2023数据采集与融合技术实践作业4
作业①:
- 要求:
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。 - 候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board - Gitee链接:
https://gitee.com/cyosyo/crawl_project/tree/master/作业4/1
实验代码:
from selenium import webdriver
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import urllib.request
import sqlite3
con=sqlite3.connect('stock_selenium.db')
cur=con.cursor()
cur.execute('create table if not exists stock(id varchar(10),code varchar(10),name varchar(10),price varchar(10),change varchar(10),change_rate varchar(10),volume varchar(10),turnover varchar(10),amplitude varchar(10),high varchar(10),low varchar(10),open varchar(10),close varchar(10),primary key(id))')
count=1
print("id 代码 名称 最新价格 涨跌额 涨跌幅 成交量 成交额 振幅 最高 最低 今开 昨收")
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")
columns = {1: "代码", 2: "名称", 3: "最新价格", 4: "涨跌额", 5: "涨跌幅", 6: "成交量", 7: "成交额", 8: "振幅",
9: "最高", 10: "最低", 11: "今开", 12: "昨收"}
for j in range(1,11): //一共要爬取多少页
lis=driver.find_elements(by=By.XPATH,value="//*[@id='table_wrapper-table']/tbody/tr")
for i,li in enumerate(lis):
id=li.find_element_by_xpath("./td[1]").text
code=li.find_element_by_xpath("./td[2]/a").text
name=li.find_element_by_xpath("./td[3]/a").text
price=li.find_element_by_xpath("./td[5]").text
change=li.find_element_by_xpath("./td[7]").text
change_rate=li.find_element_by_xpath("./td[6]").text
volume=li.find_element_by_xpath("./td[8]").text
