docker 基础入门
什么是docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
为什么使用docker
之前的虚拟化技术
虚拟机技术缺点:
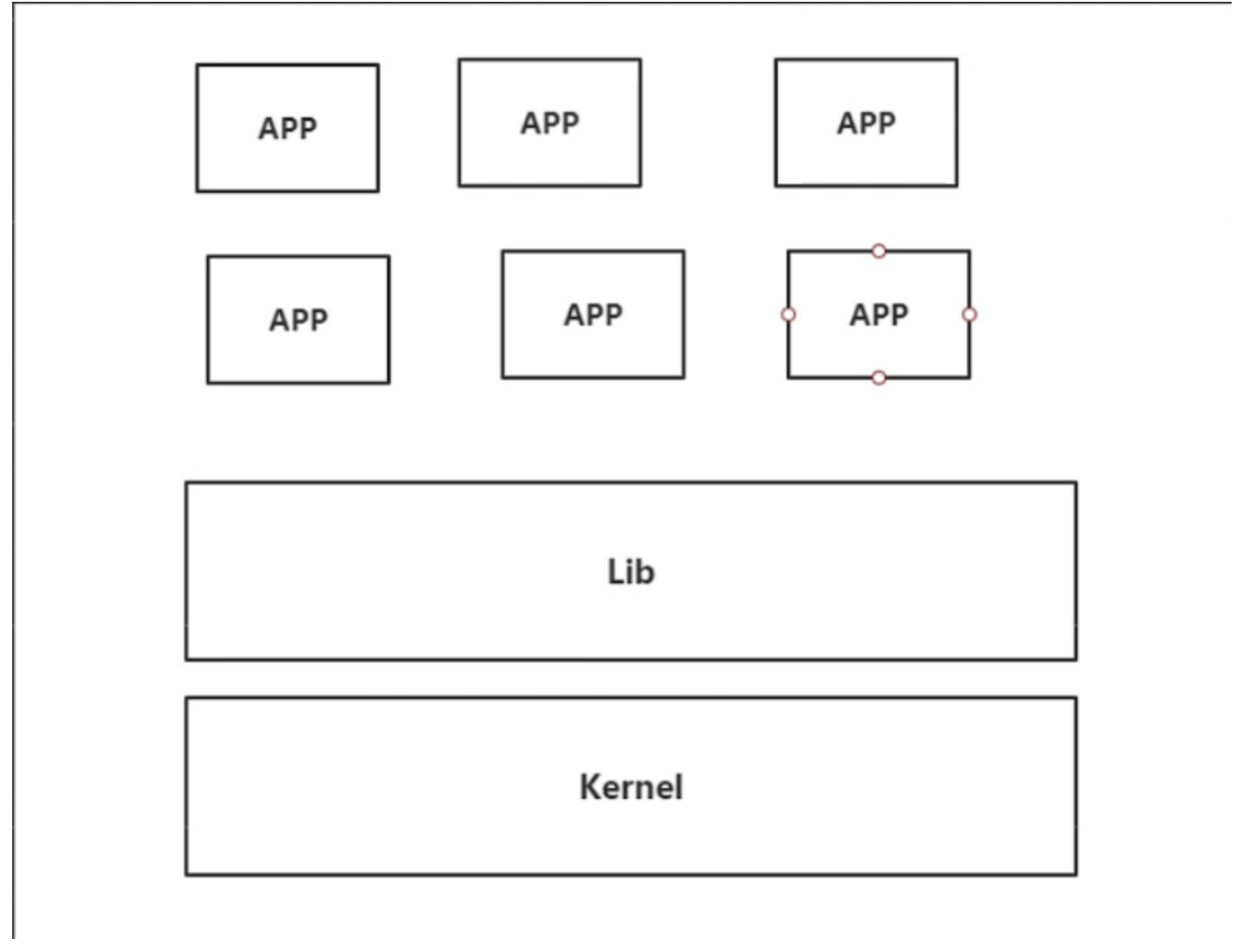
- 资源占用大
- 冗余步骤多
- 启动慢
容器化技术
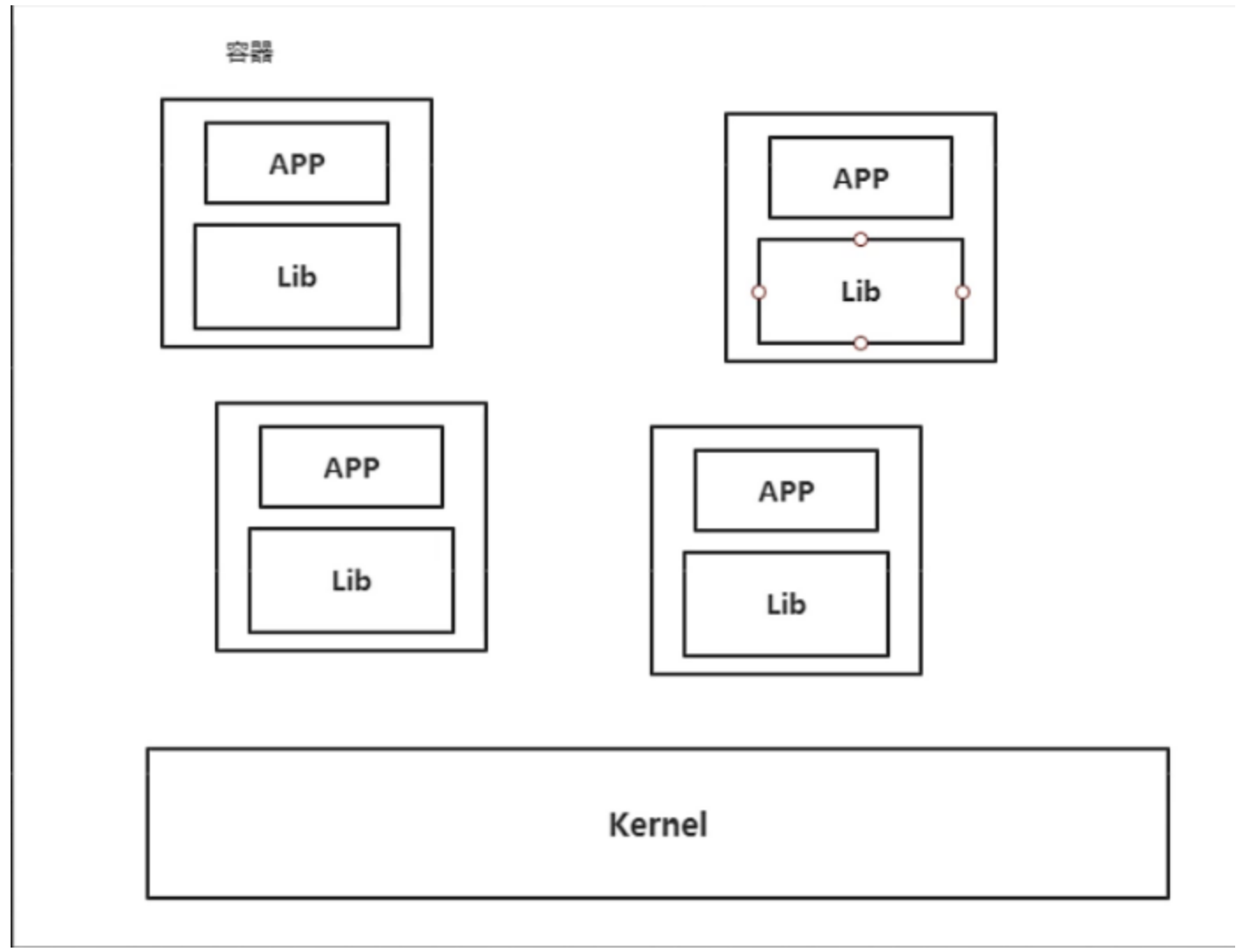
- 传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程
- 容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便
- 每个容器间是互相隔离的,都有一个属于自己的文件系统
DevOps (开发和运维)
更高效的利用系统资源
由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,Docker 对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。
更快速的启动时间
传统的虚拟机技术启动应用服务往往需要数分钟,而 Docker 容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
一致的运行环境
开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而 Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 「这段代码在我机器上没问题啊」 这类问题。
持续交付和部署
对开发和运维(DevOps)人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。
更轻松的迁移
由于 Docker 确保了执行环境的一致性,使得应用的迁移更加容易。Docker 可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的。因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
更轻松的维护和扩展
Docker 使用的分层存储以及镜像的技术,使得应用重复部分的复用更为容易,也使得应用的维护更新更加简单,基于基础镜像进一步扩展镜像也变得非常简单。此外,Docker 团队同各个开源项目团队一起维护了一大批高质量的 官方镜像,既可以直接在生产环境使用,又可以作为基础进一步定制,大大的降低了应用服务的镜像制作成本。
对比传统虚拟机总结
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为 MB |
一般为 GB |
| 性能 | 接近原生 | 弱于 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
