
数据采集与融合:第一次作业报告
| 作业属于哪个课程 | 首页 - 2024数据采集与融合技术实践 - 福州大学 - 班级博客 - 博客园 (cnblogs.com) |
|---|---|
| 作业要求链接 | 作业1 - 作业 - 2024数据采集与融合技术实践 - 班级博客 - 博客园 (cnblogs.com)v |
| 学号姓名 | 102202134 承宇豪 |
一、作业概述
在本次作业中,我完成了以下三个任务:
- 用
requests和BeautifulSoup库方法爬取中国大学排名信息。 - 用
requests和re库设计爬虫,定向爬取某个商城关键词"书包"搜索页面商品数据。 - 爬取当当网书包网页的所有JPEG和JPG格式文件。
二、任务一:用requests和BeautifulSoup库方法定向爬取给定网址
1. 实现代码
import requests
from bs4 import BeautifulSoup
# 目标网址
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
}
# 发送 HTTP 请求
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 设置编码格式
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找排名信息的表格
table = soup.find('table')
# 打印表头
print("排名\t学校名称\t省市\t学校类型\t总分")
# 遍历表格中的每一行
for tr in table.tbody.find_all('tr'):
tds = tr.find_all('td')
rank = tds[0].text.strip()
name = tds[1].text.strip()
province = tds[2].text.strip()
category = tds[3].text.strip()
score = tds[4].text.strip()
print(f"{rank}\t{name}\t{province}\t{category}\t{score}")
2. 运行结果

3. 心得体会
通过本次任务,我学习了如何使用BeautifulSoup爬取天气数据并将其保存到SQLite数据库中。特别是在处理网页编码时,使用了requests.encoding确保获取的内容正确解析。同时,SQLite的使用也让我对数据的本地存储有了更深入的理解。
三、任务二:用requests和re库方法设计当当网商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
1. 实现代码
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
def scrape_dangdang_bags_selenium():
# 配置Edge浏览器选项
edge_options = Options()
edge_options.use_chromium = True # 使用Chromium内核
edge_options.add_argument('--disable-gpu')
# 指定Edge WebDriver的路径
service = Service(executable_path=r'C:\WebDriver\msedgedriver.exe')
# 使用Service对象来启动Edge WebDriver
driver = webdriver.Edge(service=service, options=edge_options)
# 当当网搜索“书包”的URL
url = 'http://search.dangdang.com/?key=书包&act=input'
# 访问页面
driver.get(url)
try:
# 等待商品列表元素加载完成
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.XPATH, '//ul[@id="component_59"]/li'))
)
print("商品列表加载完成。")
# 获取商品列表
products = driver.find_elements(By.XPATH, '//ul[@id="component_59"]/li')
print(f"找到 {len(products)} 个商品。")
# 打印结果
print('序号\t价格\t商品名')
idx = 1
for product in products:
try:
# 获取商品名称
name = product.find_element(By.XPATH, './/a[@name="itemlist-title"]').get_attribute('title')
# 获取所有价格(使用 class="price_n" 的元素)
price_elements = product.find_elements(By.XPATH, './/span[@class="price_n"]')
# 如果找到价格元素,取第一个价格
if price_elements:
price = price_elements[0].text.strip('¥')
else:
price = "未找到价格"
print(f'{idx}\t{price}\t{name}')
idx += 1
except Exception as e:
print(f"商品解析失败:{e}")
continue
except Exception as e:
print(f"页面加载失败:{e}")
# 保留浏览器窗口用于调试
input("按回车键关闭浏览器...")
