键索引。按照索引的数据结构上又能分为:聚簇索引和非聚簇索引
| 索引类型 | 支持的存储引擎 | 数据结构 | 节点内容 | 特点 |
|---|---|---|---|---|
| 聚簇索引/主键索引 | InnoDB | b+tree | 叶子节点存放整行数据 非叶子存放主键和数据页的关系 |
一半不超过3级,因为3级都差不多上亿的数据量了 主键如果没有顺序,插入效率会很低,因为索引是有序的,所以没有序的数据可能要修改整棵索引树 |
| 非聚簇索引/辅助索引/二级索引 | InnoDB | b+tree | 和聚簇索引的区别是:叶子节点只存放主键 | 可能会回表(符合索引下推就不回表) |
| MyISAM 索引 | MyISAM | b+tree | 和聚簇索引的区别是:数据对应在硬盘的地址 | 一定会回表,因为索引和数据文件都不是同一个 可以没有主键,因为不支持聚簇索引 |
| Hash 索引 | Memory | hash | 数据结构类似 java 的 HashMap,根据 key 算下标,然后取数据,大多数情况下时间复杂度是 O(1),查询效率相当高 |
- b-tree 是一种数据结构,这种数据结构是叶子节点和非叶子节点都可能存放数据。但是数据库索引没有采用这种结构!
- 为什么非聚簇索引叶子不也放整行数据,这样就能避免回表?数据冗余,比如10个非聚簇索引,就要放11份数据
- InnoDB 能不能使用 Hash 索引?不能手动创建 Hash 的索引,但是如果是访问频繁的数据,内部会自动构建一个自适应哈希索引
- 既然 Hash 索引查询效率高,为什么 InnoDB 不使用 Hash 要用 B+Tree?
- 根据 key 得到下标然后得到数据的,如果是 like 或者范围查询就 gg 了,因为 key 都不是常量
- 默认查询的结果集是没有顺序的,如果要 ORDER BY 内部会再次对结果集进行排序计算
- 如果是联合索引,hash 值是多个列联合计算的,无法根据其中的一个列进行索引
InnoDB 聚簇索引数据结构
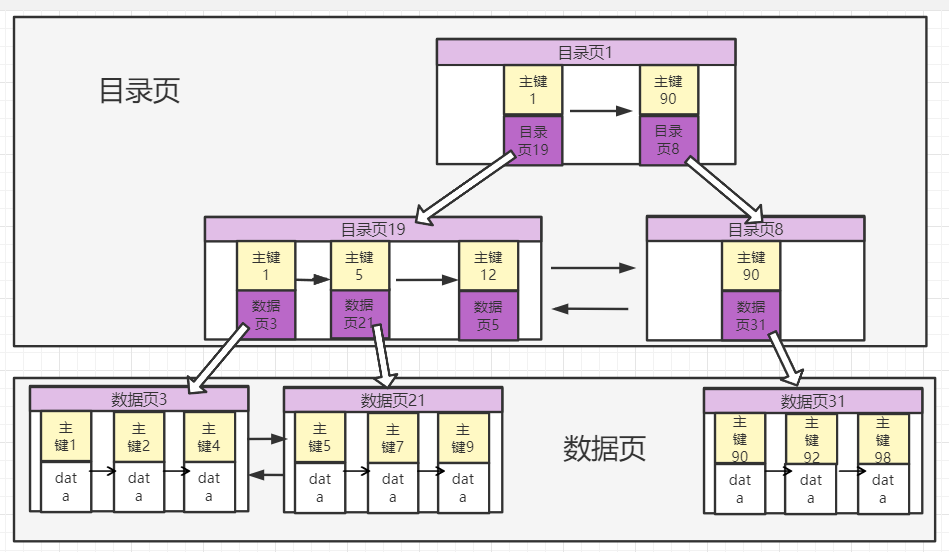
- 索引的数据结构是 b+tree,每个数据页(目录页)是双向链表,数据页里面的数据是单向链表,为什么是 b+tree 后面会说到
- 计算机与磁盘交互的基本单位是数据页(图中目录页也是数据页,为了区分 bTree 的叶子节点和非叶子节点的叫法而已),每个数据页大小16k
- sql 不管走不走索引都要发生磁盘交互,因为索引也是文件。数据会放在多个数据页,索引的目的是提高检索效率减少磁盘IO次数
- 比如要找 id=9 的数据,查询过程如下:
- 先到根节点的目录页,里面是个单向循环链表,能确定在目录页19
- 目录页19 里面的节点也是单向循环链表,能知道数据位于数据页21
- 到数据页21 里面得到 id=7 的数据
b+tree 和 b-tree
B+Tree 只是叶子节点才存放数据,B-Tree 非叶子节点也可能存放数据,因为数据页的大小是固定的 16k,所以 B-Tree 更高瘦
B+Tree 查询更稳定,正因为有的数据放在目录页,而一个页的大小又是固定的,所以快的时候效率高有的时候就比较低

 浙公网安备 33010602011771号
浙公网安备 33010602011771号