垃圾回收器
工作模式
-
串行、并行(吞吐量)
垃圾回收期的线程数量,如果是一个就是串行,如果是多个就是并行
-
并发式、独占式(STW时间,响应优先,低延迟)
- 垃圾回收器的线程工作期间,用户线程要暂停,就是独占式
- 如果和用户线程一起执行就是并发式(不是真的一起工作,而是把垃圾回收的时间打散,比如垃圾回收要10s,分成 5 次执行,每次 2s,这5次中,有真正同时运行的,也有用户线程还是要暂停的)
GC 指标
- 吞吐量:吞吐量 = 用户线程运行时间 / (用户代码运行时间+GC 时间) ,越大越好
- 暂停时间:STW 的时间,越小越好
- 内存占用:堆区使用量,如果长时间占用过大,要考虑是否内存不够
- 收集频率:触发 GC 的频率,特别是 Full GC 如果频率过高是要进行优化的
没有一种垃圾收集器可以满足所有指标,就像微服务的 CAP 一样
垃圾回收器
7 种垃圾回收器适用区域
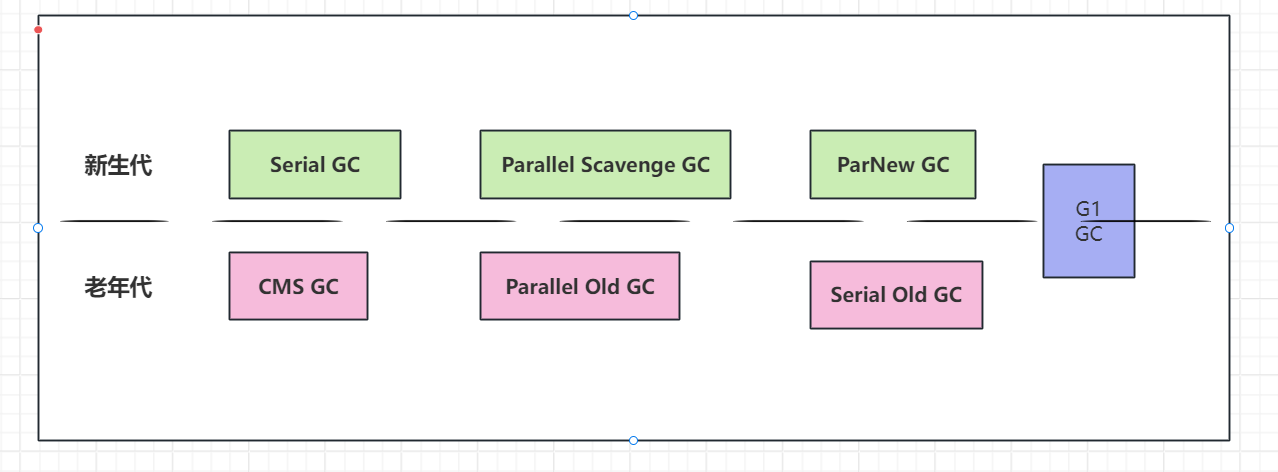
历史 7 种垃圾回收器搭配关系
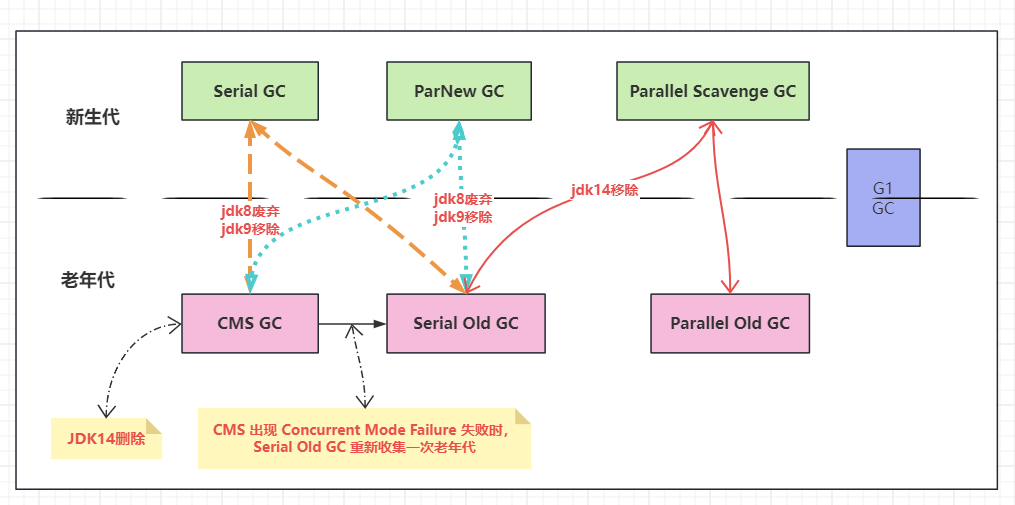
jdk8 7 种垃圾回收器搭配关系
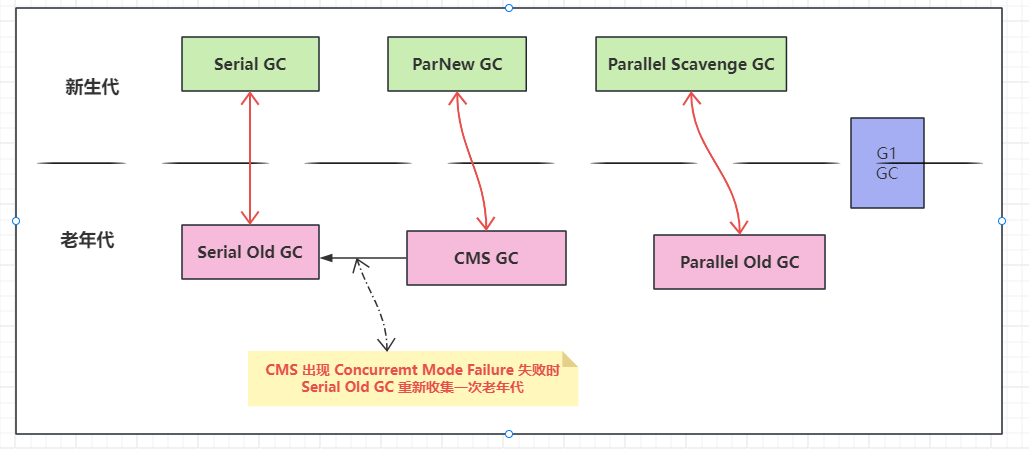
为什么有这么多收集器?
