

机器学习-----心律失常分类
Python机器学习--------心率失常分类
一、选题的背景介绍
因为随着我国逐渐步入老龄化社会还有年轻人喜欢熬夜玩游戏,心血管疾病患者持续增加,使得心脏监护系统需求也在不断提高。如何利用计算机辅助技术对心律失常进行精准检测和分类是心血管疾病诊断中的研究热点之一,而心电图对心脏疾病具有重要意义,心电图利用小波变换提取了更精确的ECG信号图,并且构建卷积神经网络(CNN)进行模式识别能够识别出心律失常的五种类型——窦性心律不齐(年轻人居多心脏健康的一种问题)、早搏(可病发于任何正常人)、逸博(本身并不严重)、窦房(房室)阻滞(比较严重)、心房(心室)内阻滞。
- 机器学习案例设计方案
下载数据集,整理和处理好数据集,利用keras建立训练模型
数据集来源:physionet ,https://www.physionet.org/content/mitdb/1.0.0/
- 从physionet网站下载数据集
- 导入需要的包
import os
import datetime
import wfdb
import pywt
import seaborn
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import linear_model,tree
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from tensorflow import keras
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
import pickle
from sklearn.metrics import f1_score,recall_score,precision_score,roc_curve,auc,accuracy_score,confusion_matrix
import numpy
from scipy import interp
from itertools import cycle
from matplotlib.ticker import FuncFormatter
import pandas as pd
from matplotlib import style
import seaborn as sns
import collections
- 心电信号的预处理采用小波变换
def denoise(data):
# 小波变换
coeffs = pywt.wavedec(data=data, wavelet='db5', level=9)
cA9, cD9, cD8, cD7, cD6, cD5, cD4, cD3, cD2, cD1 = coeffs
- 在加载数据的基础上对心电信号进行小波变换、阈值去噪、小波反变换地操作获得去噪后的心电信号。
# 阈值去噪
threshold = (np.median(np.abs(cD1)) / 0.6745) * (np.sqrt(2 * np.log(len(cD1))))
cD1.fill(0)
cD2.fill(0)
for i in range(1, len(coeffs) - 2):
coeffs[i] = pywt.threshold(coeffs[i], threshold)
# 小波反变换,获取去噪后的信号
rdata = pywt.waverec(coeffs=coeffs, wavelet='db5')
return rdata
- 对于每一个心电数据都采样650000个离散数据点,实例取前1000个数据点来呈现读取的波形图
# plt.subplot(2,1,1)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 读取本地的100号记录,sampto:采样频率,取值为:【0:650000】
record = wfdb.rdrecord('ecg_data/100', sampfrom=0, sampto=600000, physical=False, channel_names=['MLII'])
print("record frequency:" + str(record.fs))
# 读取前1000数据
ventricular_signal_pro = record.d_signal[0:1000]
print('signal shape: ' + str(ventricular_signal_pro.shape))
# 绘制波形
plt.plot(ventricular_signal_pro)
plt.title("Waveform (after denoising)")
plt.savefig('./graph/(去噪前)波形图.jpg')
plt.show()
#去噪:
data1 = ventricular_signal_pro.flatten()
rdata = denoise(data=data1)
rdata=rdata.reshape(ventricular_signal_pro.shape)
# plt.subplot(2,1,2)
print('signal shape: ' + str(rdata.shape))
# 绘制波形
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(rdata)
plt.title("Waveform (after denoising)")
plt.savefig('./graph/(去噪后)波形图.jpg')
plt.show()
- 查看去噪前后对比


