

阿里DRUID 配置说明及分析
今天我们说说数据源和数据库连接池,熟悉java开发的同仁应该都了解C3PO,在这里不做过多的赘述了,今天我们说的是阿里DRUID,druid是后起之秀,因为它的优秀很快占领了使用市场,下边我们一起来看看druid数据源的配置以及druid监控的配置和监控的实现逻辑。
1、druid数据源配置
下面是druid的数据源配置项,这些配置项都是com.alibaba.druid.pool.DruidDataSource类和其基类com.alibaba.druid.pool.DruidAbstractDataSource的public final属性,这些配置型和C3P0的数据源配置项基本一样,有个别的是明白发生了变化但是参数所表示的意思不变,还有一些参数是druid自己扩展的,其中filters属性就是杰出代表,次属性是DruidAbstractDataSource类的,是一个List<Filter>的集合,此属性提供了三个可选值:监控统计用的stat、日志用的log4j、 防御sql注入的wall,这三个值可以单独使用也可以两两组合或者一起使用,组合使用的时候不同值之间用逗号隔开。有人可能会有疑问了,不是一个List集合吗,为什么这里却是用逗号分隔的,那是因为druid在赋值的时候有特殊处理,至于是如何处理的在下边我们会说到。
| 配置 | 缺省值 | 说明 |
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候 可以通过名字来区分开来。如果没有配置,将会生成一个名字, 格式是:"DataSource-" + System.identityHashCode(this) |
|
| jdbcUrl | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto |
|
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中, 可以使用ConfigFilter。详细看这里: https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter |
|
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType, 然后选择相应的driverClassName |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法, 或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后, 缺省启用公平锁,并发效率会有所下降, 如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 |
|
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。 PSCache对支持游标的数据库性能提升巨大,比如说oracle。 在mysql5.5以下的版本中没有PSCache功能,建议关闭掉。 5.5及以上版本有PSCache,建议开启。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时, poolPreparedStatements自动触发修改为true。 在Druid中,不会存在Oracle下PSCache占用内存过多的问题, 可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。 如果validationQuery为null,testOnBorrow、testOnReturn、 testWhileIdle都不会其作用。 |
|
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效, 做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效, 做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。 申请连接的时候检测,如果空闲时间大于 timeBetweenEvictionRunsMillis, 执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1) Destroy线程会检测连接的间隔时间 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
|
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| minEvictableIdleTimeMillis | Destory线程中如果检测到当前连接的最后活跃时间和当前时间的差值大于 minEvictableIdleTimeMillis,则关闭当前连接。 |
|
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件, 常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall |
|
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>, 如果同时配置了filters和proxyFilters, 是组合关系,并非替换关系 |
|
| removeAbandoned | 对于建立时间超过removeAbandonedTimeout的连接强制关闭 | |
| removeAbandonedTimeout | 指定连接建立多长时间就需要被强制关闭 | |
| logAbandoned | 指定发生removeabandoned的时候,是否记录当前线程的堆栈信息到日志中 |
2、druid监控的配置与监控访问
