
第四次作业:Selenium 爬虫与大数据实时分析处理实验
一、作业内容
1.1 作业①:使用 Selenium 爬取股票数据
作业描述:
在本次作业中,我们使用 Selenium 框架结合 MySQL 数据库技术爬取了“沪深A股”、“上证A股”、“深证A股”这三个板块的股票数据。通过模拟浏览器操作,获取动态加载的网页内容,并将结果存入 MySQL 数据库中。爬取的数据包括股票的基本信息,如:股票代码、名称、最新报价、涨跌幅、成交量等。
作业代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import time
import pymysql
# 配置 WebDriver 的路径
driver_path = r"C:\Users\A\Desktop\牢豪\webdriver_edge\edgedriver_win64 (1)\msedgedriver.exe"
service = Service(executable_path=driver_path)
# 启动 WebDriver
driver = webdriver.Edge(service=service)
driver.maximize_window()
# 打开目标网站
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
driver.get(url)
print("页面已打开,等待页面加载...")
# 定义板块列表和对应的板块按钮XPath
board_info = {
"沪深A股": '//*[@id="nav_hs_a_board"]',
"上证A股": '//*[@id="nav_sh_a_board"]',
"深证A股": '//*[@id="nav_sz_a_board"]'
}
# 定义一个函数,用于清理并转换为浮点数
def clean_and_convert(text, field_name, stock_code):
if text == '-':
return None
cleaned_text = re.sub(r"[^\d.]", "", text)
try:
return float(cleaned_text)
except ValueError:
print(f"字段解析错误:股票代码 {stock_code},字段 {field_name},值 '{text}' 解析失败,跳过该行")
return None
# 定义一个函数,用于抓取当前页面的数据
def scrape_page():
rows = driver.find_elements(By.XPATH, '//*[@id="table_wrapper-table"]/tbody/tr')
page_data = []
for index, row in enumerate(rows, start=1):
try:
bStockNo = row.find_element(By.XPATH, f'./td[2]/a').text
bStockName = row.find_element(By.XPATH, f'./td[3]/a').text
bLatestPrice = clean_and_convert(row.find_element(By.XPATH, './td[5]/span').text, "最新报价", bStockNo)
bChangePercent = row.find_element(By.XPATH, f'./td[6]/span').text
bChange = clean_and_convert(row.find_element(By.XPATH, f'./td[7]/span').text, "涨跌额", bStockNo)
bVolume = row.find_element(By.XPATH, f'./td[8]').text
bTurnover = row.find_element(By.XPATH, f'./td[9]').text
bAmplitude = clean_and_convert(row.find_element(By.XPATH, f'./td[10]').text, "振幅", bStockNo)
bHighestPrice = clean_and_convert(row.find_element(By.XPATH, f'./td[11]/span').text, "最高", bStockNo)
bLowestPrice = clean_and_convert(row.find_element(By.XPATH, f'./td[12]/span').text, "最低", bStockNo)