- 加载数据集并进行预处理
# 测试集在数据集中所占的比例
RATIO = 0.3
# 加载数据集并进行预处理
def loadData():
numberSet = ['100', '101', '103', '105', '106', '107', '108', '109', '111', '112', '113', '114', '115',
'116', '117', '119', '121', '122', '123', '124', '200', '201', '202', '203', '205', '208',
'210', '212', '213', '214', '215', '217', '219', '220', '221', '222', '223', '228', '230',
'231', '232', '233', '234']
dataSet = []
lableSet = []
for n in numberSet:
getDataSet(n, dataSet, lableSet)
return dataSet,lableSet
# 读取心电数据和对应标签,并对数据进行小波去噪
def getDataSet(number, X_data, Y_data):
ecgClassSet = ['N', 'A', 'V', 'L', 'R']
# 读取心电数据记录
# print("正在读取 " + number + " 号心电数据...")
record = wfdb.rdrecord('ecg_data/' + number, channel_names=['MLII'])
data = record.p_signal.flatten()
rdata = denoise(data=data)
# 获取心电数据记录中R波的位置和对应的标签
annotation = wfdb.rdann('ecg_data/' + number, 'atr')
Rlocation = annotation.sample
Rclass = annotation.symbol
- 创建多个模型
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = []
def on_epoch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
def BPNET_no_GA(X_train, X_test,Y_train):
- 创建序列模型
model = Sequential()
model.add(Dense(512,input_dim=len(X_train[0]))) #第一层级 - 添加有 512个节点的完全连接层级
model.add(Activation('relu')) #第一层级 - 使用 relu 激活层级
model.add(Dense(128)) #第二层级 - 添加有 128 个节点的完全连接层级
model.add(Activation('relu')) #第二层级 - 使用 relu 激活层级
model.add(Dense(len(Y_train[0]))) #第三层级 - 添加完全连接的层级
model.add(Activation('softmax')) #第四层级 - 添加 softmax激活层级
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics = ['accuracy'])
history = LossHistory()
model.fit(X_train,Y_train,batch_size=128,epochs=10,callbacks=[history])
return model,history.losses
10. 构建机器学习模型
def get_machine_learn_model(model_name):
if model_name=='LogisticRegression':
return linear_model.LogisticRegression()
elif model_name=='KNeighborsClassifier':
return KNeighborsClassifier()
elif model_name=='SVM':
return SVC()
elif model_name=='DecisionTreeClassifier':
return tree.DecisionTreeClassifier()
11. 构建CNN模型
def CNN(X_train, Y_train):
newModel = tf.keras.models.Sequential([
tf.keras.layers.InputLayer(input_shape=(300, 1)),
tf.keras.layers.Conv1D(filters=4, kernel_size=21, strides=1, padding='SAME', activation='relu'),# 第一个卷积层, 4 个 21x1 卷积核
tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'),# 第一个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.Conv1D(filters=16, kernel_size=23, strides=1, padding='SAME', activation='relu'),# 第二个卷积层, 16 个 23x1 卷积核
tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'),# 第二个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.Conv1D(filters=32, kernel_size=25, strides=1, padding='SAME', activation='relu'),# 第三个卷积层, 32 个 25x1 卷积核
tf.keras.layers.AvgPool1D(pool_size=3, strides=2, padding='SAME'),# 第三个池化层, 平均池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.Conv1D(filters=64, kernel_size=27, strides=1, padding='SAME', activation='relu'),# 第四个卷积层, 64 个 27x1 卷积核
tf.keras.layers.Flatten(),# 打平层,方便全连接层处理
tf.keras.layers.Dense(128, activation='relu'),# 全连接层,128 个节点
tf.keras.layers.Dropout(rate=0.2),# Dropout层,dropout = 0.2
tf.keras.layers.Dense(5, activation='softmax'),# 全连接层,5 个节点
])
newModel.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
history = LossHistory()
12. 可视化网络
newModel.fit(X_train, Y_train, epochs=3,batch_size=128,validation_split=RATIO,callbacks=[history])# 训练与验证
return newModel,history.losses
13. 绘制混淆矩阵
def plotHeatMap(Y_test, Y_pred):
con_mat = confusion_matrix(Y_test, Y_pred)
# 绘图
plt.figure(figsize=(8, 8))
seaborn.heatmap(con_mat, annot=True, fmt='.20g', cmap='Blues')
plt.ylim(0, 5)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
def get_calculate_info(y_ture,y_pre):
cm=confusion_matrix(y_ture, y_pre)
FP = cm.sum(axis=0) - np.diag(cm)
FN = cm.sum(axis=1) - np.diag(cm)
TP = np.diag(cm)
TN = cm.sum() - (FP + FN + TP)
# Sensitivity, hit rate, recall, or true positive rate
TPR = TP/(TP+FN)
# Specificity or true negative rate
TNR = TN/(TN+FP)
# Precision or positive predictive value
PPV = TP/(TP+FP)
# Negative predictive value
NPV = TN/(TN+FN)
# Fall out or false positive rate
FPR = FP/(FP+TN)
# False negative rate
FNR = FN/(TP+FN)
# False discovery rate
FDR = FP/(TP+FP)
precision = TP / (TP+FP) # 查准率
recall = TP / (TP+FN) # 查全率
# Normalize by row
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
return cm_normalized
#画混淆矩阵
def plot_confusion_matrix(cm, savename, title='Confusion matrix'):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10,5), dpi=100)
np.set_printoptions(precision=2)
classes = ['N', 'A', 'V', 'L', 'R']
# 在混淆矩阵中每格的概率值
ind_array = np.arange(len(classes))
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
if c > 0.001:
plt.text(x_val, y_val, "%0.2f" % (c,), color='red', fontsize=15, va='center', ha='center')
plt.imshow(cm, interpolation='nearest')
plt.title(title)
plt.colorbar()
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, classes, rotation=90)
plt.yticks(xlocations, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
# offset the tick
tick_marks = np.array(range(len(classes))) + 0.5
plt.gca().set_xticks(tick_marks, minor=True)
plt.gca().set_yticks(tick_marks, minor=True)
plt.gca().xaxis.set_ticks_position('none')
plt.gca().yaxis.set_ticks_position('none')
plt.grid(True, which='minor', linestyle='-')
plt.gcf().subplots_adjust(bottom=0.15)
plt.xticks(rotation =0)
# show confusion matrix
plt.savefig(savename)
plt.show()
14. 画roc曲线
def to_percent(temp, position):
return '%1.0f'%(100*temp)
def get_ROC_AUC(Y_true_1,Y_pred_1,labels,save_path,
colors=cycle(['aqua', 'darkorange', 'cornflowerblue','blue','yellow'])):
#计算数据的4个指标
n_classes=len(labels)
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(Y_true_1[:, i], Y_pred_1[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# First aggregate all false positive rates
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
lw = 2
# Plot all ROC curves
plt.figure()
plt.plot(fpr["macro"], tpr["macro"],label='Average ROC (AUC = {0:0.4f})'.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,label=labels[i]+'(AUC = {0:0.4f})'.format(roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('1-Specificity (%)')
plt.ylabel('Sensitivity (%)')
plt.title('ROC')
plt.gca().yaxis.set_major_formatter(FuncFormatter(to_percent))
plt.gca().xaxis.set_major_formatter(FuncFormatter(to_percent))
plt.legend(loc="lower right")
plt.savefig(save_path)
plt.show()
15.加载数据
dataSet,lableSet= loadData()#加载数据
X_train, X_test,Y_train, Y_test=train_test_split(dataSet,lableSet,test_size=RATIO)#切分数据
X_train=np.array(X_train)
X_test=np.array(X_test)
Y_train_onehot=tf.one_hot(Y_train,depth=len(set(Y_train)))#label进行onehot
Y_test_onehot=tf.one_hot(Y_test,depth=len(set(Y_train)))
16.开始训练模型
for model_name in model_name_list:
print('开始训练模型:',model_name)
if model_name=='BPNET_no_GA':
# Y_train_onehot=tf.one_hot(Y_train,depth=len(set(Y_train)))
# Y_test_onehot_test=tf.one_hot(Y_test,depth=len(set(Y_train)))
model,history=BPNET_no_GA(X_train, X_test,Y_train_onehot)
Y_pred=model.predict(X_test)
Y_pred=tf.argmax(Y_pred,axis=1)
elif model_name=='CNN':
X_train_1=X_train.reshape(-1,300,1)#改变输入的shape
X_test_1=X_test.reshape(-1,300,1)
Y_train_1=np.array(Y_train)
Y_test_1=np.array(Y_test)
model,history=CNN(X_train_1, Y_train_1)
Y_pred=model.predict(X_test_1)
Y_pred=tf.argmax(Y_pred,axis=1)
elif model_name in ['LogisticRegression','KNeighborsClassifier','SVM','DecisionTreeClassifier']:
model=get_machine_learn_model(model_name)
model.fit(X_train,Y_train)
Y_pred=model.predict(X_test)
history=[-1]
else:
print(model_name,'不在本次训练范围内!')
continue
loss_collect[model_name]=history