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
scrape_dangdang_bags_selenium()
2. 运行结果
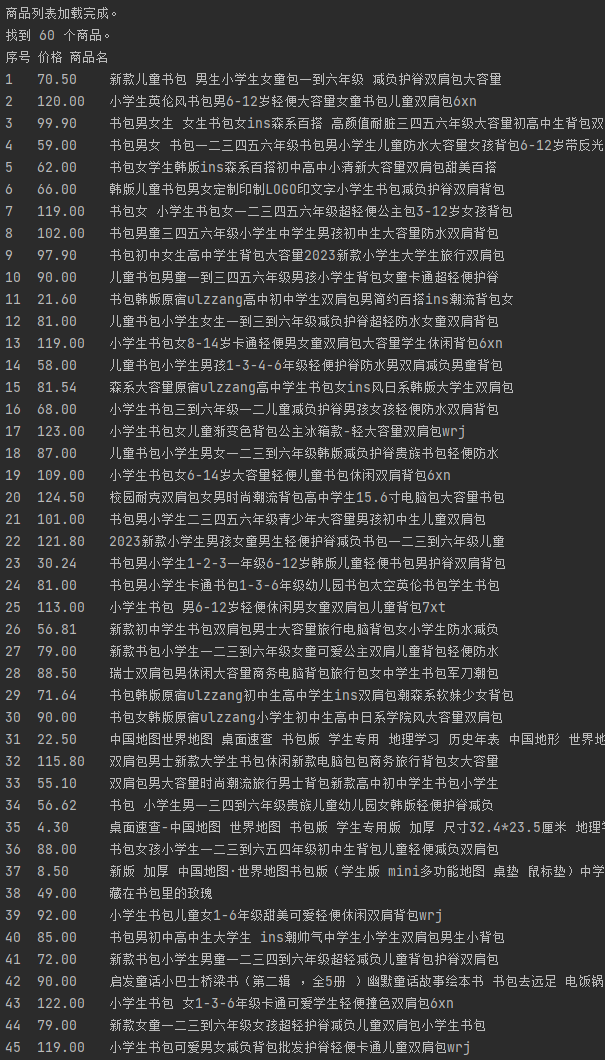
3. 心得体会
在这个任务中,我通过对商城页面的分析,发现商品信息嵌入在动态加载的内容中。通过requests和re库,我成功地解析出商品名称和价格信息。这让我意识到正则表达式在处理网页文本和提取特定格式数据中的强大作用。
四、任务三:爬取网页图片文件
1. 实现代码
import os
import requests
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def download_image(image_url, save_path):
try:
# 如果URL以 // 开头,补全为 https://
if image_url.startswith("//"):
image_url = "https:" + image_url
# 发送请求并获取图片数据
response = requests.get(image_url, stream=True)
if response.status_code == 200:
# 保存图片
with open(save_path, 'wb') as file:
for chunk in response.iter_content(1024):
file.write(chunk)
print(f"图片下载成功: {save_path}")
else:
print(f"无法下载图片: {image_url}")
except Exception as e:
print(f"下载失败: {image_url}, 错误信息: {e}")
def scrape_dangdang_bags_images():
# 配置Edge浏览器选项
edge_options = Options()
edge_options.use_chromium = True # 使用Chromium内核
edge_options.add_argument('--disable-gpu')
# 指定Edge WebDriver的路径
service = Service(executable_path=r'C:\WebDriver\msedgedriver.exe')
# 使用Service对象来启动Edge WebDriver
driver = webdriver.Edge(service=service, options=edge_options)
# 当当网搜索“书包”的URL
url = 'http://search.dangdang.com/?key=书包&act=input'
# 访问页面
driver.get(url)
# 等待商品列表元素加载完成
try:
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.XPATH, '//ul[@id="component_59"]/li'))
)
print("商品列表加载完成。")
# 获取商品列表
products = driver.find_elements(By.XPATH, '//ul[@id="component_59"]/li')
print(f"找到 {len(products)} 个商品。")
# 图片保存路径
save_folder = r'C:\Users\A\Desktop\数据采集\sj1\jpg'
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 遍历商品,下载图片
idx = 1
for product in products:
try:
# 获取商品图片URL,优先使用data-original属性
image_element = product.find_element(By.XPATH, './/img')
image_url = image_element.get_attribute('data-original')
# 如果没有 data-original,使用 src
if not image_url:
image_url = image_element.get_attribute('src')
# 设置图片保存路径
image_name = f"bag_image_{idx}.jpg"
save_path = os.path.join(save_folder, image_name)
# 下载图片
download_image(image_url, save_path)
idx += 1
except Exception as e:
print(f"商品图片解析失败: {e}")
continue
except Exception as e:
print(f"页面加载失败: {e}")
# 保留浏览器窗口用于调试
input("按回车键关闭浏览器...")