bTodayOpening = clean_and_convert(row.find_element(By.XPATH, f'./td[13]/span').text, "今开", bStockNo)
bYesterdayClose = clean_and_convert(row.find_element(By.XPATH, f'./td[14]').text, "昨收", bStockNo)
stock = {
"bStockNo": bStockNo,
"bStockName": bStockName,
"bLatestPrice": bLatestPrice,
"bChangePercent": bChangePercent,
"bChange": bChange,
"bVolume": bVolume,
"bTurnover": bTurnover,
"bAmplitude": bAmplitude,
"bHighestPrice": bHighestPrice,
"bLowestPrice": bLowestPrice,
"bTodayOpening": bTodayOpening,
"bYesterdayClose": bYesterdayClose
}
page_data.append(stock)
except Exception as e:
print(f"数据解析失败,跳过行 {index},错误:{e}")
return page_data
# 遍历每个板块并爬取第一页数据
all_stocks_data = []
for board_name, board_xpath in board_info.items():
# 切换到该板块
board_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, board_xpath)))
board_button.click()
time.sleep(3) # 等待板块数据加载
print(f"切换到板块:{board_name}")
# 仅抓取当前板块第一页数据
page_data = scrape_page()
all_stocks_data.extend(page_data)
print(f"{board_name} 第一页数据抓取完成,共抓取 {len(page_data)} 条数据。")
# 关闭 WebDriver
driver.quit()
# 打印抓取的所有数据
print("所有板块的第一页数据抓取完成,总数据量:", len(all_stocks_data))
for stock in all_stocks_data[:5]: # 打印前5条数据检查
print(stock)
# 数据库配置
db_config = {
'host': 'localhost',
'user': 'root', # MySQL 用户名
'password': '123456', # MySQL 密码
'database': 'stock_data',
'charset': 'utf8mb4'
}
# 连接数据库
connection = pymysql.connect(**db_config)
cursor = connection.cursor()
# SQL 插入语句,使用反引号避免关键字冲突
insert_query = """
INSERT INTO stock_info (
stock_no, stock_name, latest_price, change_percent, `change`, volume,
turnover, amplitude, highest_price, lowest_price, today_opening, yesterday_close
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
# 使用批量插入数据
try:
# 执行批量插入
cursor.executemany(insert_query, [
(
stock["bStockNo"], stock["bStockName"], stock["bLatestPrice"],
stock["bChangePercent"], stock["bChange"], stock["bVolume"],
stock["bTurnover"], stock["bAmplitude"], stock["bHighestPrice"],