17. 生成混淆矩阵和ROC曲线图
print(model_name,'\t的混淆矩阵如图所示:')
cm_normalized=get_calculate_info(np.array(Y_test), Y_pred)
classes = ['N', 'A', 'V', 'L', 'R']
plot_confusion_matrix(cm_normalized, './graph/{}混淆矩阵.jpg'.format(model_name), title='Confusion matrix')
print(model_name,'\t的ROC曲线如图所示:')
Y_pred_onehot=tf.one_hot(Y_pred,depth=len(set(Y_train)))
get_ROC_AUC(Y_pred_onehot,Y_test_onehot,labels=classes,save_path='./graph/{}ROC曲线.jpg'.format(model_name))
print(model_name,'\t测试集结果如下所示:')
test_acc_rate,test_pre_rate,test_recall_rate,test_f1=get_result(Y_test, Y_pred)
print('精确率:{},准确率:{},\n召回率:{},F1综合值:{}'.format(test_acc_rate,test_pre_rate,test_recall_rate,test_f1))
all_result['精确率'].append(test_acc_rate)
all_result['准确率'].append(test_pre_rate)
all_result['召回率'].append(test_recall_rate)
all_result['F1综合值'].append(test_f1)
return all_result,loss_collect
if __name__=='__main__':
# model_name_list=['BPNET_no_GA','CNN','LogisticRegression']
model_name_list=['BPNET_no_GA','KNeighborsClassifier','SVM','CNN','LogisticRegression','DecisionTreeClassifier']
all_result,loss_collect= main(model_name_list)
all_result=pd.DataFrame(all_result,index=model_name_list)
get_result_picture(all_result)
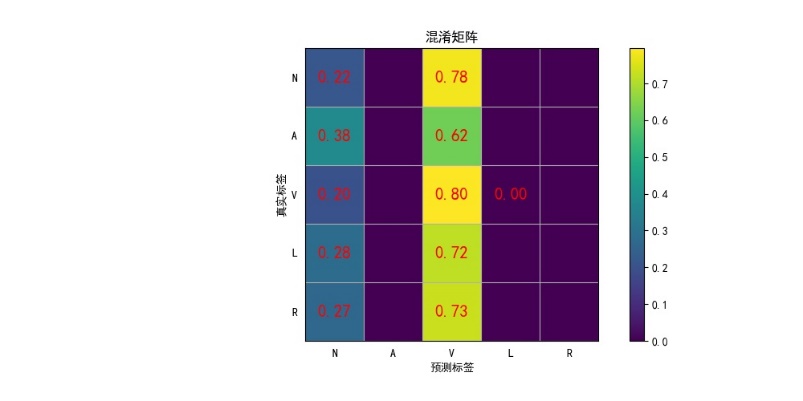
BP with sklearnROC曲线和BP with sklearn混淆矩阵
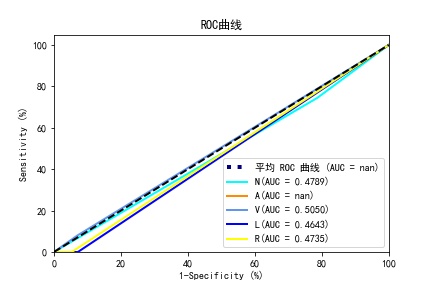

