kafka 消费者
消费者组
kafka 使用消费者组来控制消费组消费,每个消费组都可以消费 topic 的全量信息,消费组内部的消费者再各自进行引流,消费不同的分区信息。
消费者从属于消费组,一个组里的消费者订阅的是相同的主题,每个消费者接收主题一部分的分区的消息。
一个消费者组只有一个消费者的情况
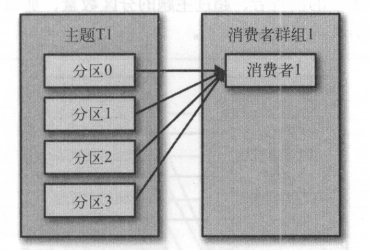
如上图,主题 T1 只有一个消费者组订阅,并且消费者组只有一个消费者,那么这个消费者消费 T1 的所有分区消息。
一个消费者组的消费者数量小于分区数量的情况
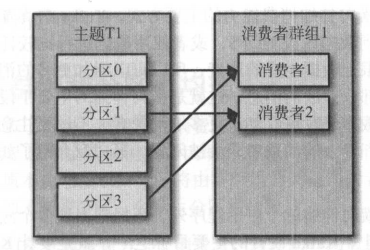
如上图,当一个消费者组里的消费者数量小于主题分区的数量,那么每个消费者都会负责消费多个分区的消息
一个消费组的消费者数量等于分区的数量的情况
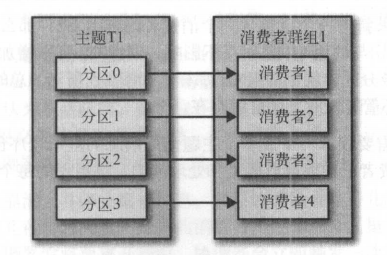
如图,当一个消费组里的消费者的数量与主题的分区数持平的时候,每个消费者负责一个分区
消费组的消费者数量大于分区数量的情况
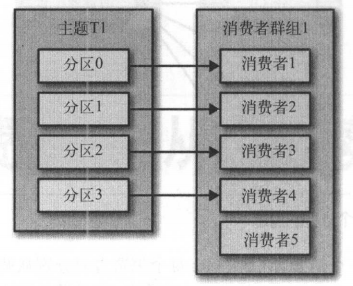
如上图,当消费者组里的消费者数量大于分区数量,那么多出来的那一部分消费者就会被闲置,接收不到消息。
因此,最好的情况是组里的消费者的数量和主题分区数持平的情况,这种情况吞吐量最高
多个消费组的情况
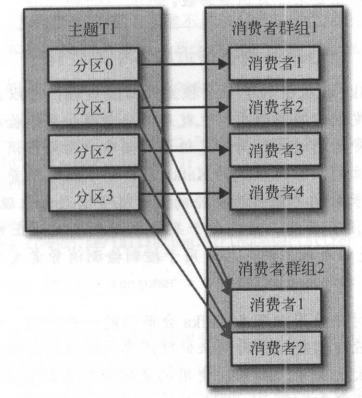
当有多个消费组的时候,每个消费组都会全量消费主题的所有分区的消息,如上图,组 1 全量消费主题 T1 的消息,由于组1 的消费者数量和分区数持平,所以每个消费者负责消费一个分区的消息。组 2 也全量消费主题 T1 的消息,但是组 2 只有两个消费者,因此每个消费者负责 2 个分区的消息。
消费者代表什么
在线上环境中,消费者一般是由一个单独的线程开起来的,但是更常见的是在分布式服务场景中,一台服务器开一个线程负责消费消息,多台服务器组成一个消费组。也就是说一个集群组成一个组,集群中的每台机器都是一个消费者,这种组合是最常见的。
分区再均衡
当我们的消费组里的消费者数量少于分区的数量的时候,一个消费者负责多个分区,这时候如果消费速度过慢,我们可以对消费组进行水平扩容,就是增加组内消费者的数量,可以多开几个线程也可以多加几台机器,当然,消费者数量最好和分区数持平,不要超。
当然,在由新的消费者加入群组或者旧的消费者由于某些原因宕机了离开了消费组,就会触发分区再均衡,重新分区每个消费者应该负责的分区,这里要介绍几个概念。
- 群组协调器
每个消费者组都有一个群组协调器,由某一台 broker 组成,不同的消费者组可以拥有不同的协调器。
- 群主
第一个加入消费者组的消费者会自动成为群主,负责平衡各个消费者的分区的情况,同时与群组协调器进行协调。
具体的工作场景是这样的:
群主会从协调器获取到所有活跃的消费者进行,通过自己的分区策略来给每个消费者进行分区分配,分配好后告诉协调器,协调器再把这些消息告诉每个消费者,消费者只能看到自己负责的消息,群主知道所有消费者的一个情况。这个过程会在再均衡的时候重新发生。
再均衡时机
- 当有新的消费者加入到组内的时候
- 消费者崩溃
- 消费者主动离开群组
独立于群组之外的消费者
kafka 并没有规定必须加入某个群组才能消费消息,消费者可以不指定群组,可以自己指定要消费的主题分区,可以消费某个主题的特定分区,或者多个主题的多个分区。当然,脱离了群组后自然也就没有分区再均衡的概念了。
订阅与消费消息
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
如上代码,前面的 Properties 对象很熟悉。和创建生产者时候类似,有个变动是 group.id 参数,代表消费组的名字。
KafkaConsumer 是生成一个消费者对象,subscribe 方法是开始订阅消息,入参是 topic 名称,这里是 foo 和 bar 两个主题。
轮询
当然上面只是简单的创建消费者和订阅主题,并没有开始消费,拉取数据是在轮询的时候做的