stock["bLowestPrice"], stock["bTodayOpening"], stock["bYesterdayClose"]
) for stock in all_stocks_data
])
# 提交事务
connection.commit()
print(f"成功插入 {cursor.rowcount} 条数据到数据库。")
except pymysql.MySQLError as e:
print(f"数据插入失败:{e}")
connection.rollback()
finally:
# 关闭数据库连接
cursor.close()
connection.close()
print("数据库连接已关闭。")
代码成果展示:
通过执行上面的代码,我们成功地爬取了股票数据,并存储到 MySQL 数据库中。以下是存储的一部分数据展示
| id | stock_no | stock_name | latest_price | change_percent | change | volume | turnover | amplitude | highest_price | lowest_price | today_opening | yesterday_close |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 920111 | 聚星科技 | 30.9 | 30.00% | 7.13 | 28.17万 | 7.54亿 | 34.88 | 30.9 | 22.61 | 23.7 | 23.77 |
| 2 | 832278 | 鹿得医疗 | 11.89 | 29.95% | 2.74 | 27.96万 | 3.23亿 | 26.67 | 11.89 | 9.45 | 9.55 | 9.15 |
| 3 | 837046 | 亿能电力 | 19.33 | 20.14% | 3.24 | 15.85万 | 2.69亿 | 35.55 | 20.6 | 14.88 | 15.95 | 16.09 |
| 4 | 300391 | 长药控股 | 8.14 | 20.06% | 1.36 | 104.53万 | 8.21亿 | 19.91 | 8.14 | 6.79 | 6.79 | 6.78 |
| 5 | 301000 | 肇民科技 | 20.93 | 20.01% | 3.49 | 9.17万 | 1.91亿 | 8.14 | 20.93 | 19.51 | 19.51 | 17.44 |
| 6 | 301212 | 联盛化学 | 26.45 | 20.01% | 4.41 | 5.81万 | 1.47亿 | 20.55 | 26.45 | 21.92 | 22.2 | 22.04 |
| 7 | 300937 | 药易购 | 32.69 | 20.01% | 5.45 | 11.21万 | 3.55亿 | 19.9 | 32.69 | 27.27 | 27.67 | 27.24 |
| 8 | 301209 | 联合化学 | 33.89 | 20.01% | 5.65 | 9.20万 | 3.06亿 | 19.76 | 33.89 | 28.31 | 28.31 | 28.24 |
| 9 | 688499 | 利元亨 | 35.57 | 20.01% | 5.93 | 33.11万 | 10.64亿 | 22.5 | 35.57 | 28.9 | 29.71 | 29.64 |
| 10 | 300912 | 凯龙高科 | 15.84 | 20.00% | 2.64 | 9.47万 | 1.47亿 | 14.02 | 15.84 | 13.99 | 13.99 | 13.2 |
| 11 | 300878 | 维康药业 | 21.84 | 20.00% | 3.64 | 8.98万 | 1.87亿 | 20 | 21.84 | 18.2 | 18.2 | 18.2 |
| 12 | 300622 | 博士眼镜 | 46.44 | 20.00% | 7.74 | 31.60万 | 13.57亿 | 23.62 | 46.44 | 37.3 | 38.32 | 38.7 |
| 13 | 300546 | 雄帝科技 | 23.05 | 19.99% | 3.84 | 21.08万 | 4.71亿 | 18.48 | 23.05 | 19.5 | 19.7 | 19.21 |
| 14 | 688089 | 嘉必优 | 25.1 | 19.98% | 4.18 | 8997 | 2258.16万 | 0 | 25.1 | 25.1 | 25.1 | 20.92 |