BP_by handROC曲线和BP_by hand混淆矩阵

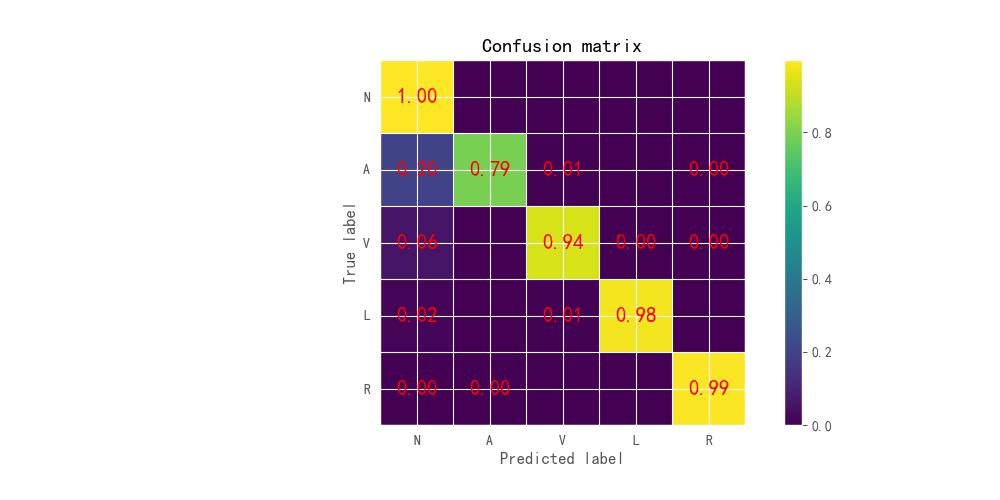
BPNET_no_GAROC曲线和BPNET_no_GA混淆矩阵
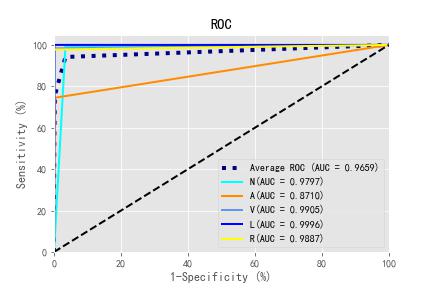