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
如上代码,消费者是一个长期运行的程序,所以在一个无限循环里拉取数据梳理数据,kafka 客户端有它优雅的退出方式。
poll(time)方法很重要,很多事情都是在这里做的,后面会介绍。这里的参数是一个超时时间,当分区没有数据的时候,会阻塞等待数据,当超时了,不管有没有数据都会返回。这里展示的就是通过 poll 拉取到数据,每条消息都被构造成了 ConsumerRecord 对象,有偏移量、key、value等信息。
再来说说 poll 方法,在第一次调用 poll 的时候,会找到群主协调器,加入群组,获取到自己的分区。如果发生了再均衡,重新规划分区也是再 poll 的过程中进行的。
轮询与心跳
在老版本中,心跳是在轮询的时候发送的,这样会有一个弊端,当消费处理过程太过复杂,每批消息都要很久才能消费处理完,这样两次轮询就会间隔很久,超过一个会话超时时间,broker 会认为这个消费者死亡,触发再均衡,处理完后重新请求,broker 又会让他加入群组,触发再均衡,就会频繁的触发再均衡。
新版本中,心跳线程和轮询线程独立开了,两者没有关系了,心跳线程维持一个会话时间,控制会话不超时。轮询之间的间隔也有自己的参数控制,如果间隔太久了,就认为挂了,不管心跳有没有正常发送。当然,心跳停止发送了,会话超时了,也会认为挂了。
偏移量
讲到这里,我们会有一个疑惑,触发再均衡的时候,新的消费者拿到新的分区,怎么知道从哪里开始消费呢,是从最新位置开始消费还是从最早位置开始消费。其实都不是,从最早位置开始消费的话,由于中间很多消息分区的上一个拥有者已经消费过了,会造成重复消费的情况。从最新位置开始消费,上一个消费者停止消费的消息到最新的消息中间的消息就会丢失了。因此,kafka 维护着一个偏移量,用来控制该分区被某个消费者组消费到了哪个位置了。
老版本中这个偏移量是维护再 zookeeper 中的,但是由于提交偏移量的频率很频繁,所以为了降低对 zk 的压力,在新版本中可以将偏移量维护在 broker 中。
偏移量有以下几种提交方式
- 自动提交
- 同步提交
- 异步提交
- 提交特定偏移量
自动提交
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
这是一个自动提交偏移量的例子,参数中的 enable.auto.commit 需要设置为 true。
自动提交是每过 5s 消费者就会把从 poll 中拉取到的最大偏移量提交上去,这个时间是由 auto.commit.interval.ms 进行控制的,默认是 5s。当然,自动提交也是在轮询中进行的,消费者在每次进行轮询的时候都会检查一下是否该提交偏移量了,如果是,它就提交上一次返回的偏移量。
当然,这种情况会造成重复消费的情况,5s 提交一次偏移量,如果再第 3 秒时候消费者宕机了,偏移量没有提交,但是这 3s 的数据已经处理了,下次消费的时候这 3 秒数据就会被重复消费,可以调低 auto.commit.interval.ms 参数,当然,无法根治这个问题。正常来说是不会有什么问题的,就是出现异常的时候或提前退出轮询的时候容易出现问题。
同步提交
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
}
我们可以让应用程序来决定什么时候提交偏移量,通常是在处理完一批消息的时候提交。通过 commitSync() 方法会提交由 poll 返回的最新偏移量。成功后马上返回,失败后抛出异常。当成功提交或者碰到不可恢复的异常前,commitSync 会一直不断的重试。
手动提交有个弊端,在 broker 对消费者做出回应之前会阻塞住,对吞吐量不太友好。
异步提交
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitAsync();
buffer.clear();
}
}
异步提交失败的时候不会进行重试,提交就提交了,但是也可以像生产者异步发送消息一样有回调信息,用来记录错误日志等。不重试的原因是因为就算这次提交失败了,可能有偏移量更高的提交成功了。