算法有 3 种,算上分代有 4 种,不同的收集器用不同的算法
还有服务器的配置是不一样的,比如有的是单线程、有的内存大有的内存小
有的 java 程序是用于移动端在意吞吐量,有的用于服务端在意高并发
总结来说就是场景太多了,又不可能用户自己实现一个垃圾回收器,所以就定了好几种,让用户自己挑选合适的
7 种垃圾回收器区别
从工作模式区分
- 串行回收器(单线程):Serial、Serial Old
- 并行回收器(多线程):ParNew、Parallel Scavenge、Parallel Old
- 并发回收器(低STW时间、高吞吐量):CMS、G1
| 收集器 | 适用场景 | 特点 |
|---|---|---|
| Serial | 新生代 | 单线程、使用复制算法 |
| Serial Old | 老年代 | 单线程、使用标记-压缩算法 |
| ParNew | 新生代 | Serial 的多线程版本,也是使用复制算法 |
| CMS | 老年代 | 多线程并发收集器,使用标记-清除算法,效率高+低延迟 |
| Parallel | 新生代 | jdk8 默认,和 ParNew 的区别是 Parallel 可以 自适应调整内存分配和吞吐量优先 |
| Parallel Old | 老年代 | jdk8 默认,Serial Old 的多线程版本,也是使用标记-压缩算法,Parallel Old 的目的就是为了替换 Serial Old |
| G1 | 新生代 and 老年代 | jdk9 默认,同时回收新生代和老年代,和 CMS 一样是并发垃圾回收器,使用 标记-压缩 算法 |
| ZGC |
ParNew 效率一定高于 Seria 吗?
不是的,比如单核 CPU 场景,Serial 效率更好
Parallel 和 ParNew 区别?
1,Parallel 能自适应调整内存分配,默认新生代的伊甸园和幸存区比例是 8:1:1,如果新生代使用 Parallel 可能不是 8:1:1,Parallel 会自动适当调整整个比例。
2,Parallel 还能设置吞吐量,默认是99,意思垃圾回收时间不超过1%,parallel 会尽可能利用硬件资源达到或高于这个比例,ParNew 没有这个设置项
CMS为什么不适用标记-压缩算法?
因为是并行收集器,垃圾回收和用户线程有同时执行的时候,如果移动对象,别的线程引用的对象就找对象了
Serial 和 Serial Old 没用使用场景了?