CNNROC曲线和CNN混淆矩阵

DecisionTreeClassifierROC曲线和DecisionTreeClassifier混淆矩阵


KNeighborsClassifierROC曲线和KNeighborsClassifier混淆矩阵


LogisticRegressionROC曲线和LogisticRegression混淆矩阵


SVM_lineROC曲线和SVM_line混淆矩阵

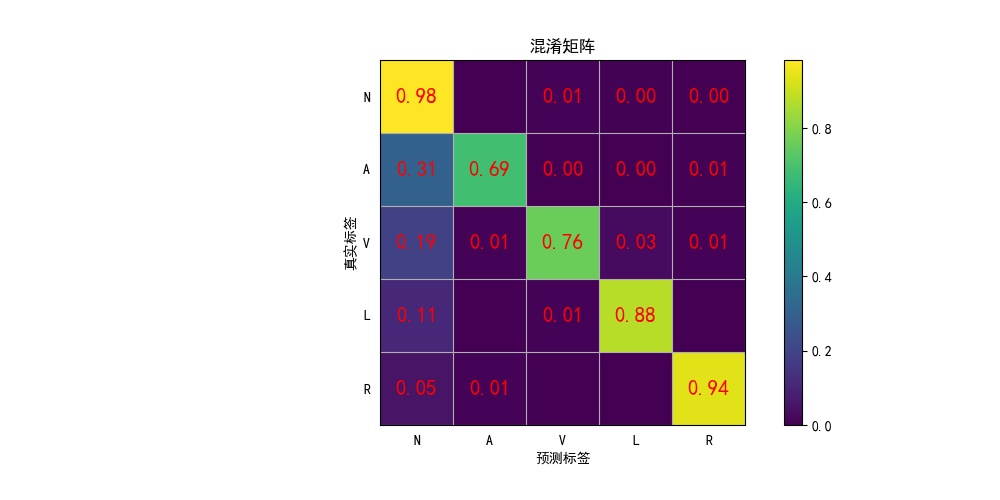
SVM_polyROC曲线和SVM_poly混淆矩阵
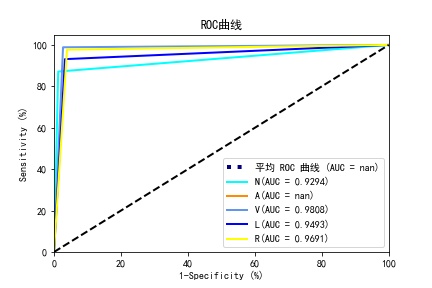

SVMROC曲线和SVMROC混淆矩阵


18.生成模型指标对比
def get_result_picture(all_result):
style.use('ggplot') # 加载'ggplot'风格
x = np.arange(4)# 生成横坐标范围
columns=all_result.columns# 生成横坐标
for i in range(len(model_name_list)):
plt.bar(x+0.15*i, all_result.iloc[i], width=0.15, label=model_name_list[i])
plt.title('Model Comparison')
plt.xticks(x+0.3*(i//2),columns)# 横坐标绑定
plt.ylim(np.min(np.min(all_result))*0.99,1)
plt.legend(loc="best")
plt.savefig("./graph/模型指标对比.jpg", dpi=700)
plt.show()
all_result.columns=['accuracy','precession','recall','F1']
get_result_picture(all_result)

由以上数据可以直接列出各类指标平均结果的对比,如上图所示。可以清晰的看到各类指标CNN为最优模型,BP其次。实验结果说明,CNN学习能力更强。主要原因是BP神经网络采用全连接方式连接网络前后层的神经元,只能学习全局特征,无法学习局部特征;而CNN采用局部连接、局部滑动的方式提取数据中的特征,每个卷积核在计算时只用了某个局部特征,这种方式反而增加了模型的学习能力,从而使模型性能在机器学习算法的基础上有较大的提升。
19. 数据保存到csv文件内
all_result.to_csv('./result.csv')