turnover=li.find_element_by_xpath("./td[9]").text
amplitude=li.find_element_by_xpath("./td[10]").text
high=li.find_element_by_xpath("./td[11]").text
low=li.find_element_by_xpath("./td[12]").text
open=li.find_element_by_xpath("./td[13]").text
close=li.find_element_by_xpath("./td[14]").text
print(id,code,name,price,change,change_rate,volume,turnover,amplitude,high,low,open,close)
cur.execute('insert into stock values(?,?,?,?,?,?,?,?,?,?,?,?,?)',(id,code,name,price,change,change_rate,volume,turnover,amplitude,high,low,open,close))
buttom=driver.find_element(by=By.XPATH,value="//*[@id='main-table_paginate']/a[2]")
buttom.click() //前往下一页
time.sleep(10)
con.commit()
con.close()
使用 selenium和Xpath对目标进行提取,然后通过buttom的click前往下一页。
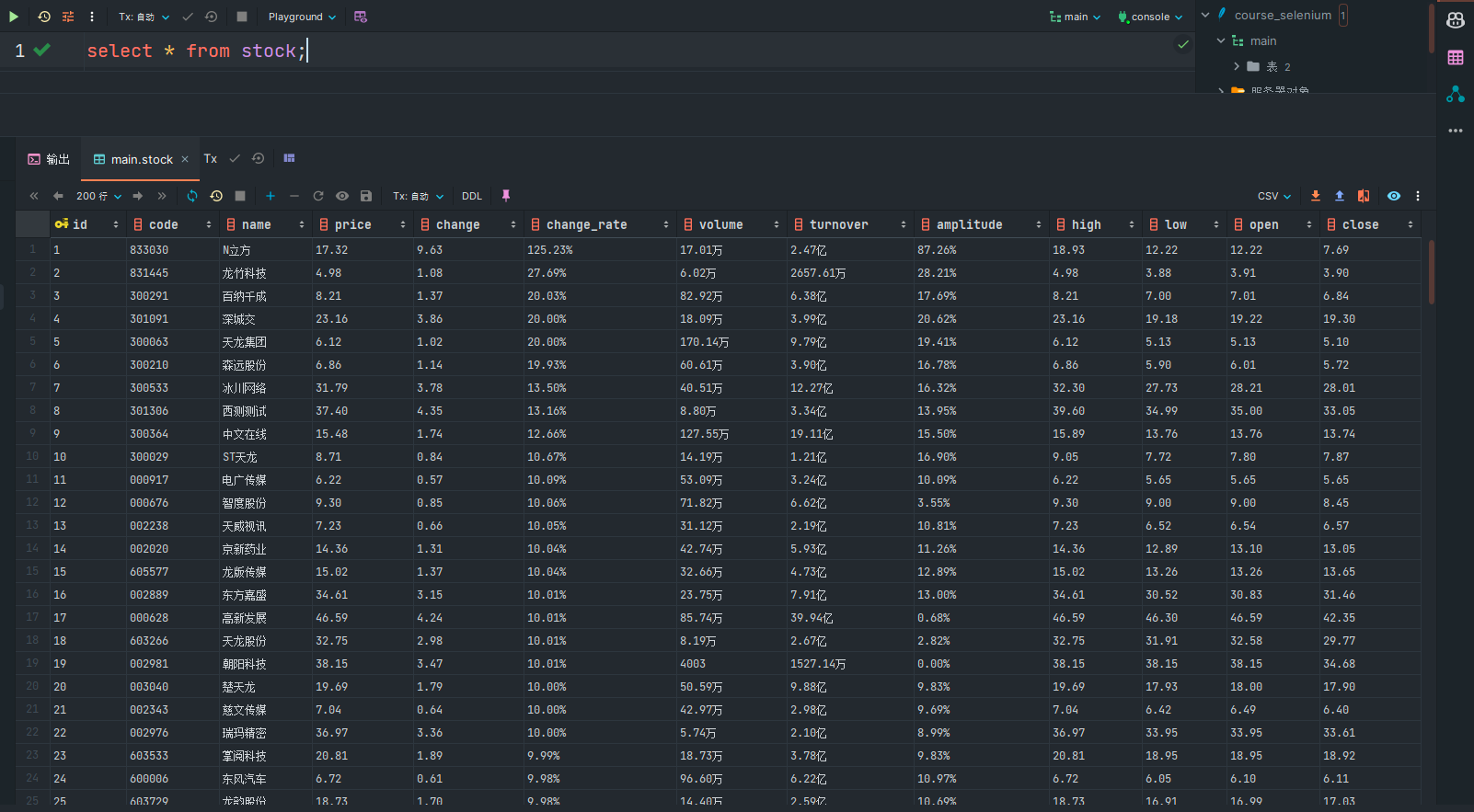
输出信息:
查询数据库文件得到写入信息:
心得体会:
通过这次学习,学到了selenium的用法,以及通过selenium对窗口的点击和数据的获取。
作业②:
- 要求:
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介) - 候选网站:
中国 mooc 网:https://www.icourse163.org - Gitee链接:
https://gitee.com/cyosyo/crawl_project/tree/master/作业4/2
实验代码:
from selenium import webdriver
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import urllib.request
import sqlite3
import re
con=sqlite3.connect('course_selenium.db')
cur=con.cursor()
cur.execute('create table if not exists course(id varchar(10),name varchar(10),college varchar(10),teacher varchar(10),teammate varchar(10),count varchar(10),process varchar(10),brief varchar(10),primary key(id))')