docker基本概念
镜像
我们都知道,操作系统分为 内核 和 用户空间。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而 Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:18.04 就包含了完整的一套 Ubuntu 18.04 最小系统的 root 文件系统。
Docker 镜像 是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像 不包含 任何动态数据,其内容在构建之后也不会被改变。
分层存储
因为镜像包含操作系统完整的 root 文件系统,其体积往往是庞大的,因此在 Docker 设计时,就充分利用 Union FS 的技术,将其设计为分层存储的架构。所以严格来说,镜像并非是像一个 ISO 那样的打包文件,镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由多层文件系统联合组成。
镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
容器
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机。
前面讲过镜像使用的是分层存储,容器也是如此。每一个容器运行时,是以镜像为基础层,在其上创建一个当前容器的存储层,我们可以称这个为容器运行时读写而准备的存储层为 容器存储层。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 数据卷(Volume)、或者 绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失。
仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,如Docker Hub。
docker安装
这里我选择安装 CentOS7 版本
1. 卸载旧版本
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
2. 使用 yum 安装
# 安装 yum 依赖包
sudo yum install yum-utils device-mapper-persistent-data lvm2
# 为 yum 配置阿里源
sudo yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 更新 yum 软件源缓存
yum clean all && yum makecache
3. 安装 docker
# 默认安装
sudo yum install docker-ce docker-ce-cli containerd.io
# 指定版本安装
...