三、总结
本次实验,经过数据的提取与降噪,构建了6个模式识别的模型进行分类,在正确提取特征值并且以统计的方法来确定所用的参数的基础上,以量化的标准来比较这6个模型具体的优劣程度。分析得出对于本次数据而言,CNN神经网络是最优分类模型。
这次实验采用了小波去噪算法除掉数据中的噪声数据,降噪处理的代码比较局限,如果更换数据集,我这个验证就不通过,感谢老师这学期的教导,我会更加努力的学习。
import os
import datetime
import wfdb
import pywt
import seaborn
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import linear_model,tree
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from tensorflow import keras
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
import pickle
from sklearn.metrics import f1_score,recall_score,precision_score,roc_curve,auc,accuracy_score,confusion_matrix
import numpy
from scipy import interp
from itertools import cycle
from matplotlib.ticker import FuncFormatter
import pandas as pd
from matplotlib import style
import seaborn as sns
import collections
# 小波去噪预处理
def denoise(data):
# 小波变换
coeffs = pywt.wavedec(data=data, wavelet='db5', level=9)
cA9, cD9, cD8, cD7, cD6, cD5, cD4, cD3, cD2, cD1 = coeffs
# 阈值去噪
threshold = (np.median(np.abs(cD1)) / 0.6745) * (np.sqrt(2 * np.log(len(cD1))))
cD1.fill(0)
cD2.fill(0)
for i in range(1, len(coeffs) - 2):
coeffs[i] = pywt.threshold(coeffs[i], threshold)
# 小波反变换,获取去噪后的信号
rdata = pywt.waverec(coeffs=coeffs, wavelet='db5')
return rdata
# plt.subplot(2,1,1)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 读取本地的100号记录,sampto:采样频率,取值为:【0:650000】
record = wfdb.rdrecord('ecg_data/100', sampfrom=0, sampto=600000, physical=False, channel_names=['MLII'])
print("record frequency:" + str(record.fs))
# 读取前1000数据
ventricular_signal_pro = record.d_signal[0:1000]
print('signal shape: ' + str(ventricular_signal_pro.shape))
# 绘制波形
plt.plot(ventricular_signal_pro)
plt.title("Waveform (after denoising)")
plt.savefig('./graph/(去噪前)波形图.jpg')
plt.show()
#去噪:
data1 = ventricular_signal_pro.flatten()
rdata = denoise(data=data1)
rdata=rdata.reshape(ventricular_signal_pro.shape)
# plt.subplot(2,1,2)
print('signal shape: ' + str(rdata.shape))
# 绘制波形
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(rdata)
plt.title("Waveform (after denoising)")
plt.savefig('./graph/(去噪后)波形图.jpg')
plt.show()
# 测试集在数据集中所占的比例
RATIO = 0.3
# 加载数据集并进行预处理
def loadData():
numberSet = ['100', '101', '103', '105', '106', '107', '108', '109', '111', '112', '113', '114', '115',
'116', '117', '119', '121', '122', '123', '124', '200', '201', '202', '203', '205', '208',
'210', '212', '213', '214', '215', '217', '219', '220', '221', '222', '223', '228', '230',
'231', '232', '233', '234']
dataSet = []
lableSet = []
for n in numberSet:
getDataSet(n, dataSet, lableSet)
return dataSet,lableSet
# 读取心电数据和对应标签,并对数据进行小波去噪
def getDataSet(number, X_data, Y_data):
ecgClassSet = ['N', 'A', 'V', 'L', 'R']
# 读取心电数据记录
#print("正在读取 " + number + " 号心电数据...")
record = wfdb.rdrecord('ecg_data/' + number, channel_names=['MLII'])
data = record.p_signal.flatten()
rdata = denoise(data=data)
# 获取心电数据记录中R波的位置和对应的标签
annotation = wfdb.rdann('ecg_data/' + number, 'atr')
Rlocation = annotation.sample
Rclass = annotation.symbol
# 去掉前后的不稳定数据
start = 10
end = 5
i = start
j = len(annotation.symbol) - end
# 因为只选择NAVLR五种心电类型,所以要选出该条记录中所需要的那些带有特定标签的数据,舍弃其余标签的点
# X_data在R波前后截取长度为300的数据点
# Y_data将NAVLR按顺序转换为01234
while i < j:
try:
lable = ecgClassSet.index(Rclass[i])
x_train = rdata[Rlocation[i] - 99:Rlocation[i] + 201]
X_data.append(x_train)
Y_data.append(lable)
i += 1
except ValueError:
i += 1
return
#创建多个模型
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = []
def on_epoch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
def BPNET_no_GA(X_train, X_test,Y_train):
#创建序列模型
model = Sequential()
model.add(Dense(512,input_dim=len(X_train[0]))) #第一层级 - 添加有 512个节点的完全连接层级
model.add(Activation('relu')) #第一层级 - 使用 relu 激活层级
model.add(Dense(128)) #第二层级 - 添加有 128 个节点的完全连接层级
model.add(Activation('relu')) #第二层级 - 使用 relu 激活层级
model.add(Dense(len(Y_train[0]))) #第三层级 - 添加完全连接的层级
model.add(Activation('softmax')) #第四层级 - 添加 softmax激活层级
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics = ['accuracy'])
history = LossHistory()
model.fit(X_train,Y_train,batch_size=128,epochs=10,callbacks=[history])
return model,history.losses
#构建机器学习模型
def get_machine_learn_model(model_name):
if model_name=='LogisticRegression':
return linear_model.LogisticRegression()
