
数据采集与融合:第二次作业报告
| 作业属于哪个课程 | 数据采集与融合技术 |
|---|---|
| 作业要求链接 | 作业要求链接 |
| 学号姓名 | 学号姓名:102202134 承宇豪 |
码云链接:承宇豪/数据采集与融合技术实践2 - Gitee.com
一、作业概述
在本次作业中,我完成了以下三个任务:
- 从中国气象网获取7日天气预报,并保存到数据库。
- 在东方财富网爬取股票信息并存储在数据库中。
- 爬取中国大学2021年主榜数据,生成Excel文件并记录调试过程。
二、任务一:获取7日天气预报
1. 实现代码
import sqlite3
import requests
from bs4 import BeautifulSoup
# 获取天气数据的函数
def get_weather_data(city_code):
# 定义目标URL
url = f"http://www.weather.com.cn/weather/{city_code}.shtml"
# 发送请求获取网页内容
response = requests.get(url)
response.encoding = 'utf-8' # 确保编码正确
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取7天的天气信息
forecast_data = []
forecast_list = soup.find('ul', class_='t clearfix').find_all('li')
for day in forecast_list:
date = day.find('h1').text # 获取日期
weather = day.find('p', class_='wea').text # 获取天气信息
temperature_high = day.find('span').text if day.find('span') else '' # 最高温度
temperature_low = day.find('i').text # 最低温度
forecast_data.append({
"date": date,
"weather": weather,
"temperature_high": temperature_high,
"temperature_low": temperature_low
})
return forecast_data
# 保存数据到SQLite数据库的函数
def save_to_database(data, city_name):
# 连接到SQLite数据库(如果不存在则创建)
conn = sqlite3.connect(f'{city_name}_weather.db')
cursor = conn.cursor()
# 创建天气表(如果不存在)
cursor.execute('''
CREATE TABLE IF NOT EXISTS weather (
id INTEGER PRIMARY KEY AUTOINCREMENT,
date TEXT,
weather TEXT,
temperature_high TEXT,
temperature_low TEXT
)
''')
# 插入数据
for entry in data:
cursor.execute('''
INSERT INTO weather (date, weather, temperature_high, temperature_low)
VALUES (?, ?, ?, ?)
''', (entry["date"], entry["weather"], entry["temperature_high"], entry["temperature_low"]))
# 提交更改并关闭连接
conn.commit()
conn.close()
# 主函数调用
if __name__ == '__main__':
city_code = '101010100' # 北京的城市代码
city_name = 'beijing' # 数据库名称
# 获取天气数据
weather_data = get_weather_data(city_code)
# 保存到数据库
save_to_database(weather_data, city_name)
print(f"数据已保存到 {city_name}_weather.db 数据库。")
2. 运行结果
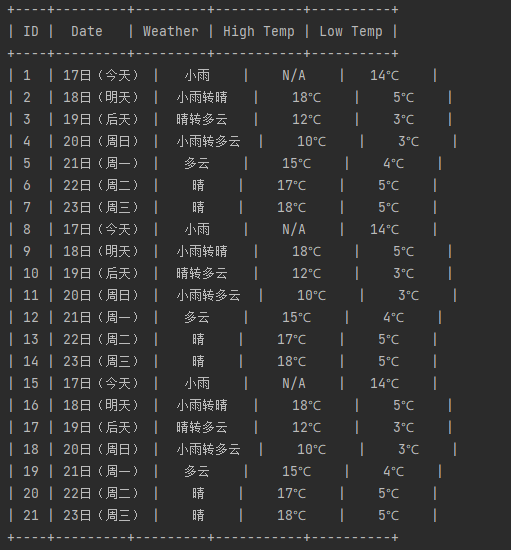
3. 心得体会
在该任务中,我主要学到了如何通过网页爬取获取天气数据,并用 SQLite 实现数据存储。这个过程中,通过 BeautifulSoup 提取 HTML 数据、 sqlite3 进行本地数据库存储,解决了网页编码转换、数据结构不一致等问题。
三、任务二:爬取股票信息并存储
1. 实现代码
import sqlite3
import requests
import json
# API请求URL
url = "https://70.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404241920708062452_1729179691648&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1729179691655"
# 设置请求头,模拟浏览器请求
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"
}
# 发送GET请求获取数据
response = requests.get(url, headers=headers)
# 获取返回的原始内容
raw_data = response.text
# 打印原始响应内容,确认返回的是什么
print(f"原始响应内容: {raw_data}")
# 去掉JSONP包裹,提取纯JSON数据
try:
# 找到括号的开始和结束位置
start_idx = raw_data.index('(') + 1
end_idx = raw_data.rindex(')')
# 截取JSON字符串
json_data = raw_data[start_idx:end_idx]
# 将JSON字符串转换为字典
data = json.loads(json_data)
stocks = data['data']['diff'] # 获取所有股票信息的列表
# 打开一个SQLite数据库连接(如果数据库不存在则会创建)
conn = sqlite3.connect('stock_data.db')
cursor = conn.cursor()
# 创建一个表(如果不存在)
cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
stock_code TEXT,
stock_name TEXT,
current_price REAL,
change_percentage REAL,
change_amount REAL,
trading_volume REAL
)
''')
# 遍历所有股票并将其数据插入到表中
for stock in stocks:
stock_code = stock['f12'] # 股票代码
stock_name = stock['f14'] # 股票名称
current_price = stock['f2'] # 当前价格
change_percentage = stock['f3'] # 涨跌幅
change_amount = stock['f4'] # 涨跌额
trading_volume = stock['f6'] # 成交金额
# 插入数据到表中
cursor.execute('''
INSERT INTO stocks (stock_code, stock_name, current_price, change_percentage, change_amount, trading_volume)
VALUES (?, ?, ?, ?, ?, ?)