如果服务器硬件配置不高,比如 单 CPU 、内存比较小(几十到一两百MB)情况下,Serial 和 Serial Old 效果最好
CMS:Concurrent Mark-Sweep
是一款并发的,低暂停时间的垃圾回收器,旨在减少垃圾回收期间应用程序的停顿时间
- 对 CPU 敏感:因为是并发垃圾回收,要和用户线程一起工作,肯定对 CPU 核数很敏感了,如果单核 CPU 不建议用
- 无法处理浮动垃圾:浮动垃圾是指垃圾收集器标记一些对象可达(不是垃圾),在实际清理的时候这些对象又变为不可达了。独占式的垃圾回收器基本不会出现这种情况,因为 CMS 是并发的,和用户线程一起工作,所以这种情况比较容易发生,对于 CMS 来说,清理浮动垃圾只能等到下一次工作时才能回收
- Concurrent Mode Failure:还是因为并发回收垃圾,CSM 工作的时候,用户线程也在工作,所以不能像其他垃圾收集器等老年代满了或快满了才开始回收,要预留一些内存给用户线程,具体留多少,这是一个阈值,可配置的,CMS 默认是 80%,也就是说 CMS 默认在老年代使用率达到 80% 左右就开始 GC。当预留的空间不够用户线程使用,就出现 Concurrent Mode Failure,这时需要 Serial Old 再重新回收一次老年代
- 内存碎片:成也萧何败也萧何,因为使用的 标记-清除 算法,虽然你效率非常高,但是会产生内存碎片。加上 CMS 是当老年代使用率达到 80% 就 GC,进一步压缩可使用的空间,会增大 Concurrent Mode Failure 几率
虽然 CMS 是有弊端,总体在当时或者现在相比其他垃圾收集器,还是有很多优点的,所以 CMS 目前使用还是比较广泛的,G1 出现之前使用更广泛。技术是在不停发展的,垃圾收集器也是,CMS 优缺点就要改进(没缺点也会随着时间推移进行优化升级),JDK 14 中已经删除了 CMS,不是废弃或弃用,是直接删除了
G1: Garbage First
-
与 CMS 一样也是并发垃圾回收收集器,即用户线程和垃圾回收线程同时工作,所以也具有低延迟、高吞吐量的特点
-
原理是把 JVM 堆空间分成不同的区域(region),每个 region 有不同的标识,比如一些 region 意义上等价于新生代;一些 region 等价于老年代
忘记原来的 jvm 内存结构!!!G1的内存结构如下:
![]()
-
G1 是以 region 作为单来来回收,Rrgion 之间是复制算法,总体来看是标记-压缩的算法,这两种算法都会避免产生内存碎片
-
使用
- 需要手动指定垃圾回收器为 G1
- 可以设置每个 region 的大小,大小为2的指数,范围是 1M-32M 之间
- 可以设置最大的延迟时间,默认是 200ms,如果回收垃圾需要 500ms,G1 只执行 200ms,这样垃圾回收不完,G1 的策略是尽量保证低延迟,回收垃圾时优先回收大对象。这样兼顾最小停顿时间和最大释放内存
- 只需要设置到新生代、老年代、region 的大小和最大延迟时间就行了,不用再设置伊甸园和幸存区的比例,不是不能设置,是没多大用,因为有可能回收不完,G1 会根据最大停顿时间来回收
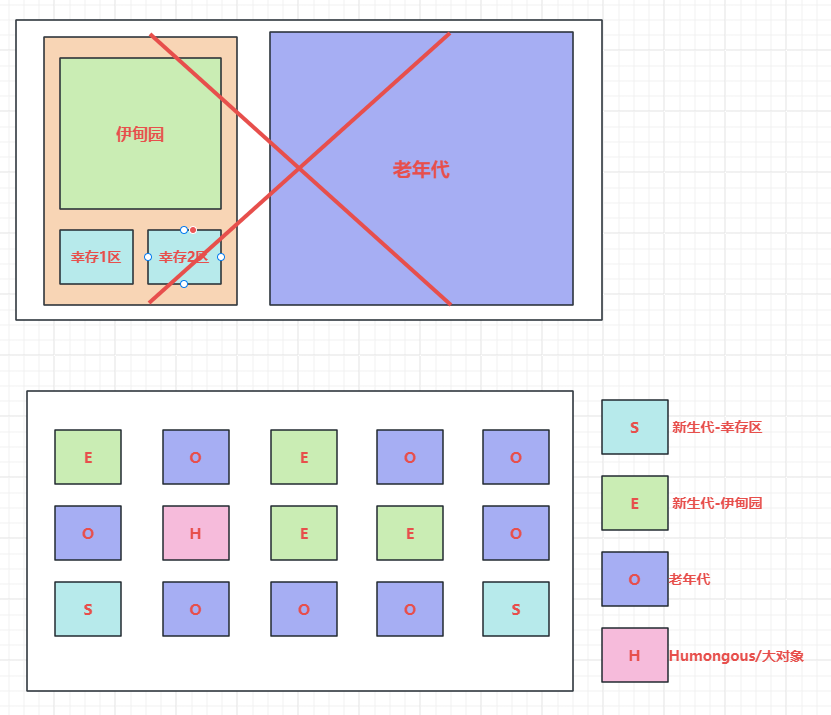
CMS 与 G1
- CMS 使用 标记-清除 算法,多次内存清理后使用 Serial Old 压缩一次空间;G1 总体看使用的是 标记-压缩 算法避免了大量内存碎片的产生
- CMS 内存结构还是传统的老年代、新生代(伊甸园、幸存区);G1 也有老年代、新生代的体现,但是最小单位是 Region
- CMS 只能回收老生代,还要搭配 Serial Old 使用;G1 是新老年代都能回收
- G1 可以设置最大 STW 时间,在设置的时间内优先回收大对象
- 都是并发回收器,都具有低延迟高吞吐量的优点,但是 G1 并不完美,比如只要是并发垃圾回收器就不能处理浮动垃圾,G1 也是如此,垃圾回收器是在不断发展的过程,ZGC 这种垃圾回收器才是未来

 浙公网安备 33010602011771号
浙公网安备 33010602011771号