elif model_name=='KNeighborsClassifier':
return KNeighborsClassifier()
elif model_name=='SVM':
return SVC()
elif model_name=='DecisionTreeClassifier':
return tree.DecisionTreeClassifier()
# 构建CNN模型
def CNN(X_train, Y_train):
newModel = tf.keras.models.Sequential([
tf.keras.layers.InputLayer(input_shape=(300, 1)),
tf.keras.layers.Conv1D(filters=4, kernel_size=21, strides=1, padding='SAME', activation='relu'),# 第一个卷积层, 4 个 21x1 卷积核
tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'),# 第一个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.Conv1D(filters=16, kernel_size=23, strides=1, padding='SAME', activation='relu'),# 第二个卷积层, 16 个 23x1 卷积核
tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'),# 第二个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.Conv1D(filters=32, kernel_size=25, strides=1, padding='SAME', activation='relu'),# 第三个卷积层, 32 个 25x1 卷积核
tf.keras.layers.AvgPool1D(pool_size=3, strides=2, padding='SAME'),# 第三个池化层, 平均池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.Conv1D(filters=64, kernel_size=27, strides=1, padding='SAME', activation='relu'),# 第四个卷积层, 64 个 27x1 卷积核
tf.keras.layers.Flatten(),# 打平层,方便全连接层处理
tf.keras.layers.Dense(128, activation='relu'),# 全连接层,128 个节点
tf.keras.layers.Dropout(rate=0.2),# Dropout层,dropout = 0.2
tf.keras.layers.Dense(5, activation='softmax'),# 全连接层,5 个节点
])
newModel.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
history = LossHistory()
# newModel.summary()#可视化网络
newModel.fit(X_train, Y_train, epochs=3,batch_size=128,validation_split=RATIO,callbacks=[history])# 训练与验证
return newModel,history.losses
# 混淆矩阵
def plotHeatMap(Y_test, Y_pred):
con_mat = confusion_matrix(Y_test, Y_pred)
# 绘图
plt.figure(figsize=(8, 8))
seaborn.heatmap(con_mat, annot=True, fmt='.20g', cmap='Blues')
plt.ylim(0, 5)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
def get_calculate_info(y_ture,y_pre):
cm=confusion_matrix(y_ture, y_pre)
FP = cm.sum(axis=0) - np.diag(cm)
FN = cm.sum(axis=1) - np.diag(cm)
TP = np.diag(cm)
TN = cm.sum() - (FP + FN + TP)
# Sensitivity, hit rate, recall, or true positive rate
TPR = TP/(TP+FN)
# Specificity or true negative rate
TNR = TN/(TN+FP)
# Precision or positive predictive value
PPV = TP/(TP+FP)
# Negative predictive value
NPV = TN/(TN+FN)
# Fall out or false positive rate
FPR = FP/(FP+TN)
# False negative rate
FNR = FN/(TP+FN)
# False discovery rate
FDR = FP/(TP+FP)
precision = TP / (TP+FP) # 查准率
recall = TP / (TP+FN) # 查全率
# Normalize by row
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
return cm_normalized
#画混淆矩阵
def plot_confusion_matrix(cm, savename, title='Confusion matrix'):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10,5), dpi=100)
np.set_printoptions(precision=2)
classes = ['N', 'A', 'V', 'L', 'R']
# 在混淆矩阵中每格的概率值
ind_array = np.arange(len(classes))
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
if c > 0.001:
plt.text(x_val, y_val, "%0.2f" % (c,), color='red', fontsize=15, va='center', ha='center')
plt.imshow(cm, interpolation='nearest')
plt.title(title)
plt.colorbar()
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, classes, rotation=90)
plt.yticks(xlocations, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
# offset the tick
tick_marks = np.array(range(len(classes))) + 0.5
plt.gca().set_xticks(tick_marks, minor=True)
plt.gca().set_yticks(tick_marks, minor=True)
plt.gca().xaxis.set_ticks_position('none')
plt.gca().yaxis.set_ticks_position('none')
plt.grid(True, which='minor', linestyle='-')
plt.gcf().subplots_adjust(bottom=0.15)
plt.xticks(rotation =0)
# show confusion matrix
plt.savefig(savename)
plt.show()
#画ROC曲线
def to_percent(temp, position):
return '%1.0f'%(100*temp)
def get_ROC_AUC(Y_true_1,Y_pred_1,labels,save_path,
colors=cycle(['aqua', 'darkorange', 'cornflowerblue','blue','yellow'])):
#计算数据的4个指标
n_classes=len(labels)
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(Y_true_1[:, i], Y_pred_1[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# First aggregate all false positive rates
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
lw = 2
# Plot all ROC curves
plt.figure()
plt.plot(fpr["macro"], tpr["macro"],label='Average ROC (AUC = {0:0.4f})'.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,label=labels[i]+'(AUC = {0:0.4f})'.format(roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('1-Specificity (%)')