# 启动 docker
sudo systemctl enable docker
sudo systemctl start docker
4. 测试 docker
docker run --rm hello-world
docker version
docker命令
镜像命令
- docker images 查看所有本地的主机上的镜像
- docker search 搜索镜像
- docker pull 下载镜像
- docker image rm 删除镜像
- docker inspect 查看镜像元数据
- docker commit 提交镜像
下载镜像
从 Docker 镜像仓库获取镜像的命令是 docker pull。其命令格式为:
docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签]
具体的选项可以通过 docker pull --help 命令看到,这里我们说一下镜像名称的格式。
- Docker 镜像仓库地址:地址的格式一般是
<域名/IP>[:端口号]。默认地址是 Docker Hub (docker.io)。 - 仓库名:如之前所说,这里的仓库名是两段式名称,即
<用户名>/<软件名>。对于 Docker Hub,如果不给出用户名,则默认为library,也就是官方镜像。
比如:
[root@localhost ~]# docker pull mysql
Using default tag: latest
latest: Pulling from library/mysql
72a69066d2fe: Pull complete
93619dbc5b36: Pull complete
99da31dd6142: Pull complete
626033c43d70: Pull complete
37d5d7efb64e: Pull complete
ac563158d721: Pull complete
d2ba16033dad: Pull complete
688ba7d5c01a: Pull complete
00e060b6d11d: Pull complete
1c04857f594f: Pull complete
4d7cfa90e6ea: Pull complete
e0431212d27d: Pull complete
Digest: sha256:e9027fe4d91c0153429607251656806cc784e914937271037f7738bd5b8e7709
Status: Downloaded newer image for mysql:latest
docker.io/library/mysql:latest
上面的命令中没有给出 Docker 镜像仓库地址,因此将会从 Docker Hub (docker.io)获取镜像。而镜像名称是 mysql,因此将会获取官方镜像 library/mysql 仓库中标签为 latest 的镜像。docker pull 命令的输出结果最后一行给出了镜像的完整名称,即: docker.io/library/mysql:latest。
从下载过程中可以看到我们之前提及的分层存储的概念,镜像是由多层存储所构成。下载也是一层层的去下载,并非单一文件。下载过程中给出了每一层的 ID 的前 12 位。并且下载结束后,给出该镜像完整的 sha256 的摘要,以确保下载一致性。
删除镜像
docker rmi 镜像id # 删除指定的镜像
docker rmi $(docker image -aq) # 删除所有镜像
提交镜像
注意:docker commit 命令除了学习之外,还有一些特殊的应用场合,比如被入侵后保存现场等。但是,不要使用 docker commit 定制镜像,定制镜像应该使用 Dockerfile 来完成。
镜像是容器的基础,每次执行 docker run 的时候都会指定哪个镜像作为容器运行的基础。在之前的例子中,我们所使用的都是来自于 Docker Hub 的镜像。直接使用这些镜像是可以满足一定的需求,而当这些镜像无法直接满足需求时,我们就需要定制这些镜像。接下来的几节就将讲解如何定制镜像。
回顾一下之前我们学到的知识,镜像是多层存储,每一层是在前一层的基础上进行的修改;而容器同样也是多层存储,是在以镜像为基础层,在其基础上加一层作为容器运行时的存储层。
现在让我们以定制一个 Web 服务器为例子,来讲解镜像是如何构建的。
docker run --name nginx1 -d -p 80:80 nginx

这条命令会用 nginx 镜像启动一个容器,命名为 nginx1,并且映射了 80 端口,这样我们可以用浏览器去访问这个 nginx 服务器。
如果是在本机运行的 Docker,那么可以直接访问:http://localhost ,如果是在虚拟机、云服务器上安装的 Docker,则需要将 localhost 换为虚拟机地址或者实际云服务器地址 ip 。
直接用浏览器访问的话,我们会看到默认的 Nginx 欢迎页面。

我们在这个 nginx1 镜像上面修改,我们改成 Hello world!