print("课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介")
chrome_options = webdriver.ChromeOptions()
#chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://www.icourse163.org/channel/2001.htm")
lis=driver.find_elements(by=By.XPATH,value="//*[@id='channel-course-list']/div/div/div[2]/div[1]/div")
print(len(lis))
for i,li in enumerate(lis):
bottom=li.find_element_by_xpath("./div[1]")
bottom.click()
if i==8: #要爬取一个页面中的多少课程
break
# 跳转到新的想要跳转的页面
for i,handle in enumerate(driver.window_handles):
if i==0:
continue
# 切换到新的页面
driver.switch_to.window(handle)
print("title:"+driver.title)
name = driver.find_element(By.XPATH, "/html/body/div[4]/div[2]/div[1]/div/div[3]/div/div[1]/div[1]/span[1]").text
college = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/a/img").get_attribute("alt")
teacher = driver.find_element(By.XPATH, "//*[@id='j-teacher']/div/div/div[2]/div/div/div/div/img").get_attribute("alt")
team=driver.find_elements(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/div/div[2]/div/div/div")
teammateStr=""
for j,te in enumerate(team):
teammate=te.find_element_by_xpath(f"./div/img").get_attribute("alt")
teammateStr=teammateStr+' '+teammate
count=driver.find_element(By.XPATH,"//*[@id='course-enroll-info']/div/div[1]/div[4]/span[2]").text
count=re.findall(r"\d+",count)[0]
process=driver.find_element(By.XPATH,"//*[@id='course-enroll-info']/div/div[1]/div[2]/div/span[2]").text