plt.ylabel('Sensitivity (%)')
plt.title('ROC')
plt.gca().yaxis.set_major_formatter(FuncFormatter(to_percent))
plt.gca().xaxis.set_major_formatter(FuncFormatter(to_percent))
plt.legend(loc="lower right")
plt.savefig(save_path)
plt.show()
def get_result(Y_test, Y_pred):
test_acc_rate=accuracy_score(Y_test, Y_pred)
test_pre_rate=precision_score(Y_test, Y_pred, average='weighted')
test_recall_rate=recall_score(Y_test, Y_pred, average='weighted')
test_f1=f1_score(Y_test, Y_pred, average='weighted')
return test_acc_rate,test_pre_rate,test_recall_rate,test_f1
def get_result_picture(all_result):
style.use('ggplot') # 加载'ggplot'风格
x = np.arange(4)# 生成横坐标范围
columns=all_result.columns# 生成横坐标
for i in range(len(model_name_list)):
plt.bar(x+0.15*i, all_result.iloc[i], width=0.15, label=model_name_list[i])
plt.title('Model Comparison')
plt.xticks(x+0.3*(i//2),columns)# 横坐标绑定
plt.ylim(np.min(np.min(all_result))*0.99,1)
plt.legend(loc="best")
plt.savefig("./graph/模型指标对比.jpg", dpi=700)
plt.show()
def main(model_name_list):
if os.path.exists('./graph/')==False:
os.mkdir('./graph/')
#数据准备
dataSet,lableSet= loadData()#加载数据
X_train, X_test,Y_train, Y_test=train_test_split(dataSet,lableSet,test_size=RATIO)#切分数据
X_train=np.array(X_train)
X_test=np.array(X_test)
Y_train_onehot=tf.one_hot(Y_train,depth=len(set(Y_train)))#label进行onehot
Y_test_onehot=tf.one_hot(Y_test,depth=len(set(Y_train)))
#遍历模型得到结果
all_result=collections.defaultdict(list)
loss_collect={}
for model_name in model_name_list:
print('开始训练模型:',model_name)
if model_name=='BPNET_no_GA':
# Y_train_onehot=tf.one_hot(Y_train,depth=len(set(Y_train)))
# Y_test_onehot_test=tf.one_hot(Y_test,depth=len(set(Y_train)))
model,history=BPNET_no_GA(X_train, X_test,Y_train_onehot)
Y_pred=model.predict(X_test)
Y_pred=tf.argmax(Y_pred,axis=1)
elif model_name=='CNN':
X_train_1=X_train.reshape(-1,300,1)#改变输入的shape
X_test_1=X_test.reshape(-1,300,1)
Y_train_1=np.array(Y_train)
Y_test_1=np.array(Y_test)
model,history=CNN(X_train_1, Y_train_1)
Y_pred=model.predict(X_test_1)
Y_pred=tf.argmax(Y_pred,axis=1)
elif model_name in ['LogisticRegression','KNeighborsClassifier','SVM','DecisionTreeClassifier']:
model=get_machine_learn_model(model_name)
model.fit(X_train,Y_train)
Y_pred=model.predict(X_test)
history=[-1]
else:
print(model_name,'不在本次训练范围内!')
continue
loss_collect[model_name]=history
print(model_name,'\t的混淆矩阵如图所示:')
cm_normalized=get_calculate_info(np.array(Y_test), Y_pred)
classes = ['N', 'A', 'V', 'L', 'R']
plot_confusion_matrix(cm_normalized, './graph/{}混淆矩阵.jpg'.format(model_name), title='Confusion matrix')
print(model_name,'\t的ROC曲线如图所示:')
Y_pred_onehot=tf.one_hot(Y_pred,depth=len(set(Y_train)))
get_ROC_AUC(Y_pred_onehot,Y_test_onehot,labels=classes,save_path='./graph/{}ROC曲线.jpg'.format(model_name))
print(model_name,'\t测试集结果如下所示:')
test_acc_rate,test_pre_rate,test_recall_rate,test_f1=get_result(Y_test, Y_pred)
print('精确率:{},准确率:{},\n召回率:{},F1综合值:{}'.format(test_acc_rate,test_pre_rate,test_recall_rate,test_f1))
all_result['精确率'].append(test_acc_rate)
all_result['准确率'].append(test_pre_rate)
all_result['召回率'].append(test_recall_rate)
all_result['F1综合值'].append(test_f1)
return all_result,loss_collect
if __name__=='__main__':
# model_name_list=['BPNET_no_GA','CNN','LogisticRegression']
model_name_list=['BPNET_no_GA','KNeighborsClassifier','SVM','CNN','LogisticRegression','DecisionTreeClassifier']
all_result,loss_collect= main(model_name_list)
all_result=pd.DataFrame(all_result,index=model_name_list)
get_result_picture(all_result)
def get_result_picture(all_result):
style.use('ggplot') # 加载'ggplot'风格
x = np.arange(4)# 生成横坐标范围
columns=all_result.columns# 生成横坐标
for i in range(len(model_name_list)):
plt.bar(x+0.15*i, all_result.iloc[i], width=0.15, label=model_name_list[i])
plt.title('Model Comparison')
plt.xticks(x+0.3*(i//2),columns)# 横坐标绑定
plt.ylim(np.min(np.min(all_result))*0.99,1)
plt.legend(loc="best")
plt.savefig("./graph/模型指标对比.jpg", dpi=700)
plt.show()
all_result.columns=['accuracy','precession','recall','F1']
get_result_picture(all_result)
all_result.to_csv('./result.csv')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具