pandas read_sql与read_sql_table、read_sql_query 的区别
一:创建链接数据库引擎
from sqlalchemy import create_engine db_info = {'user':'user', 'password':'pwd', 'host':'localhost', 'database':'xx_db' # 这里我们事先指定了数据库,后续操作只需要表即可 } engine = create_engine('mysql+pymysql://%(user)s:%(password)s@%(host)s/%(database)s?charset=utf8' % db_info,encoding='utf-8') #这里直接使用pymysql连接,echo=True,会显示在加载数据库所执行的SQL语句。
二:读取数据库数据,存储为DataFrame格式
部分来自于博客:http://blog.csdn.net/u011301133/article/details/52488690
1:读取自定义数据(通过SQL语句)
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None,chunksize=None)
例如:data = pd.read_sql_query('select * from t_line ',con = engine),会返回一个数据库t_line表的DataFrame格式。如有有时间列可以parse_dates = [time_column]用于解析时间,并把此列作为索引index_col = [time_column]
read_sql_query()中可以接受SQL语句,包括增删改查。但是DELETE语句不会返回值(但是会在数据库中执行),UPDATE,SELECT,等会返回结果.
例如:data = pd.read_sql_query('delete from test_cjk where f_intime = 1309',con = engine),这条语句会执行,删除 test_cjk表中f_intime=1309的值,但不会返回data。
其他例子:
'''插入操作''' pd.read_sql_query("insert into cjk_test h values %(data)s",params={'data':v_split[11]},con=engine)
