
接口测试理论(2)--HTTP协议
HTTP协议:是超文本传输协议,它主要规定了在互联网中传输数据时的标准。主要用于定义客户端与web端服务器通讯的格式。
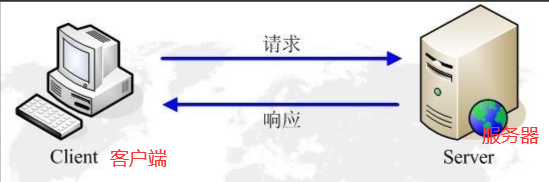
HTTP协议工作于客户端-服务端上。浏览器作为HTTP客户端,通过URL向,HTTP服务端即WEB服务器,发送所有请求。
HTTP特点:支持客户端/服务器模式, 简单快速, 灵活 ,无连接 ,无状态
HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。
采用这种方式可以节省传输时间。即一次请求对应一次响应
HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。
客户端以及服务器指定使用适合的MIME-type内容类型。
HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,
这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
请求(request)响应(response)模型
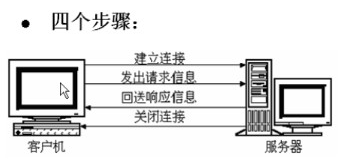
上面这个模型比较简单,它描述的是HTTP1.0中的请求/响应过程。我们分析一下,整个过程中花费的时间包括:建立TCP三次握手的时间、客户端发送请求的时间、服务器返回响应的时间。
1.建立连接,客户端发送一个网页请求,服务器端返回一个html页面(这里的页面只是一个纯文本的文本,也就是我们写的html代码),关闭连接;
2.浏览器解析html文件,遇到图片标记得到url这时,客户端和服务器在建立连接,客户端发送一个图片请求,服务器返回图片应答,关闭连接。(这里又涉及到无状态定义:对于服务器来说,这次的请求虽然是同一个客户端的请求但是他还是不知道这个是之前的那个客户端是同一个,及对于事务处理没有记忆能力);
3.重复2步骤直到html解析完毕;
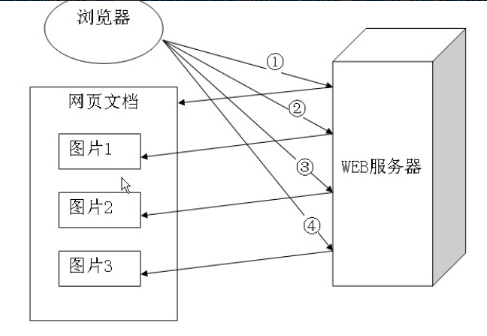
HTTP协议基于请求(request)响应(response)模型
上网的整个过程
假设我们点击了某网页上的一个链接,指向清华大学院系设置,其URL是:http://www.tsinghua.edu.cn/chn/yxsz/index.html。我们来分析一下整个过程:
1.浏览器分析链接指向页面的URL
2.浏览器向DNS请求解析www.tsinghua.edu.cn的IP地址
3.DNS系统解析出清华大学服务器的地址是166.111.4.100
4.浏览器与服务器建立TCP连接
5.浏览器发出取文件命令:GET /chn/yxsz/index.html
6.服务器www.tsinghua.edu.cn给出响应,把文件index.html返回给浏览器
7.释放TCP连接
8.浏览器解析并显示“清华大学院系设置”文件index.html中的内容
其中关于浏览器发送HTTP请求的过程:
-
当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。 【HTTP请求主要分为“Get”和“Post”两种方法。】
-
当我们在浏览器输入URL http://www.baidu.com 的时候,浏览器发送一个Request请求去获取 http://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
-
浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
-
当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
HTTP之URL
URL, 中文叫统一资源定位符,是帮助定位互联网网络资源的地址。
网络资源:包括服务器资源、图片资源、数据等等
以下面这个URL为例,介绍下普通URL的各部分组成:
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
1.协议部分:规定传输数据的协议是什么,一般是指URL中第一个冒号之前的部分。web系统中常用的协议有http,https,FTP等等。在"HTTP"后面的“//”为分隔符。 属于必选部分
2.域名部分:就是要访问的web服务器的地址(域名或ip地址),这个域名会被DNS服务器解析成IP地址,通过IP来定位服务器资源地址。该URL的域名部分为“www.aspxfans.com”。 必选部分