要使用druid监控需要做好两个配置:
1)、在配置数据源时需要配置filters并且赋值你需要使用的监控项(stat、log4j、wall);
2)、需要在项目的web.xml中配置druid的自定义servlet(com.alibaba.druid.support.http.StatViewServlet),配置样例如下代码所示:
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
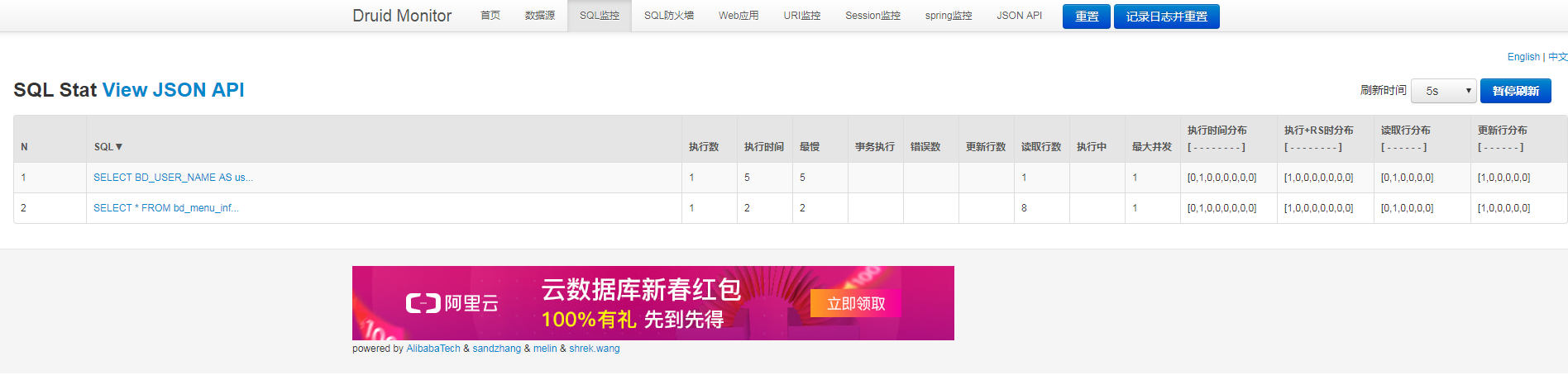
3)、监控系统的访问:http://IP:PORT/projectName/druid/(http://localhost:8088/cd_management/druid/sql.html),监控效果如下图所示:

3、filters属性的赋值逻辑
上面有提到filters的配置项有三个,可以随机组合也可以一起使用,也有提到filters是一个List集合,那我们来看看druid是如何赋值的,如下源码所示,赋值时调用的setFilters(String filters)方法,最终是通过逗号分隔为数组然后遍历调用FilterManager.loadFilter(this.filters, item.trim()),然后用反射机制生成相应的对象并添加到Filter集合。
public void setFilters(String filters) throws SQLException { if (filters != null && filters.startsWith("!")) { filters = filters.substring(1); this.clearFilters(); } this.addFilters(filters); } public void addFilters(String filters) throws SQLException { if (filters == null || filters.length() == 0) { return; } String[] filterArray = filters.split("\\,"); for (String item : filterArray) { FilterManager.loadFilter(this.filters, item.trim()); } }
public static void loadFilter(List<Filter> filters, String filterName) throws SQLException { if (filterName.length() == 0) { return; } String filterClassNames = getFilter(filterName); if (filterClassNames != null) { for (String filterClassName : filterClassNames.split(",")) { if (existsFilter(filters, filterClassName)) { continue; } Class<?> filterClass = Utils.loadClass(filterClassName); if (filterClass == null) { LOG.error("load filter error, filter not found : " + filterClassName); continue; } Filter filter; try { filter = (Filter) filterClass.newInstance(); } catch (ClassCastException e) { LOG.error("load filter error.", e); continue; } catch (InstantiationException e) { throw new SQLException("load managed jdbc driver event listener error. " + filterName, e); } catch (IllegalAccessException e) { throw new SQLException("load managed jdbc driver event listener error. " + filterName, e); } filters.add(filter); } return; } if (existsFilter(filters, filterName)) { return; } Class<?> filterClass = Utils.loadClass(filterName); if (filterClass == null) { LOG.error("load filter error, filter not found : " + filterName); return; } try { Filter filter = (Filter) filterClass.newInstance(); filters.add(filter); } catch (Exception e) { throw new SQLException("load managed jdbc driver event listener error. " + filterName, e); } }
4、druid监控实现逻辑
要说明druid监控逻辑从如下三个方面切入分析:
1)、监控的数据什么时候生成