我们以交互式终端方式进入 nginx1 容器,并执行了 bash 命令,也就是获得一个可操作的 Shell。
然后,我们用 <h1>Hello world!</h1> 覆盖了 /usr/share/nginx/html/index.html 的内容。
docker exec -it nginx1 bash # 先进入容器并新开一个进程
echo '<h1>Hello world!</h1>' > /usr/share/nginx/html/index.html # 修改内容
exit # 退出

现在我们再刷新浏览器的话,会发现内容被改变了。
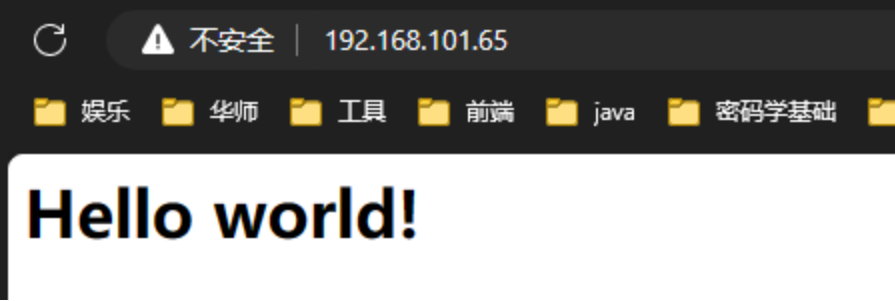
下一步我们保存新的镜像!
docker commit [选项] <容器ID或容器名> [<仓库名>[:<标签>]]
docker commit -a="cyr" -m="hello world" nginx1 nginx2:v1

新的镜像定制好后,我们可以来运行这个镜像。
docker run --name nginx2 -d -p 81:80 nginx2:v1
访问 81 端口号能看到 hello world!这个结果。表示提交镜像成功!
慎用 docker commit
使用 docker commit 命令虽然可以比较直观的帮助理解镜像分层存储的概念,但是实际环境中并不会这样使用。
首先,由于命令的执行,还有很多文件被改动或添加了。这还仅仅是最简单的操作,如果是安装软件包、编译构建,那会有大量的无关内容被添加进来,将会导致镜像极为臃肿。
此外,使用 docker commit 意味着所有对镜像的操作都是黑箱操作,生成的镜像也被称为 黑箱镜像,换句话说,就是除了制作镜像的人知道执行过什么命令、怎么生成的镜像,别人根本无从得知。而且,即使是这个制作镜像的人,过一段时间后也无法记清具体的操作。这种黑箱镜像的维护工作是非常痛苦的。
而且,回顾之前提及的镜像所使用的分层存储的概念,除当前层外,之前的每一层都是不会发生改变的,换句话说,任何修改的结果仅仅是在当前层进行标记、添加、修改,而不会改动上一层。如果使用 docker commit 制作镜像,以及后期修改的话,每一次修改都会让镜像更加臃肿一次,所删除的上一层的东西并不会丢失,会一直如影随形的跟着这个镜像,即使根本无法访问到。这会让镜像更加臃肿。
容器命令
- docker ps 查看正在运行的容器
- docker rm 删除容器
- docker run 新建并启动容器 (
-d以守护态运行-it以交互式的方式并进入容器启动) - docker start 启动已终止容器
- docker stop 停止运行中的容器
- docker attach 进入容器正在执行的终端
- docker exec 进入容器后开启一个新的终端
- docker cp 从容器内拷贝文件到宿主机上
- docker logs 查看容器日志
- docker top 查看容器中进程信息
容器数据卷
数据卷 是一个可供一个或多个容器使用的特殊目录,可以提供很多有用的特性:
数据卷可以在容器之间共享和重用- 对
数据卷的修改会立马生效 - 对
数据卷的更新,不会影响镜像 数据卷默认会一直存在,即使容器被删除
注意:
数据卷的使用,类似于 Linux 下对目录或文件进行 mount,镜像中的被指定为挂载点的目录中的文件会复制到数据卷中(仅数据卷为空时会复制)。
-v 容器内路径 # 匿名挂载
-v 卷名:容器内路径 # 具名挂载
-v /宿主机路径:容器内路径 # 指定路径挂载
实战:mysql 数据持久化
# 获取镜像
docker pull mysql:8.0
# 运行容器
-d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 容器名字
docker run -d -p 3310:3306 -v /home/mysql/conf:/etc/mysql/conf.d -v /home/mysql/data:/var/lib/mysql --name mysql01 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0
启动后,在本地连接测试,navicat 连接到数据库,在新建数据库 test 前后分别输出 ls 查看。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号