

第一次个人编程作业
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 90 | 120 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 120 | 200 |
| · Coding | · 具体编码 | 600 | 700 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 180 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| · 合计 | 1430 | 1720 |
二、思考
(2.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
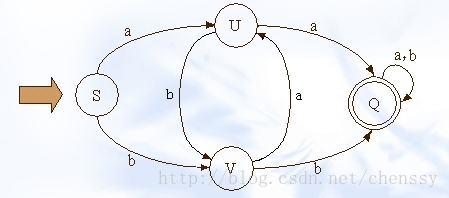
(2.1.1)敏感词检测一般可以使用list、AC自动机、DFA算法几种方法来实现,而我在实现过程中采用的是DFA算法。上图为DFA算法的原理。
(2.1.2)在设计类和函数,主要是分为2个类:Check和Filter。
在Filter类中实现根据main函数传入的敏感词词汇文件的绝对路径,实现读入敏感词词汇文件。之后初始化词库,将敏感词加入到HashMap中,构建敏感词Map,以便后续进行匹配。
private Set<String> Words(String pathnamess) throws Exception{}
//读取敏感词词汇文件,将文件内容放到word中
public Map lexicon(String pathnames){}
//初始化词库,将敏感词加入到HashMap中
private void AddToLexicon(Set<String> SensitiveWords){}
//添加敏感词
在Check类中实现传入敏感词词汇文件、待检测文件和答案文件的绝对路径,并读入待检测文件以及将结果输出到答案文件中。
public static void main(String[] args) throws IOException{}
//传入敏感词词汇文件、待检测文件和答案文件的绝对路径
public Set<String> getWord(String txt,int type){}
//获取文本中的敏感词,使用DFA算法
public int search(String txt,int start,int type){}
//检查文本中是否包含敏感词
public class output implements Comparable<output>{}
//添加Comparable,便于后续利用Collections.sort()对list进行排序
(2.1.3)在检测过程中使用DFA算法,设定最小匹配规则为1,最大匹配规则为2
//获取文本中的敏感词,最小匹配规则为1,最大匹配规则为2
public Set<String> getWord(String txt,int type){
Set<String> wordlist = new HashSet<String>();
for (int i=0;i<txt.length();i++){//判断是否包含敏感词
int len = search(txt,i,type);
if(len>0){//如果存在,加入wordlist