在这里我们拿Spring和druid整合案例来分析说明druid监控数据的生成,上面我们有提到要使用druid的监控空能需要配置filters,并且filters可以配置多个,这里druid关于这些filter的处理其实借鉴了过滤器链的原理,druid关于监控数据的收集处理逻辑是这样的,我们从Spring的JdbcTemplate类开始看,如下源码一,是一个查询的处理,rs = ps.executeQuery()是PreparedStatement开始执行sql从数据库查询数据的开始,这里我们给ps对象赋予的是DruidPooledPreparedStatement类对象,所以进入DruidPooledPreparedStatement类我们来看它的具体实现。
源码二是DruidPooledPreparedStatement类对executeQuery方法的实现,这个方法里面最关键的是ResultSet rs = stmt.executeQuery()这句,stmt是PreparedStatementProxyImpl类的类对象。
源码三是PreparedStatementProxyImpl类对executeQuery方法的实现,这个方法实现中调用了父类的createChain()方法,源码四为父类方法实现,这个方法的返回值是一个过滤器链类FilterChainImpl类对象,FilterChainImpl类的
preparedStatement_executeQuery(PreparedStatementProxy statement)方法实现如源码五。
public <T> T query( PreparedStatementCreator psc, final PreparedStatementSetter pss, final ResultSetExtractor<T> rse) throws DataAccessException { Assert.notNull(rse, "ResultSetExtractor must not be null"); logger.debug("Executing prepared SQL query"); return execute(psc, new PreparedStatementCallback<T>() { @Override public T doInPreparedStatement(PreparedStatement ps) throws SQLException { ResultSet rs = null; try { if (pss != null) { pss.setValues(ps); } rs = ps.executeQuery(); ResultSet rsToUse = rs; if (nativeJdbcExtractor != null) { rsToUse = nativeJdbcExtractor.getNativeResultSet(rs); } return rse.extractData(rsToUse); } finally { JdbcUtils.closeResultSet(rs); if (pss instanceof ParameterDisposer) { ((ParameterDisposer) pss).cleanupParameters(); } } } }); }
public ResultSet executeQuery() throws SQLException { checkOpen(); incrementExecuteCount(); transactionRecord(sql); oracleSetRowPrefetch(); conn.beforeExecute(); try { ResultSet rs = stmt.executeQuery(); if (rs == null) { return null; } DruidPooledResultSet poolableResultSet = new DruidPooledResultSet(this, rs); addResultSetTrace(poolableResultSet); return poolableResultSet; } catch (Throwable t) { errorCheck(t); throw checkException(t); } finally { conn.afterExecute(); } }
public ResultSet executeQuery() throws SQLException { firstResultSet = true; updateCount = null; lastExecuteSql = sql; lastExecuteType = StatementExecuteType.ExecuteQuery; lastExecuteStartNano = -1L; lastExecuteTimeNano = -1L; return createChain().preparedStatement_executeQuery(this); }
public FilterChainImpl createChain() { FilterChainImpl chain = this.filterChain; if (chain == null) { chain = new FilterChainImpl(this.getConnectionProxy().getDirectDataSource()); } else { this.filterChain = null; } return chain; }