3.端口部分:端口部分就是服务器内部的应用的端口。一般来说web服务器都会指定自身提供服务的端口(监听端口)然后用户要访问服务器,必须指定对应的端口;
通常来说,常用的协议都有默认的服务端口,如果服务器所提供的端口和协议的默认端口一致的话,则用户可以不用输入端口;
http协议默认80端口(默认:没有填写端口时,就采用默认的端口)(https的默认端口是:443端口)
端口是跟在域名之后,格式一般是 域名:端口 必选部分;
4.资源路径path部分:,定位到服务器具体代码的路径
一般来说,我们访问的服务器都是服务器所指定的某一个文件夹(容器)内的资源。
path就是用来指定要访问的资源位于服务器的容器下的路径。(从容器可是计算,不包括容器本身) 必选部分
服务器一般都有一个index的设置,如果访问的是服务器的文件夹,则自动访问文件夹下的index文件;
从域名后的第一个“/”开始到最后一个“/”为止
5.查询参数部分:是具体传递的数据
从“?”开始拼接在path之后,通常代表使用get方法传递给服务器的数据
通常是键值对形式 即键名=键值,不同键值之间用“&”作为分隔符。 可选
如果把URL比喻成快递,
那么协议部分决定了用顺丰快递还是申通快递,它是指选择不同的传输方式。
域名部分就是传到哪个具体位置的楼房:
北京海淀区海置创投大厦 端口部分就是指这栋楼的那一层:
二楼 资源路径:指这层楼中的哪一个单元房间 查询参数:传递给这个单元房间的物品。
HTTP协议的组成部分
按照HTTP协议规定,传输客户端请求报文时(request),数据包括三个部分:
请求行 请求头 请求体
传输服务器响应报文时(response),数据包括三个部分:
状态行 响应头 响应正文
HTTP之请求消息Request
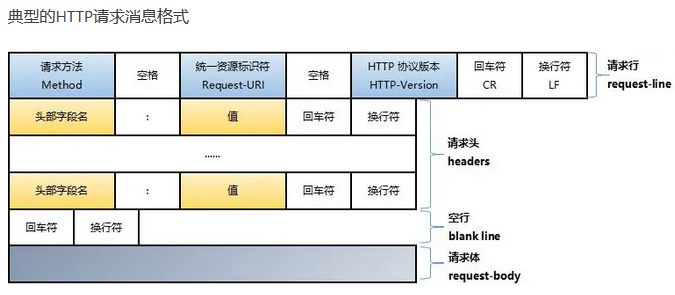
请求组成:
(1)请求行(request line):
请求方法(GET,POST,PUT等), 请求路径(URL的一部分),所用的协议
(2)请求头(header):头信息结束后用于指定服务器要使用的附加信息并且是不常更新的数据,例如:HOST表示请求的目的地,也就是请求的Web服务器域名地址。User-Agent记录着HTTP客户端运行的浏览器类型的详细信息
(3)请求主体:可以没有,也叫请求数据,可以添加任意的其他数据。请求体用来传输数据。和URL中的查询参数不一样的是,URL的数据直接可以在浏览器地址栏看到,而请求体不能直 接看到。并且,请求体能传输的数据类型、数据大小都比URL要多
实际测试中,我们测试人员主要是按照开发设计,对请求体的数据内容进行自由设计,然后测试服务器返回的相应数 据与预期是否一致。
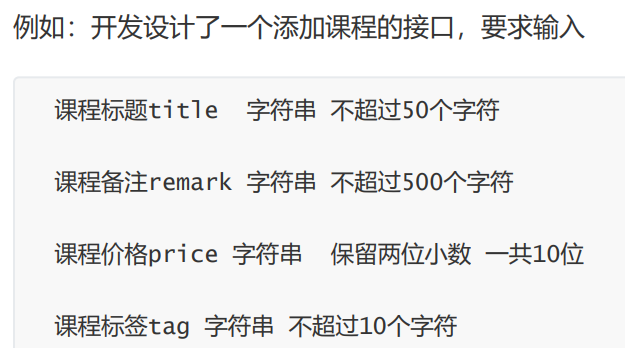
那么我们就需要对输入数据进行用例设计,测试服务器的响应数据与需求规定的预期是否一致 。


第一部分:请求行组成:请求方法,路径,所用协议
GET说明请求方法为GET,
[/562f25980001b1b106000338.jpg]为要访问的资源,
该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息
从第二行起为请求头部,HOST将指出请求的目的地.
User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
空行,请求头部后面的空行是必须的,即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。
HTTP之响应消息Response
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、响应头、空行和响应正文。
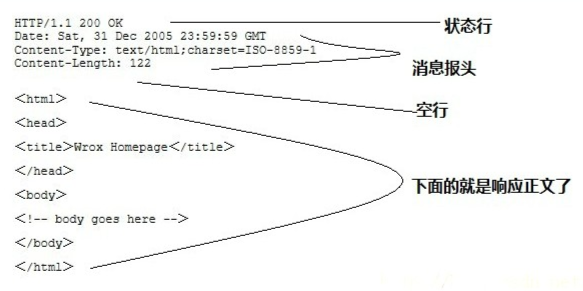
第一部分:状态行:HTTP协议版本号, 状态码, 状态消息
第一行为状态行,描述服务器处理客户端请求的结果
(HTTP/1.1)表明HTTP版本为1.1版本,
状态码为200,
状态消息为(ok)
HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
响应头 响应头和请求头结构和内容都一样,不同的是响应头是对响应数据的描述。用来说明客户端要使用的一些附加信息
例如,响应头中的Content-Type,描述的是响应正文的内容格式类型
空行,消息报头后面的空行是必须的
服务器返回给客户端的文本信息。响应正文 经过服务器处理后的响应数据。
响应数据类型包括:html、xml、text、json、图片等等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号