内存结构
组成结构
-
线程私有:程序计数器、本地方法栈、虚拟机栈
-
线程共享:方法区、堆
程序计数器
线程私有,存储下一条字节码指令的行号
- 也叫 PC 寄存器,存储下一条要执行的指令行号(如果下一条指令是 native 方法,记录的行号是 undefined)
- class 最终被编译成字节码指令,CPU 能执行的内容
- 每个线程是要拥有 CPU 时间片才会执行的,时间片结束就不能执行了,如果程序还没执行完,就要先挂起,并记录行号,等下一次拥有时间片的时候继续执行(上下文切换的体现)
- 再比如条件判断、循环等操作,下一条指令是哪个条件,或者是否跳出循环等,都需要记录在线程内部
- 线程私有,生命周期跟随线程的创建和结束,线程一定有自己的程序计数器,线程销毁,程序计数器也被销毁
- jvm 中 唯一一个不会出现 oom 的区域
虚拟机栈
线程私有,存放栈帧,一个栈帧就是一个方法,栈帧里面主要存储当前方法需要操作的局部变量和操作数栈
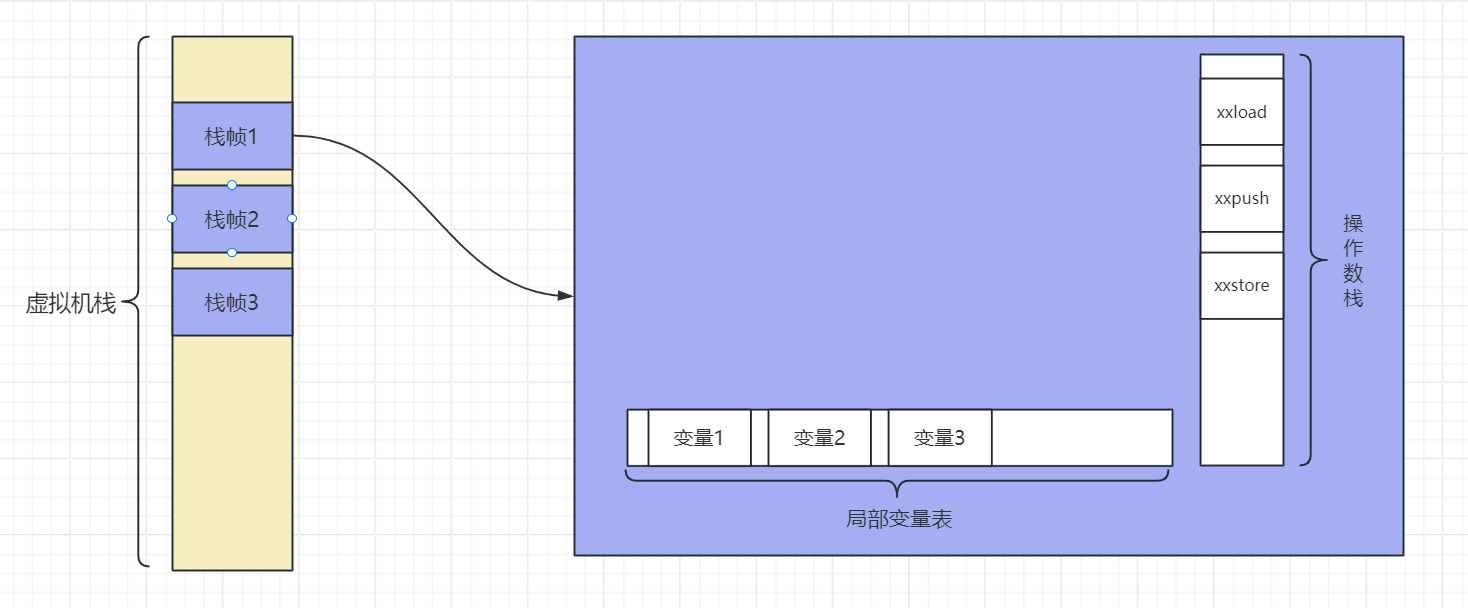
- 在线程增加一个方法调用叫做栈帧入栈,调用完一个方法,这个方法就出栈
- 既然栈帧对应方法调用,那么栈帧里面存储的就是方法调用的相关信息
- 局部变量表:存储方法形参和定义在方法体内部的局部变量
- 操作数栈:对局部变量进行操作的行为列表,比如读取局部变量表的数据到操作数栈,对局部变量表的数据进行运算比较等
- 动态链接
- 方法返回地址
- 运行速度很快,但是空间不大,jdk5 之前一个线程默认 256k,jdk5 之后 默认1 M(可自定义每个线程默认大小)
局部变量表
- 非静态方法还有 this,静态方法没有 this,所以静态方法不用用 this 的原因就是栈帧里面没有 this 这个变量
- 局部变量也不会赋初值,成员变量才会赋值(意思就是方法里面定义的变量一定要赋值)
- 局部变量表的对象变量是 GC Root 对象
操作数栈
- 比如局部变量表有一个 a,操作数栈可以是读取a,把a+1,然后再更新回局部变量表的值
- load、puah 指令是把局部变量压入操作数栈(读取变量,操作数栈深度+1)、store 把新的变量写入局部变量表(修改变量,操作数栈深度-1)
常见面试问题
问题1:栈会内存不足吗?