brief=driver.find_element(By.XPATH,"//*[@id='j-rectxt2']").text
cur.execute('insert into course values(?,?,?,?,?,?,?,?)',(i,name,college,teacher,teammateStr,count,process,brief))
print(i,name,college,teacher,teammateStr,count,process,brief)
con.commit()
con.close()
流程是先进入mooc的国家精品课程的网页,先定位每个课程所在的位置。然后将精品课程的网页后点击课程,打开课程的新窗口,窗口打开完后就开始对打开的网页进行所需要的元素爬取。
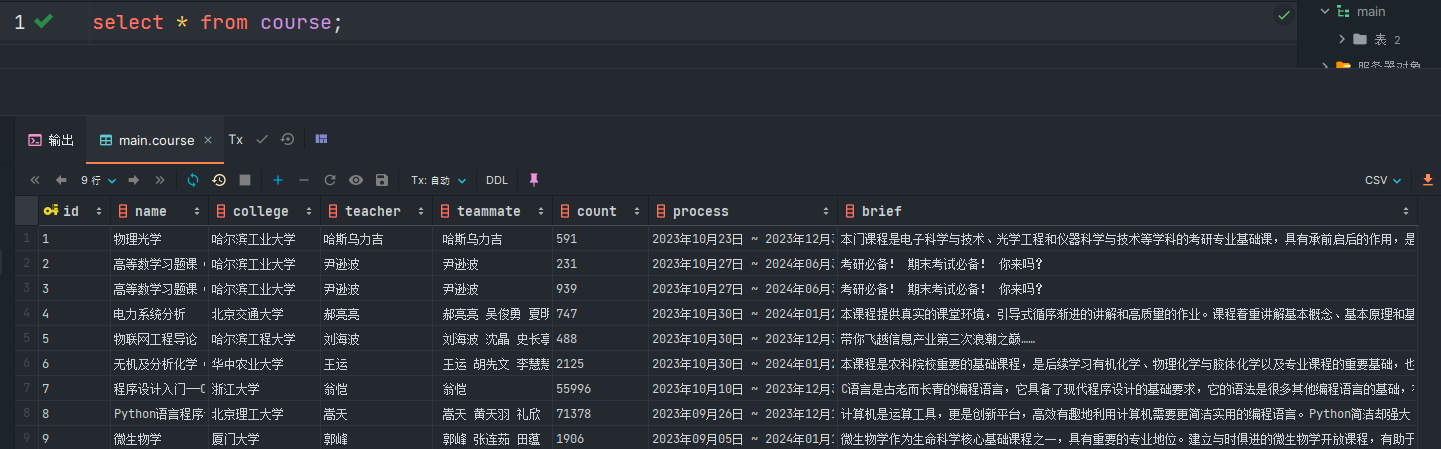
db文件内容如图所示:
心得体会
通过这次学习,学习到了selenium的工作流程,也理解了selenium的打开新窗口后要怎么继续进行读取,以及在Ajax网页的各种交互问题要如何解决与爬取。
作业③:
- 要求:
掌握大数据相关服务,熟悉 Xshell 的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。 - 环境搭建:
· 任务一:开通 MapReduce 服务 - 实时分析开发实战:
· 任务一:Python 脚本生成测试数据
· 任务二:配置 Kafka
· 任务三: 安装 Flume 客户端
· 任务四:配置 Flume 采集数据
实验代码
环境搭建:
- 任务一:开通 MapReduce 服务
![]()

实时分析开发实战:
-
任务一:Python 脚本生成测试数据
![]()
-
任务二:配置 Kafka
将zookeeper的ip地址换为自己的:
![]()
-
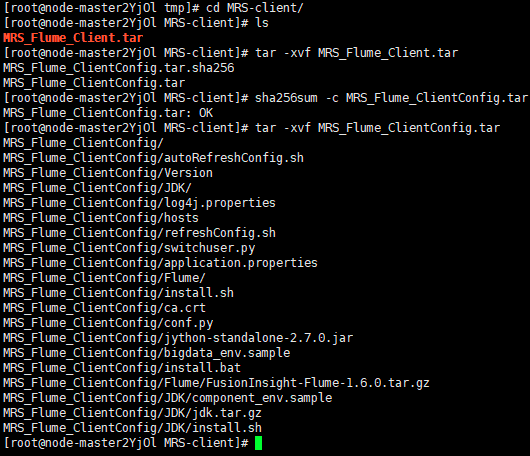
任务三: 安装 Flume 客户端
先在MRS_Manager中下载Flume,然后进行解压:
![]()
接着进行安装:
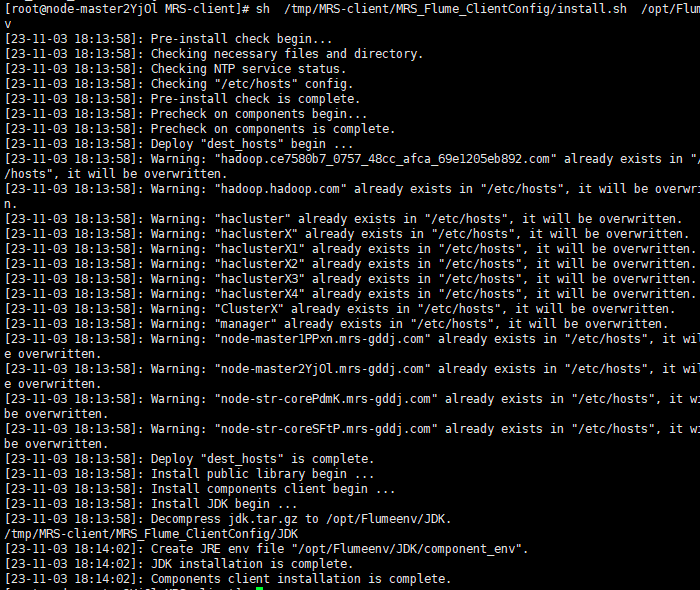
![]()
安装完成后显示successful:
![]()
-
任务四:配置 Flume 采集数据
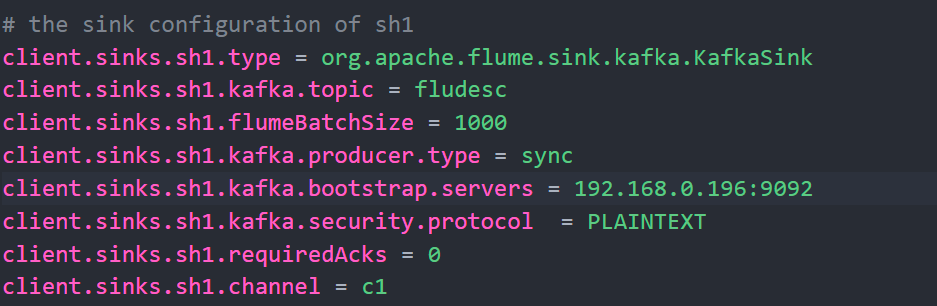
先将properties.properties写入,然后把kafla的ip换成自己的:
![]()
随后source保存,在admin用户下进行Flume的日志采集:
![]()
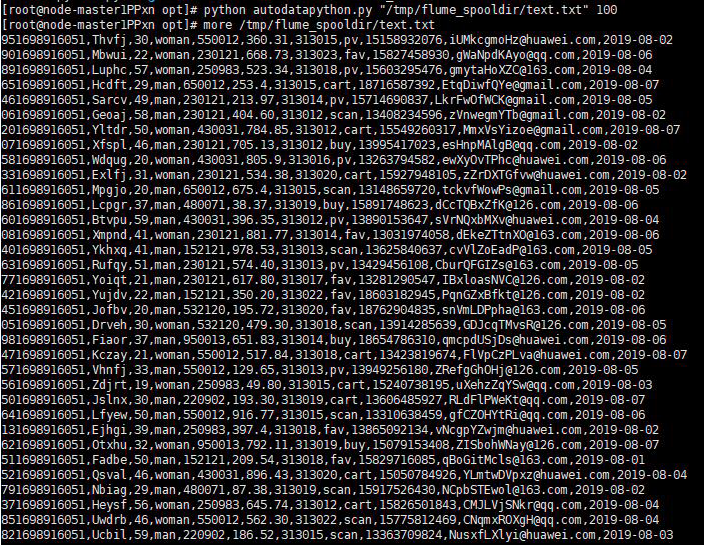
在root用户下运行python文件:
![]()
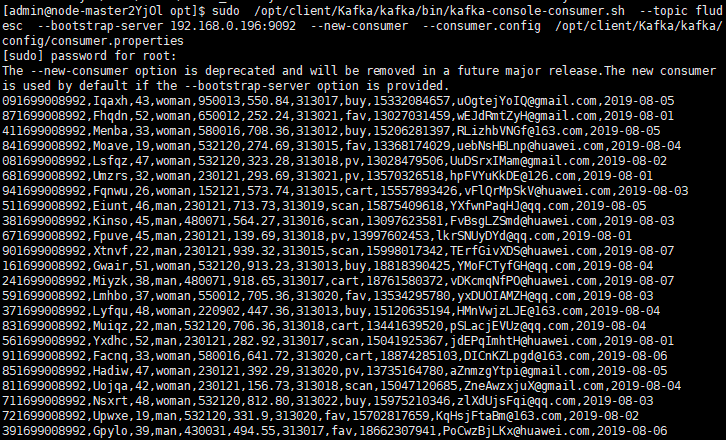
在admin用户下监控到数据流:
![]()




心得体会
学会了Flume的工作流,以及对Flume的框架理解更加深刻,还学会了华为云的使用,对服务器这个概念的理解的也更加深入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号