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
scrape_dangdang_bags_images()
2. 运行结果
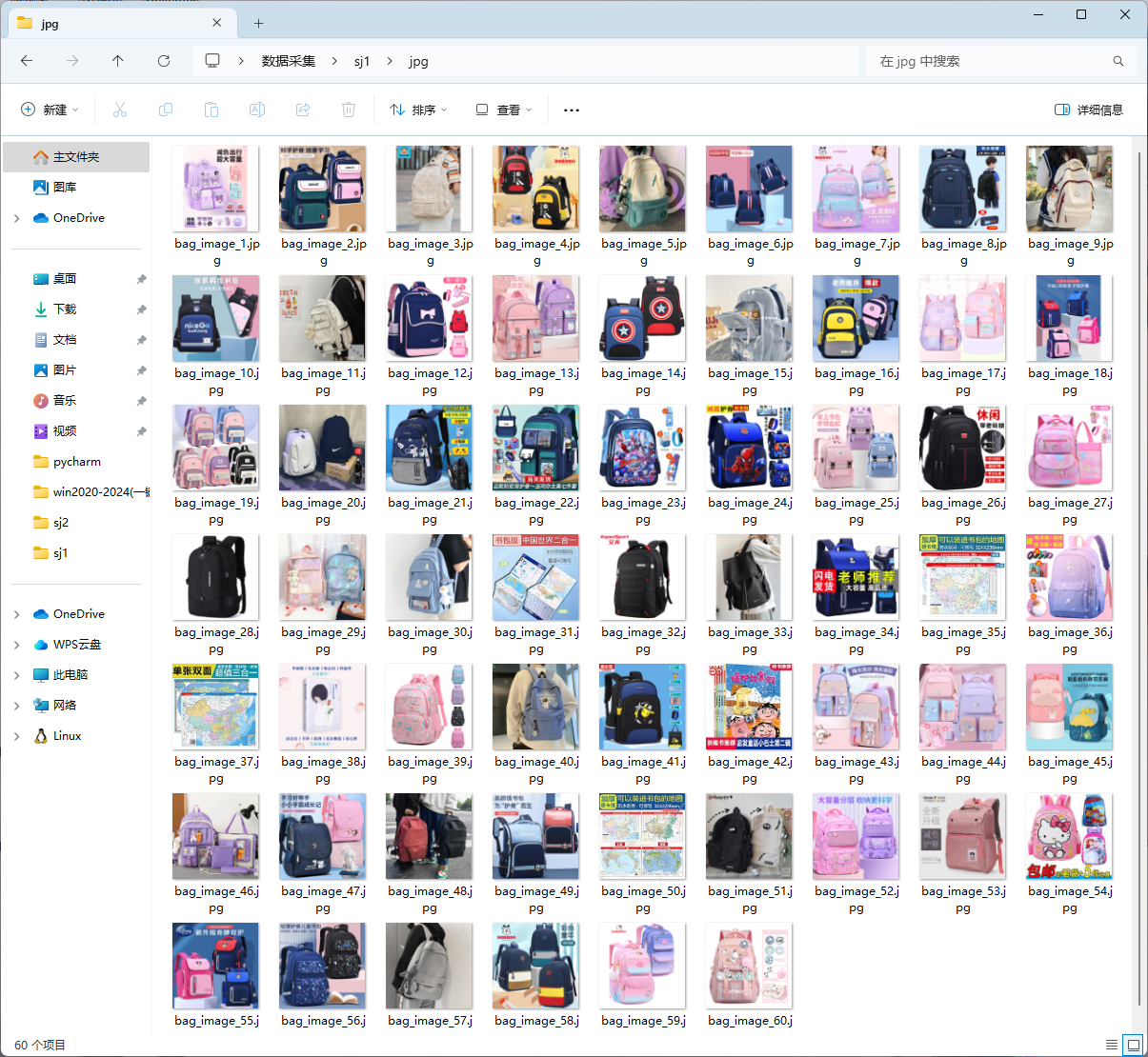
3. 心得体会
通过爬取网页中的图片,我学会了如何处理静态资源的抓取。在分析网页内容时,通过筛选特定的URL链接并下载图片,可以更深入地了解网页结构及资源管理方式。将爬取的文件保存到本地后,也掌握了如何在爬虫中处理文件存储操作。
五、总结
这次作业让我在爬取静态网页数据、处理API接口及抓取网页资源方面有了较深入的理解。通过三次任务,我掌握了requests、BeautifulSoup、re等库的基本使用,并在处理不同类型的数据时有了更丰富的经验。在今后的学习中,我会继续优化爬虫结构,提升代码效率和数据处理能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号