| 15 | 300277 | 海联讯 | 17.3 | 19.97% | 2.88 | 2.16万 | 3735.68万 | 0 | 17.3 | 17.3 | 17.3 | 14.42 |
| 16 | 832471 | 美邦科技 | 20.61 | 18.31% | 3.19 | 13.07万 | 2.77亿 | 24.86 | 22.64 | 18.31 | 18.97 | 17.42 |
| 17 | 688691 | 灿芯股份 | 90.51 | 16.07% | 12.53 | 14.32万 | 12.68亿 | 16.77 | 93.58 | 80.5 | 85 | 77.98 |
| 18 | 301239 | 普瑞眼科 | 58.46 | 15.88% | 8.01 | 12.96万 | 7.51亿 | 18.93 | 60.54 | 50.99 | 50.99 | 50.45 |
| 19 | 301325 | 曼恩斯特 | 61.7 | 15.72% | 8.38 | 21.62万 | 13.29亿 | 12.25 | 63.98 | 57.45 | 59 | 53.32 |
| 20 | 870299 | 灿能电力 | 14.87 | 15.45% | 1.99 | 11.60万 | 1.58亿 | 26.4 | 15.6 | 12.2 | 12.85 | 12.88 |
| 21 | 688499 | 利元亨 | 35.57 | 20.01% | 5.93 | 33.11万 | 10.64亿 | 22.5 | 35.57 | 28.9 | 29.71 | 29.64 |
| 22 | 688089 | 嘉必优 | 25.1 | 19.98% | 4.18 | 8997 | 2258.16万 | 0 | 25.1 | 25.1 | 25.1 | 20.92 |
| 23 | 688691 | 灿芯股份 | 90.51 | 16.07% | 12.53 | 14.32万 | 12.68亿 | 16.77 | 93.58 | 80.5 | 85 | 77.98 |
1.2 作业心得:
在这个作业中,我不仅学习了如何使用 Selenium 进行动态网页数据爬取,还深入了解了如何与 MySQL 数据库结合进行数据存储。通过设置等待条件(WebDriverWait),我能够确保页面加载完成后再进行数据抓取,避免了因数据未完全加载而导致的错误。
此外,我对数据的存储结构进行了设计,确保了表头的英文命名和数据的规范存储。在爬取过程中,遇到的挑战是如何提取表格中的每一行数据,最终通过定位 td 标签并获取其文本值,成功解决了问题。
2.1 作业②:模拟登录并爬取课程数据
作业描述:
本次作业要求我们模拟登录中国 MOOC 网站(https://www.icourse163.org),通过程序实现自动化登录,并抓取课程数据,包括课程名称、学校、教师、团队成员、参与人数、课程进度、课程简介等信息。最后将抓取到的数据存储到本地的 MySQL 数据库中。
作业代码:
from selenium.webdriver.common.by import By
from selenium import webdriver
import time
import mysql.connector
# MySQL数据库连接
conn = mysql.connector.connect(
host="127.0.0.1",
# port="8000",
user="root",
password="123456",
database="mooc_db"
)
cursor = conn.cursor()
# 创建MOOC表格
cursor.execute("""
CREATE TABLE IF NOT EXISTS mooc (
Id INT PRIMARY KEY AUTO_INCREMENT,
cCourse VARCHAR(100),
cCollege VARCHAR(100),
cTeacher VARCHAR(100),
cTeam VARCHAR(200),
cCount INT,
cProcess VARCHAR(100),
cBrief TEXT
)
""")
conn.commit()
# 插入数据的SQL语句
sql = """
INSERT INTO mooc (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
# 用户登录信息
user_name = "15862616622"
password = "Cyh12345"
# 启动Microsoft Edge浏览器并打开页面
edge_options = webdriver.EdgeOptions()