''', (stock_code, stock_name, current_price, change_percentage, change_amount, trading_volume))
# 提交更改并关闭连接
conn.commit()
conn.close()
print("股票数据已成功保存到 stock_data.db 数据库中。")
except ValueError as e:
print(f"解析数据时出错: {e}")
2. 运行结果

3. 心得体会
在这个任务中,挑战在于如何从 API 获取 JSON 数据,并将其解析为数据库中的结构化信息。通过使用 requests 获取数据后,我通过 SQLite 进行数据的存储,掌握了如何优化数据存储和防止重复插入。
四、任务三:爬取中国大学2021主榜数据
1. 实现代码
import requests
import re
from openpyxl import Workbook
# 目标URL
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
# 发送请求获取网页内容
response = requests.get(url=url)
# 提取学校名称、分数、类型、省份
name = re.findall(',univNameCn:"(.*?)",', response.text) # 学校名称
score = re.findall(',score:(.*?),', response.text) # 学校总分
category = re.findall(',univCategory:(.*?),', response.text) # 学校类型
province = re.findall(',province:(.*?),', response.text) # 学校所在省份
# 用来替换参数的编码和含义
code_name = re.findall('function(.*?){', response.text)
start_code = code_name[0].find('a')
end_code = code_name[0].find('pE')
code_name = code_name[0][start_code:end_code].split(',') # 提取函数中的参数并存储到列表
value_name = re.findall('mutations:(.*?);', response.text)
start_value = value_name[0].find('(')
end_value = value_name[0].find(')')
value_name = value_name[0][start_value + 1:end_value].split(",") # 将参数对应的含义提取出来
# 创建一个新的 Excel 工作簿
wb = Workbook()
ws = wb.active
ws.title = "学校信息"
# 写入表头
ws.append(["排名", "学校", "省份", "类型", "总分"])
# 遍历数据并写入Excel
for i in range(len(name)):
province_name = value_name[code_name.index(province[i])][1:-1]
category_name = value_name[code_name.index(category[i])][1:-1]
# 写入每一行数据
ws.append([i + 1, name[i], province_name, category_name, score[i]])
# 保存到Excel文件
wb.save("school_data.xlsx")
print("数据已保存到 school_data.xlsx")
2. 运行结果

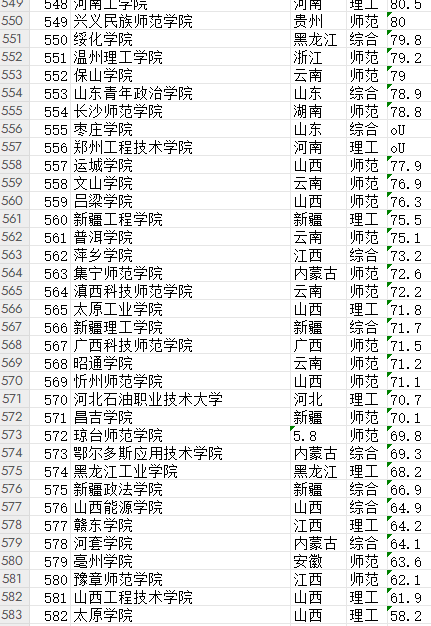
3. 调试过程
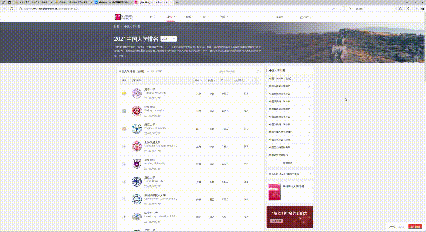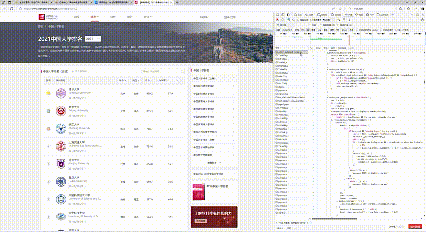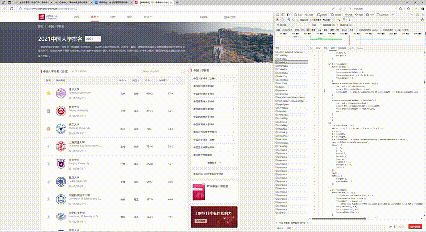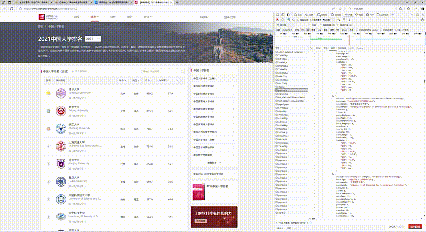
4. 心得体会
这个任务让我进一步了解了如何提取嵌入在 JavaScript 文件中的数据,并将其存储到 Excel 文件中。通过正则表达式高效地提取信息后,使用 openpyxl 生成了 Excel 文件,进一步加深了对网页爬取和数据处理的理解。
五、总结
通过这三个任务,我掌握了从网页和 API 获取数据、解析和存储的流程。无论是数据的提取、存储,还是处理编码问题,整个过程让我更加熟悉 Python 爬虫与数据存储的应用。这些技能将为我今后更复杂的爬虫项目打下坚实基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号