会
- JVM 默认一个线程大小是固定的,可以指定大小,当超过指定的大小就会发生栈溢出,StackOverflow
- JVM 也能允许配置线程大小是动态扩展的,当物理内存不够发生 OOM
问题2:真内存越大越好吗?
不是,因为增加栈大小,就会减少栈的数量
问题3:栈会垃圾回收吗?
不会,为什么不会?去问高斯林,JVM 更多的是规范,因为作为应用开发,这些都属于底层理论知识
问题4:为什么要区分堆和栈,栈速度很快,何不把堆的数据放到栈中?
- 栈空间不大,要是存放真实对象很容易内存不足
- 有些对象是线程共享的
- 栈管运行,堆管存储
问题4:方法中定义的局部变量是否是线程安全的?
不是,局部变量如果是一个对象,局部变量表的变量是一个引用地址,别的线程可能也引用这个变量
本地方法栈
和虚拟机栈类上,不过栈帧是 native 方法
方法区
- 存放类信息,比如类型、方法、成员变量等(常量池)
User user = new User();User:方法区;user:栈;new User():堆 - 逻辑上属于堆,实际上不属于堆
- 垃圾回收效率最差(新生代最快,老年代次之,方法区最差)
- 1.7 之前叫永久代;1.8开始叫元空间(什么地方存放类信息,这块区域就叫方法区),永久代使用的堆内存,元空间使用的是本地内存
- 不管永久代还是元空间,静态变量和运行时常量池都是放在堆中的(运行时常量池,就是字符串字面量;还有个常量池,这是描述类的信息,别混淆了)
堆
一个jvm实例只有一个堆,所有线程共享;jvm 管理的最大的一块内存,垃圾回收的主要区域
常见面试题
问题1:所有栈帧的引用对象都在堆上吗?
不是,TLAB
问题2:方法调用结束,方法引用的对象立马就回收吗?线程销毁后,线程里引用的对象立马被回收吗
不是,仅在 GC 时且对象被判定为垃圾时才回收
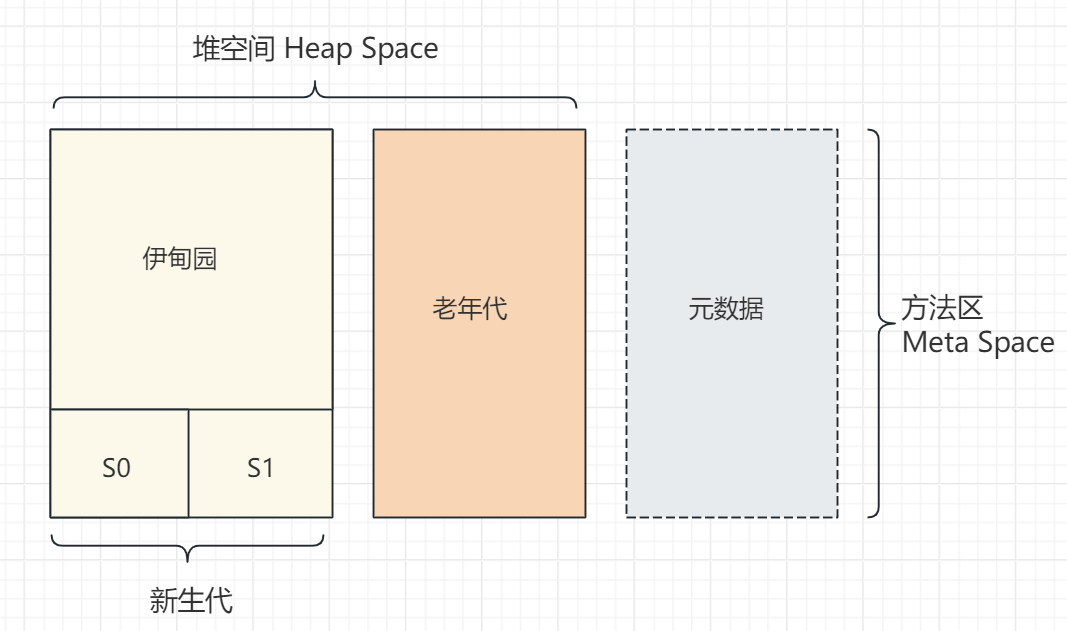
问题3:java 堆的结构是什么样子的?
- 新生代:伊甸园、幸存区(幸存区又分为两个区,s0 和 s1,或者 from 和 to )
- 老年代
- 方法区(逻辑上属于堆,实际上不属于堆)
问题4:java 为什么要分成新生代,老年代,持久代?新生代中为什么又要分为 eden 和 survivor?
为了垃圾回收性能和效率,如果不分区,所有对象在一次,每次回收都要扫描很大的内存空间
- 老年代都是存活比较长的对象,并且区域也很大所以回收效率不高
- 大多数对象都是在新生代创建和回收,所以这里 GC 频率很高,且回收效果也很明显
- 幸存区分为两个区的原因是,幸存区使用标记复制的垃圾算法最合适

 浙公网安备 33010602011771号
浙公网安备 33010602011771号