'''更新操作''' pd.read_sql_query("update cjk_test set a='粤11111' WHERE a='粤B30738'",con =engine)
'''删除操作'''pd.read_sql_query("delete from cjk_test where c='1'",con=engine)
删除插入更新操作没有返回值,程序会抛出SourceCodeCloseError,并终止程序。如果想继续运行,可以try捕捉此异常。
2:读取整张表于DataFrame格式(通过表名)
pd.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
例如:data = pd.read_sql_table(table_name = 't_line',con = engine,parse_dates = 'time',index_col = 'time',columns = ['a','b','c'])
3:读数据库(通过SQL语句或者表名)
通过sql语句的见我另一篇文章:http://www.cnblogs.com/cymwill/articles/7576600.html
pd.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
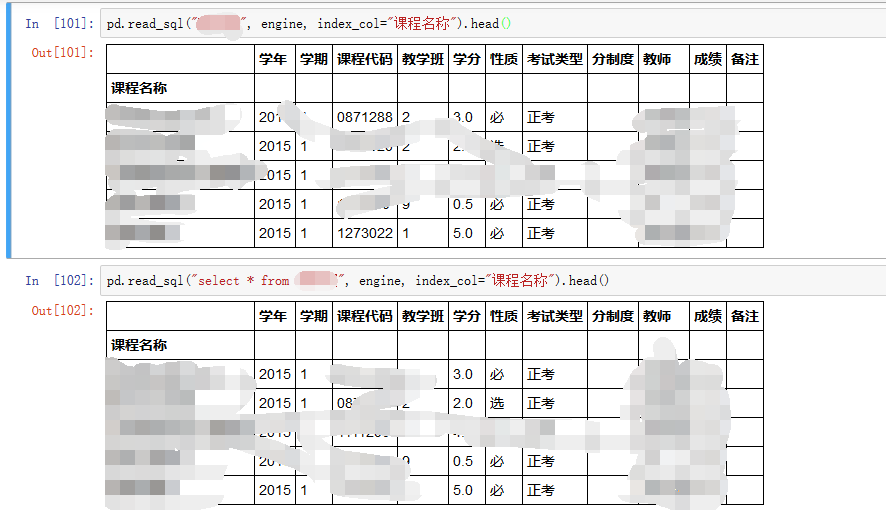
下面两个的作用又是相同的:
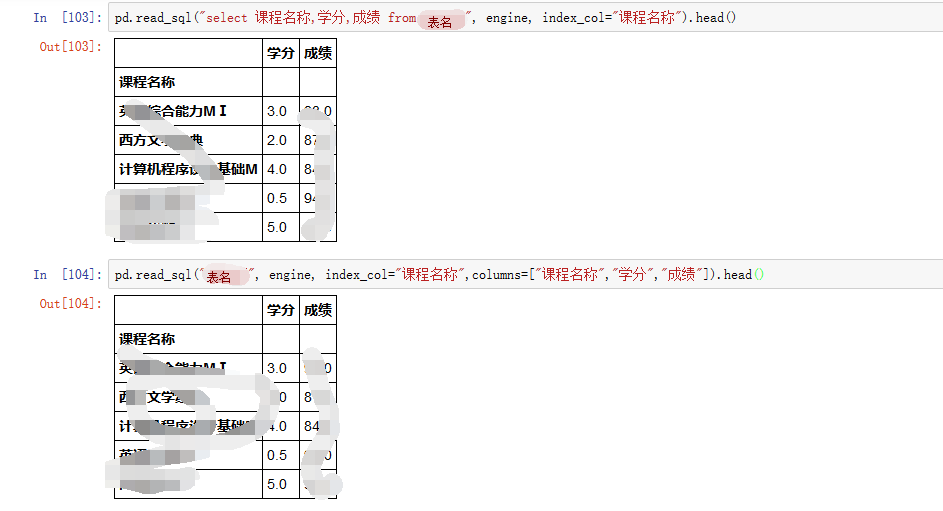
这个是官网的源代码里面的片段:
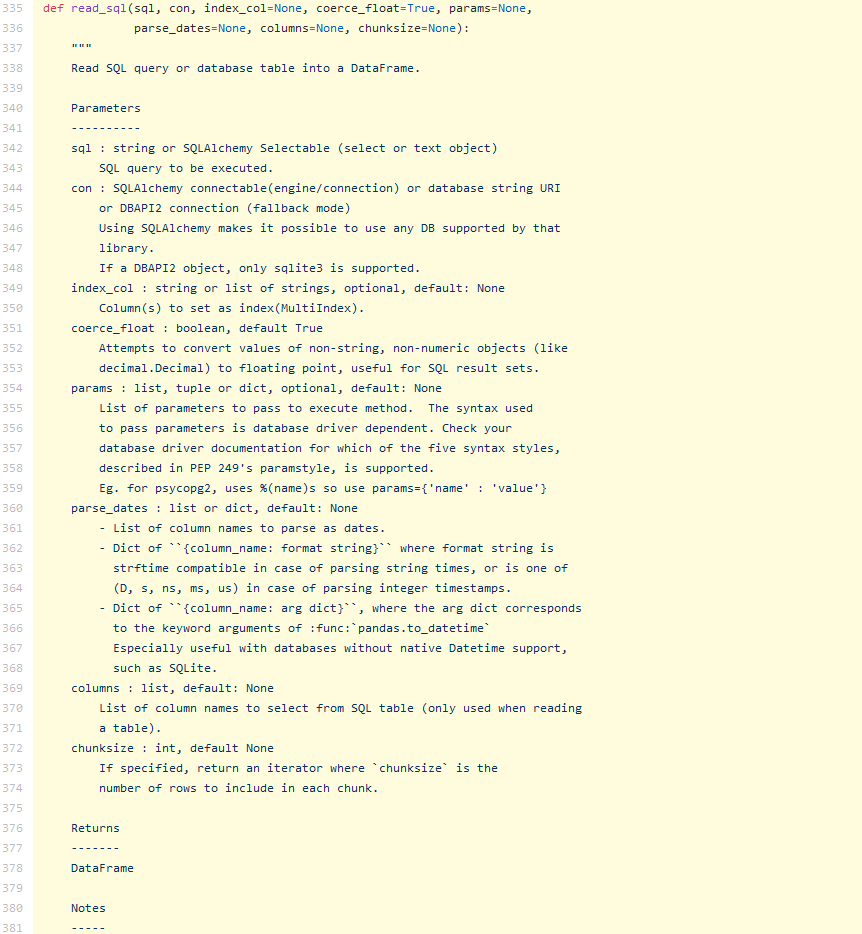
我们再将query与table相反的试一下:
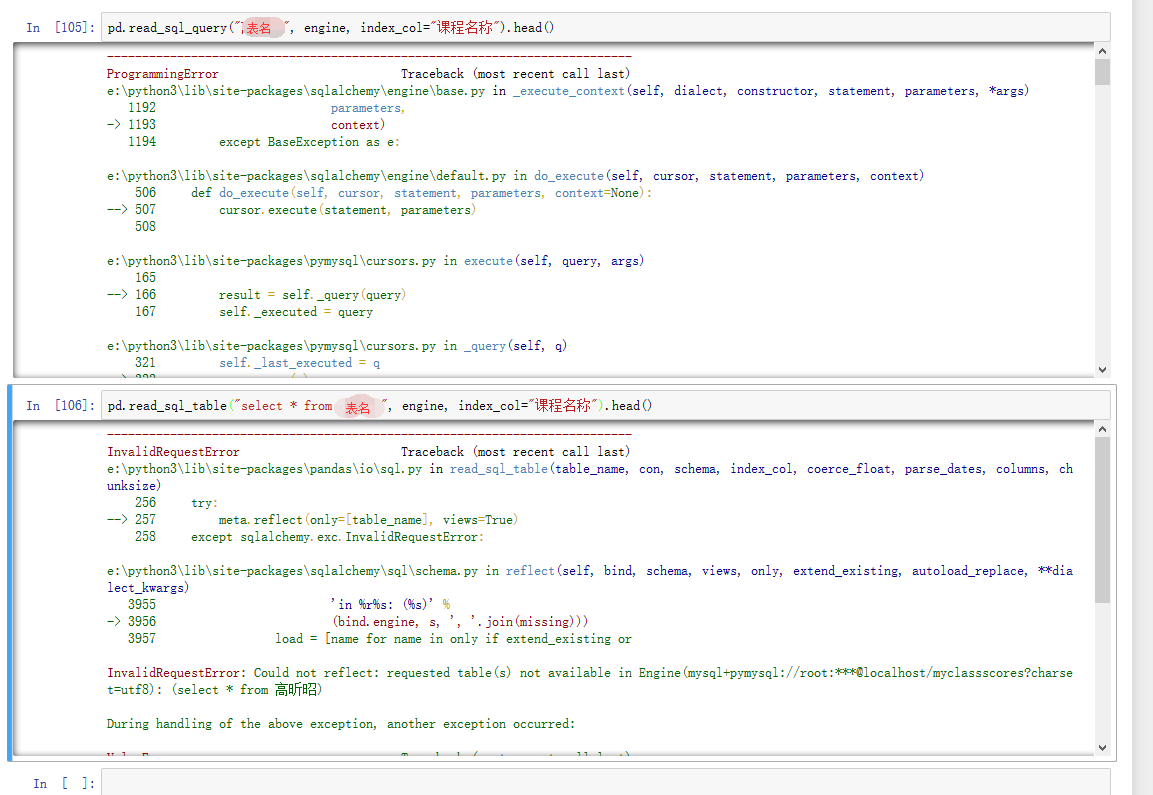
报错,故两者不能反过来。
从上面可以看到,其实read_sql是综合了read_sql_table和read_sql_query的,所以一般用read_sql就好了,省得再去区别那些东西。
三:数据写入于数据库
见我另一篇文章:http://www.cnblogs.com/cymwill/p/8288667.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号