异步和同步组合提交
一般来说异步和同步是可以组合起来使用的,如果在运行期间,没有问题产生的时候使用异步提交,提高吞吐,在直接关闭消费者的时候,使用同步提交,保证偏移量的提交成功。
提交特定偏移量
有的时候我们需要提交特定的偏移量,自己控制提交的速度,在批次中间提交偏移量,而不是每次 poll 的时候提交偏移量,这时候就需要我们自己记录偏移量,然后手动提交。可以使用带参数的 commitSync 和 commitAsync,参数就是分区偏移量信息。
再均衡监听器
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"), new ConsumerRebalanceListener() {
// 在再均衡开始前和消费者停止读取消息时调用
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
}
// 重新分配分区后,消费者开始消费前调用
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
}
});
如上代码,在订阅消息的时候传入一个 ConsumerRebalanceListener 接口的实现者,这个接口就是再均衡监听器,其中有两个方法:
onPartitionsRevoked:在再均衡开始前和消费者停止读取消息时调用
onPartitionsAssigned:重新分配分区后,消费者开始消费前调用
这两个方法可以在开始消费前和停止消费后进行一些自定化的操作。
从特定位置开始消费
-
seek(TopicPartition, long):从指定位置开始消费
-
seekToBeginning(Collection):从分区头部开始消费
-
seekToEnd(Collection):从分区尾部开始消费
有时候我们想要自己保存偏移量,不使用 kafka 内置的 offset 仓库,比如消费的结果存储在数据库中,可以让 offset 也存储在数据库中,这时候 offset 的提交时处理结果的提交就是在一个事务中,一起成功,一起失败。
这时候我们在再均衡的时候就需要手动的指定分区的 offset,从指定的位置开始消费这时候就可以通过上面的 ConsumerRebalanceListener 再均衡监听器,订阅的时候,开始消费前,指定要开始消费的分区的位置。
配置
fetch.min.bytes
消费组从服务器获取记录的最小字节数,不到这个数量,则阻塞等待数据
fetch.max.wait.ms
如果没有足够的数据流入 broker,等待 broke 的时间,超时将返回
上面两个参数共同作用,谁先满足就停止阻塞,返回消息。
max.partition.fetch.bytes
从每个分区返回的最大字节数,可以控制消费速度,过大会导致一批数据处理的时间过长,导致下次 poll 的时间过久。
session.timeout.ms
会话超时时间,超过这个时间没有发送心跳,那么就认为死亡。触发再均衡。
enable.auto.commit
消费组是否自动提交
partition.assignment.strategy
分区分配策略,指定给群主分区分区使用的,有两种模式
- range:把主题的若干个连续分区分配给消费者,可能会出现某个消费者分区远远大于其他消费者的情况
- roundRobin:把主题的所有分区逐个分配给消费者,每个消费者的分区比较均匀
max.poll.records
单车poll返回的记录数量
反序列化
生产者序列化消息,那么消费者肯定也会反序列化消息啦,这块不做过多描述,有兴趣的自己查阅资料。
总结
消费者消费的时候也是有很多自己可以控制的项目,比如提交偏移量的时机、从分区开始读取消息的位置等等,有很大的配置空间,但是其实大部分使用场景使用默认的配置就已经满足条件了,真的出现了问题了解原理定位问题解决问题也能够很快。
ps
文章为本人学习过程中的一些个人见解,漏洞是必不可少的,希望各位大佬多多指教,帮忙修复修复漏洞!!!
通过本人语雀文档阅读体验更好哦
你可能还想了解:
kafka 概述
kafka 生产者
参考资料
《kafka 权威指南》