# edge_options.add_argument("--headless") # 如果不需要显示浏览器,可以启用headless模式
driver = webdriver.Edge(options=edge_options)
driver.maximize_window()
driver.get("https://www.icourse163.org/")
# 点击同意隐私政策
try:
driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div').click()
time.sleep(3)
except Exception as e:
print("隐私政策按钮未找到:", e)
# 切换到登录 iframe
iframe = driver.find_element(By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
# 输入账号密码并登录
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input').send_keys(user_name)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys(password)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
# 等待页面加载完成
time.sleep(5)
driver.switch_to.default_content() # 切换回默认页面
time.sleep(3)
# 进入课程页面
driver.find_element(By.XPATH, '/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[1]/div[1]/span[1]/a').click()
driver.switch_to.window(driver.window_handles[-1])
# 分页循环获取课程数据
for _ in range(2): # 你可以根据需求调整页数
for i in range(5): # 假设每页有5门课程
try:
# 获取每个课程的基本信息
course_info = driver.find_element(By.XPATH, f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{i+1}]/div/div[3]/div[1]').text.split("\n")
driver.find_element(By.XPATH, f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{i+1}]').click()
# 切换到新打开的课程页面
driver.switch_to.window(driver.window_handles[-1])
# 获取团队成员
team = driver.find_elements(By.XPATH, '//*[@class="f-fc3"]')
team_list = [t.text for t in team]
course_info.append(','.join(team_list))
# 获取课程人数
try:
count = driver.find_element(By.XPATH, '//*[@class="count"]').text
except:
count = "已有0人参加"
course_info.append(count[2:-3]) # 处理人数字段
# 获取课程时间
try:
date = driver.find_element(By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]').text
except:
date = "无"
course_info.append(date)
# 获取课程简介
brief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text
course_info.append(brief)
# 插入数据库
values = (course_info[0], course_info[1], course_info[2], course_info[3], int(course_info[4]), course_info[5], course_info[6])