@Override public ResultSetProxy preparedStatement_executeQuery(PreparedStatementProxy statement) throws SQLException { if (this.pos < filterSize) { return nextFilter().preparedStatement_executeQuery(this, statement); } ResultSet resultSet = statement.getRawObject().executeQuery(); if (resultSet == null) { return null; } return new ResultSetProxyImpl(statement, resultSet, dataSource.createResultSetId(), statement.getLastExecuteSql()); }
看了如上源码我们会发现FilterChainImpl类的preparedStatement_executeQuery方法执行的时候会先执行过滤器类的此方法,所以我们看看过滤器类做了什么,这里我们拿SQL监控的过滤器类(FilterEventAdapter)来分析,如下源码是此类的方法实现。我看可以看到此方法先调用了statementExecuteQueryBefore(statement, statement.getSql())方法,然后调用了下一个过滤器类的查询方法,在方法正常执行以后又调用了statementExecuteQueryAfter(statement, statement.getSql(), resultSet)方法,在方法执行异常的时候调用了statement_executeErrorAfter(statement, statement.getSql(), error),这些方法的作用就是保存SQL执行中的监控数据。说到这里从流程上就说明了druid监控数据的来源。
public ResultSetProxy preparedStatement_executeQuery(FilterChain chain, PreparedStatementProxy statement) throws SQLException { try { statementExecuteQueryBefore(statement, statement.getSql()); ResultSetProxy resultSet = chain.preparedStatement_executeQuery(statement); if (resultSet != null) { statementExecuteQueryAfter(statement, statement.getSql(), resultSet); resultSetOpenAfter(resultSet); } return resultSet; } catch (SQLException error) { statement_executeErrorAfter(statement, statement.getSql(), error); throw error; } catch (RuntimeException error) { statement_executeErrorAfter(statement, statement.getSql(), error); throw error; } catch (Error error) { statement_executeErrorAfter(statement, statement.getSql(), error); throw error; } }
2)、监控的数据保存到哪里
这里我们简单说明,数据是保存到DruidDataSource类的dataSourceStat对象中。
3)、监控的请求如何处理的
要使用druid的监控功能需要配置com.alibaba.druid.support.http.StatViewServlet,这是一个继承自HttpServlet的servlet,用来处理访问druid监控的请求,具体处理流程如下:
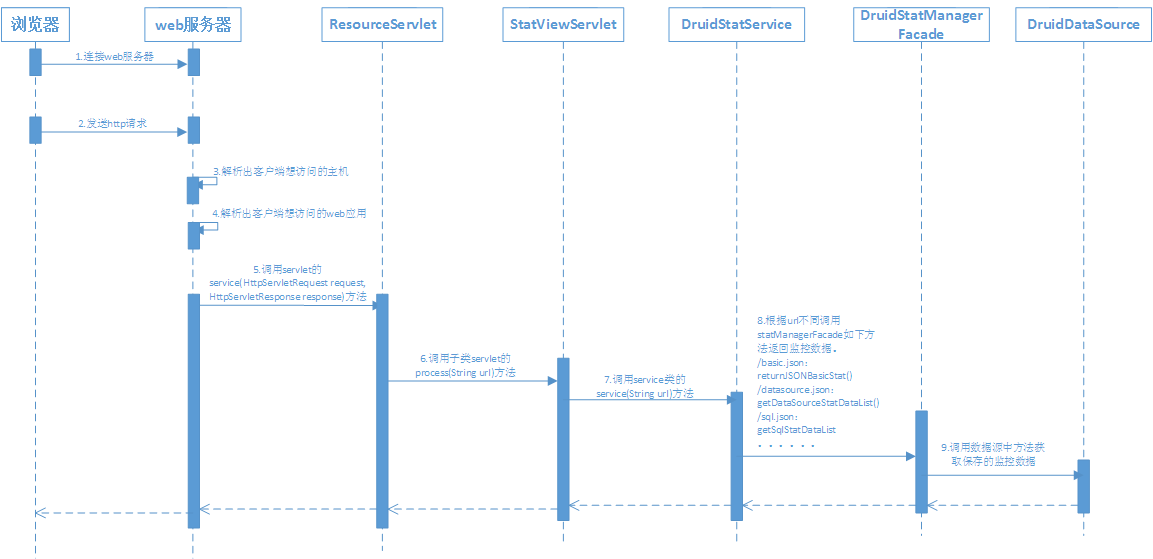
5、如何去除监控页面的广告
1) 使用过druid的同仁应该都了解,druid的监控页面加载以后,footer页是有阿里的广告的如下图所示,如果是一个商业项目这个是很不雅也是不允许的,那么我们来看看如何去除广告。
2)要去除这个广告需要修改druid.jar的源码文件,具体方法是,用winRAR打开jar包,在druid-1.1.6.jar\support\http\resources\js\common.js路径下找到文件,修改common.js中如下图所示的代码,删除buildFooter函数中的代码即可:
buildFooter : function() { var html ='<footer class="footer">'+ ' <div class="container">'+ '<a href="https://render.alipay.com/p/s/taobaonpm_click/druid_banner_click" target="new"><img src="https://render.alipay.com/p/s/taobaonpm_click/druid_banner"></a><br/>' + ' powered by <a href="https://github.com/alibaba/" target="_blank">AlibabaTech</a> & <a href="http://www.sandzhang.com/" target="_blank">sandzhang</a> & <a href="http://melin.iteye.com/" target="_blank">melin</a> & <a href="https://github.com/shrekwang" target="_blank">shrek.wang</a>'+ ' </div>'+ ' </footer>'; $(document.body).append(html); },