list.add(new output(line,i, txt.substring(i,i+len),txt.substring(i,i+len)));
wordlist.add(txt.substring(i,i+len));
i=i+len-1;
}
}
return wordlist;
}
(2.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
- 类的内存消耗
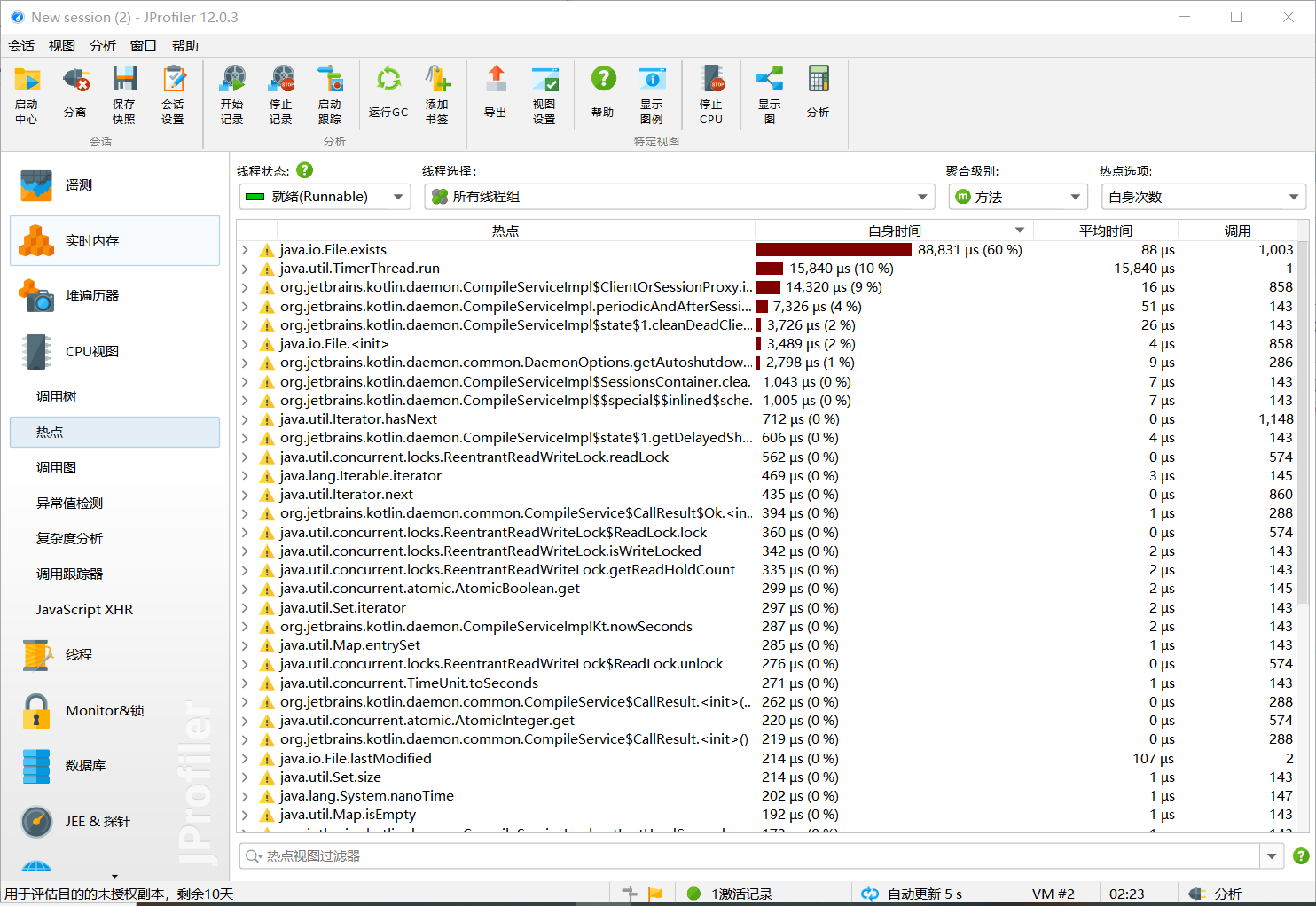
本次性能分析采用的是IntelliJ IDEA中的JProfiler性能分析工具。可见,其中开销最大的是java.io.File.exists。这是检测文件是否存在,在代码中是不可或缺的,因为该部分无法改进。其次是java.util.TimerThread.run,这是关于线程执行的文件,不知道是否能改进。对于我而言,现有的主要改进方向应该是在实现功能之后再谈,目前仅仅只实现了基础功能,因而功能代码的开销普遍较小。
- CPU Load
- 堆内存情况
- 概览

(2.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
时间没把握好,来不及实现555
(2.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
目前在代码中出现的异常处理主要都是跟文件相关的。
①传入路径为空时抛出异常
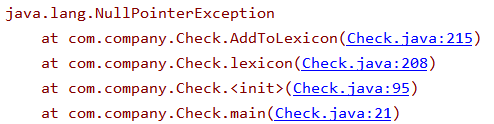
②对文件操作失败时抛出异常
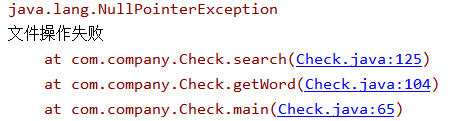
三、心得
在完成本次作业过程的心得体会
在本次作业过程中,感觉最难的是读懂题目。题目中有许多对于我而言,有许多之前从来没有接触过的内容,在了解、以及学习相关知识已经耗费了大量时间。
感觉这次在分析方面做得不是很好。一开始的构思对于我而言太难实现,以至于前期做了许多无用功。而边写代码、边修改很容易使得代码结构混乱,产生冗余代码、无用代码。下次在设计部分尽量做得更好,避免时间浪费。
这次是我第一次接触jar包的打包,尝试了多种打包方式之后,最后我选择的是通过IDEA打包并导出jar包,这种方法简单易操作,而且难出错。打包不会出错,但是在运行jar包的时候出错了。运行后查看答案文件,发现在IDEA中运行结果和在cmd中运行结果出现了很大偏差,缺失了中文部分。
java -jar Filter.jar words.txt org.txt ans.txt
//异常的运行方式(常规操作)
java -jar -Dfile.encoding=utf-8 Filter.jar words.txt org.txt ans.txt
//得到和编译器一致结果的方式
将命令行改为上述第二种即可得出结果。而问题就出在读入文本时,并没有指定UTF-8的编码格式,修改之后即可。
在后期中出现的最大问题其实是在程序中接受命令行传参。一开始没有理解好题目意思,以为是直接在代码中写入文件的绝对路径。后来通过命令行运行时,发现无论有没有传参得到的结果都是一样的,才知道需要在程序中接受命令行传参。本来以为很简单,结果修改完运行后,显示抛出空指针异常。通过报错知道是由于文件路径pathname一开始被定义为null,在传入参数后没有及时给到Filter类,导致在预编译时pathname仍为空,因而抛出异常。将其修改为接收到命令行参数后,立即传给Filter类,就解决啦。