cursor.execute(sql, values)
conn.commit()
# 记录数据并关闭当前标签页
driver.close()
driver.switch_to.window(driver.window_handles[-1]) # 切换回主标签页
except Exception as e:
print(f"错误:{e}")
driver.close()
driver.switch_to.window(driver.window_handles[-1])
# 点击下一页按钮
try:
driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]').click()
time.sleep(2)
except Exception as e:
print("下一页按钮未找到或点击失败:", e)
break
# 关闭数据库连接
cursor.close()
conn.close()
代码成果展示:
展示爬取到的一些课程数据:
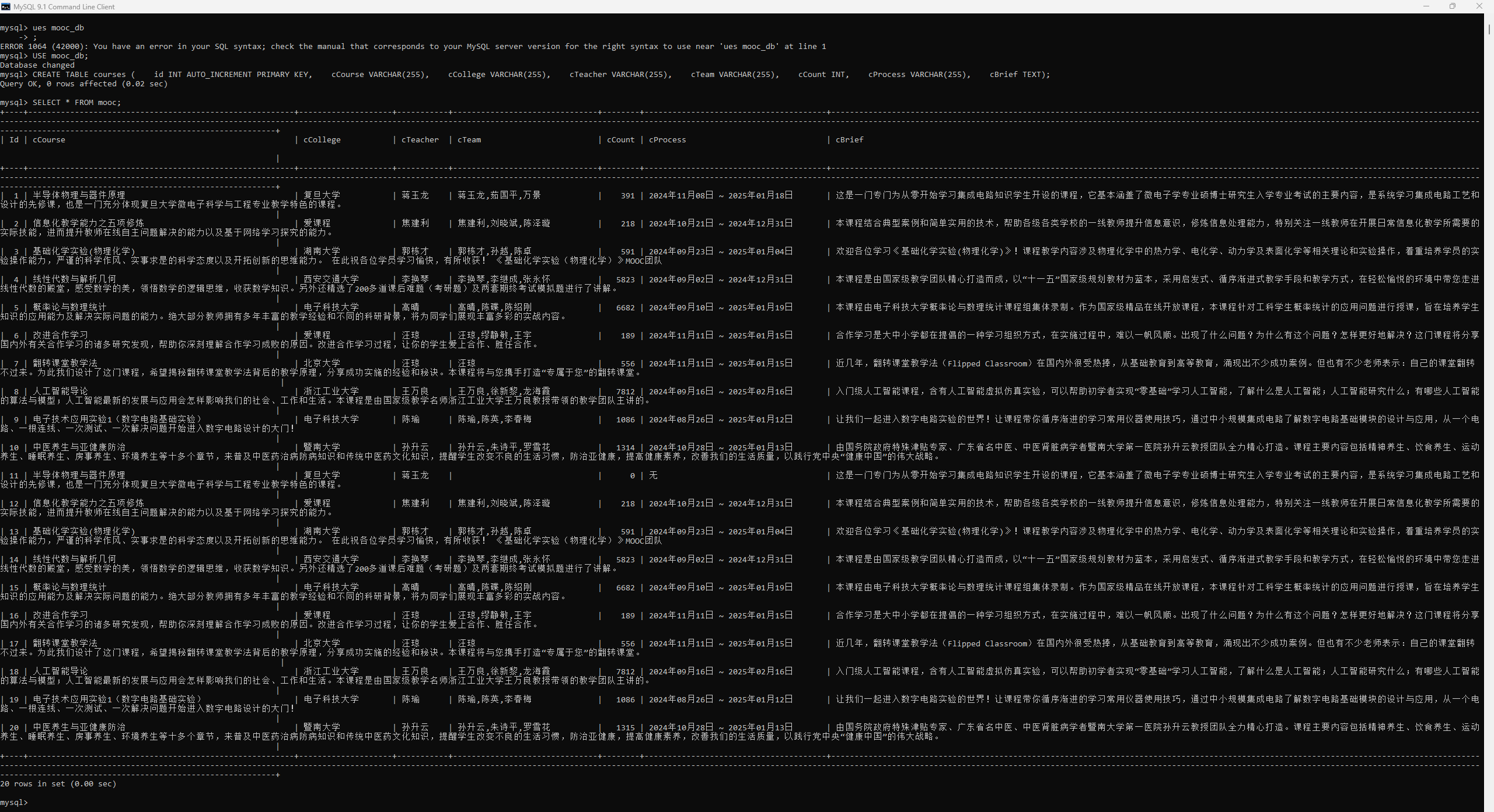
2.2 作业心得:
在完成这次 MOOC 课程数据爬取作业过程中,收获颇丰,同时也遇到了一些挑战。
- 模拟登录的难点:模拟登录中国 MOOC 网站需要处理多个
iframe和动态加载元素,首次使用 Selenium 的switch_to.frame方法来切换不同的 iframe,以便顺利完成登录。这对我来说是一个新学习的过程。了解了网页的分层结构和 Selenium 对 iframe 的处理方式后,逐步解决了这个难点。 - 数据清洗和异常处理:MOOC 页面上课程数据分布不均,一些字段存在缺失或格式不同的情况。为此我在代码中添加了异常处理机制,用来应对缺失数据。例如,某些课程没有团队成员或具体参与人数,代码会捕获并跳过这些异常,保证程序稳定运行。同时,这让我意识到在数据爬取中,保持数据一致性的重要性。
- 数据库设计和批量插入的优化:使用 MySQL 数据库来存储课程数据时,我为每门课程设置了多种字段,包括课程名称、学校、教师、课程简介等。为了提高数据写入的效率,我选择了批量插入的方法,先将所有数据存储在列表中,然后一次性写入数据库。这不仅减少了数据库连接时间,还提升了程序的执行效率。
- 爬虫优化和反爬机制:在多页爬取过程中,我使用了动态延时加载页面的策略,但仍然发现需要设置适当的等待时间来避免频繁请求导致封禁。理解和优化爬取流程有助于避免触发网站的反爬机制。
通过这次作业,我加深了对 Selenium 自动化操作的理解,掌握了处理 iframe、异常捕获、数据清洗等实际操作技巧,同时对数据库设计和批量插入的优化也有了实际的应用。整个过程增强了我对爬虫技术和数据采集流程的信心,为今后类似的项目打下了扎实的基础。
三、作业③:大数据实时分析处理实验
3.1 作业③:Flume 日志采集实验
作业描述:
要求开通MapReduce服务并配置相关环境,使用Python脚本生成测试日志数据,配置Kafka服务并创建主题以接收数据,安装并配置Flume客户端,设置日志采集并将数据流送入Kafka。最后,需截取关键步骤或结果的截图作为输出。
任务操作:
-
环境搭建:
-
任务一:开通MapReduce服务
-
实时分析开发实战
-
任务一:Python脚本生成测试数据
-
任务二:配置Kafka
-
任务三: 安装Flume客户端
-
任务四:配置Flume采集数据
成果展示:
-
开通MapReduce服务
![]()
![]()
![]()
![]()
-
Python脚本生成测试数据
![]()
-
配置Kafka
-
安装Flume客户端
-
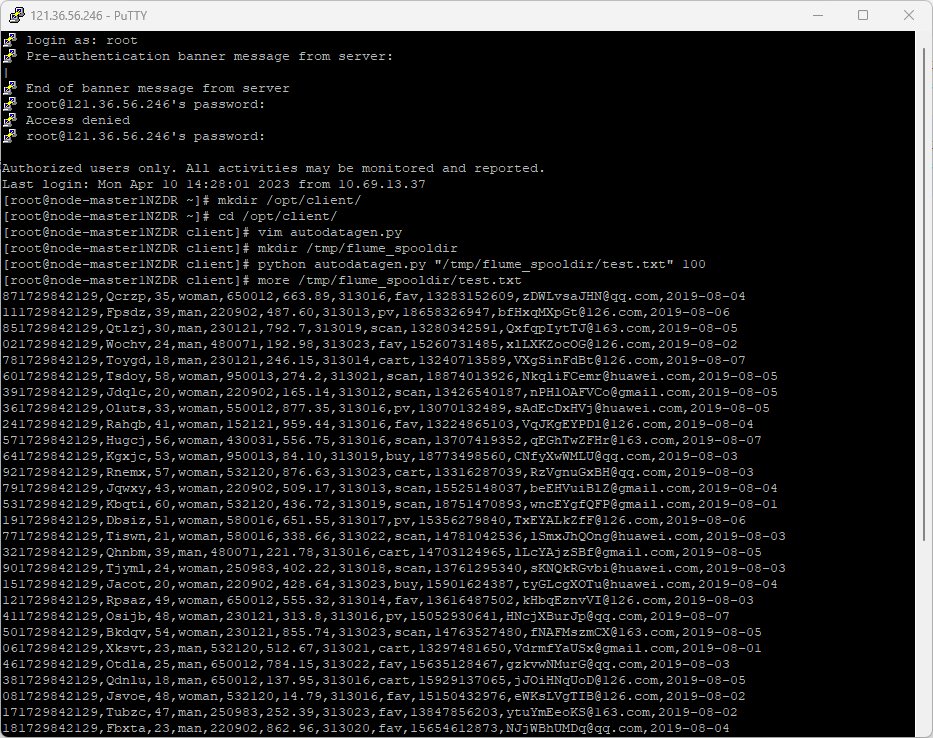
配置Flume采集数据
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()





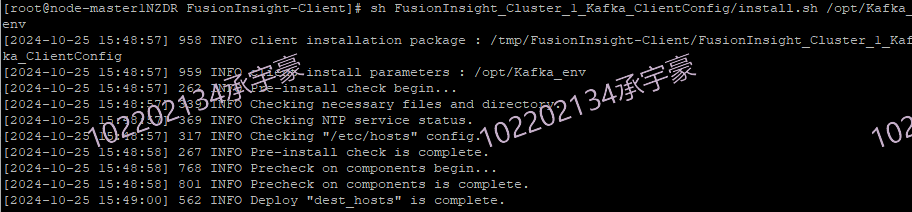

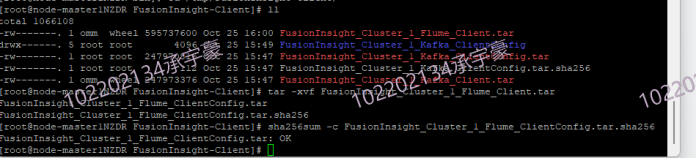




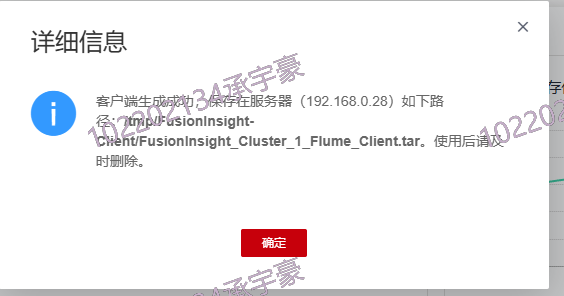
3.2 作业心得:
在本次实验中,我们成功完成了从集群环境配置到数据分析与可视化展示的完整流程。通过华为云平台的大数据技术,熟悉了多种工具的使用,深刻理解了离线数据分析的步骤和流程。实验结果也证明了使用大数据工具进行数据管理和分析的强大功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号