

8. SparkSQL综合作业
实验123因加入班级博客迟了点没及时提交,实验7暂缓在家忘记提交了,不好意思
1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
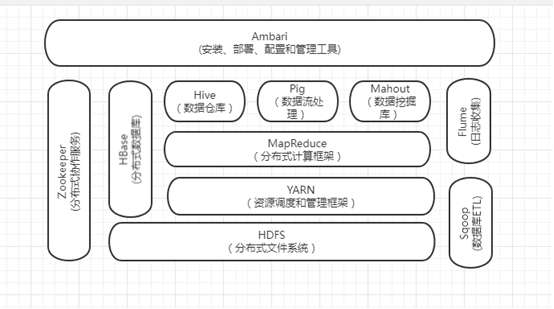
生态系统,顾名思义就是很多组件组成的一个生态链,经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包括了多个子项目,除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括要ZoopKer、HBase、Hive、Pig、Mahout、Sqoop、Flume、Ambari等功能组件。这些组件几乎覆盖了目前业界对数据处理的所有场景。
HDFS
是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
mapreduce
mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
hive
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
hbase
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。
zookeeper
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
sqoop
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。
数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
pig
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。
通常用于离线分析。
mahout(数据挖掘算法库)
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
flume
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。
2.对比Hadoop与Spark的优缺点。
(1)Spark基于RDD,数据并不存放在RDD中,只是通过RDD进行转换,通过装饰者设计模式,数据之间形成血缘关系和类型转换;
(2)Spark用scala语言编写,相比java语言编写的Hadoop程序更加简洁;
(3)相比Hadoop中对于数据计算只提供了Map和Reduce两个操作,Spark提供了丰富的算子,可以通过RDD转换算子和RDD行动算子,实现很多复杂算法操作,这些在复杂的算法在Hadoop中需要自己编写,而在Spark中直接通过scala语言封装好了,直接用就ok;
(4)Hadoop中对于数据的计算,一个Job只有一个Map和Reduce阶段,对于复杂的计算,需要使用多次MR,这样涉及到落盘和磁盘IO,效率不高;而在Spark中,一个Job可以包含多个RDD的转换算子,在调度时可以生成多个Stage,实现更复杂的功能;
(5)Hadoop中中间结果存放在HDFS中,每次MR都需要刷写-调用,而Spark中间结果存放优先存放在内存中,内存不够再存放在磁盘中,不放入HDFS,避免了大量的IO和刷写读取操作;
(6)Hadoop适合处理静态数据,对于迭代式流式数据的处理能力差;Spark通过在内存中缓存处理的数据,提高了处理流式数据和迭代式数据的性能;
(7)Spark对标于Hadoop中的计算模块MR,但是速度和效率比MR要快得多;
(8)Spark没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作,它只是一个计算分析框架,专门用来对分布式存储的数据进行计算处理,它本身并不能存储数据;
(9)Spark可以使用Hadoop的HDFS或者其他云数据平台进行数据存储,但是一般使用HDFS;
(10)Spark可以使用基于HDFS的HBase数据库,也可以使用HDFS的数据文件,还可以通过jdbc连接使用Mysql数据库数据;Spark可以对数据库数据进行修改删除,而HDFS只能对数据进行追加和全表删除;
3.如何实现Hadoop与Spark的统一部署?
一方面,由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm可以实现毫秒级响应的流计算,但是,Spark则无法做到毫秒级响应。另一方面,企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。
2.安装Spark与Python练习
1检查基础环境hadoop,jdk

2配置
3试运行python代码
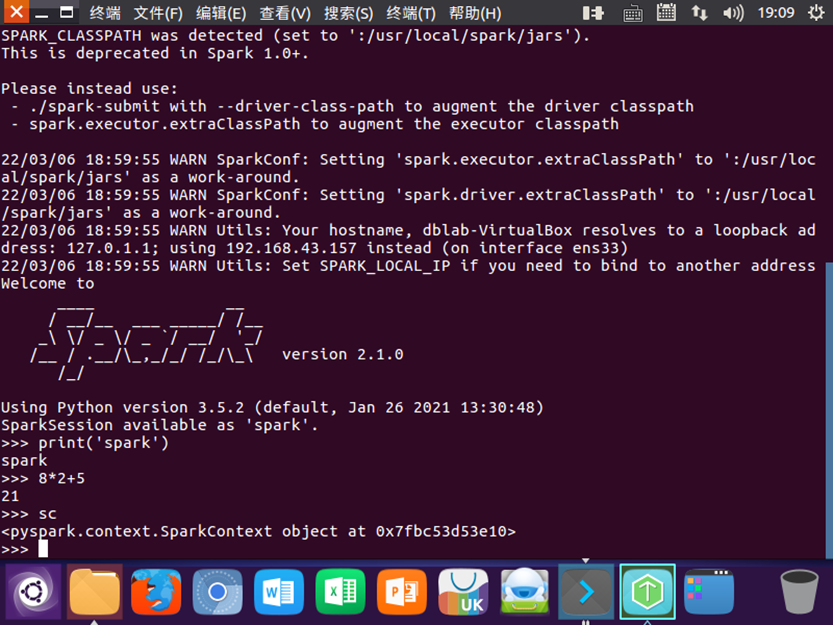
二python编程练习:
准备文本文件:world.txt
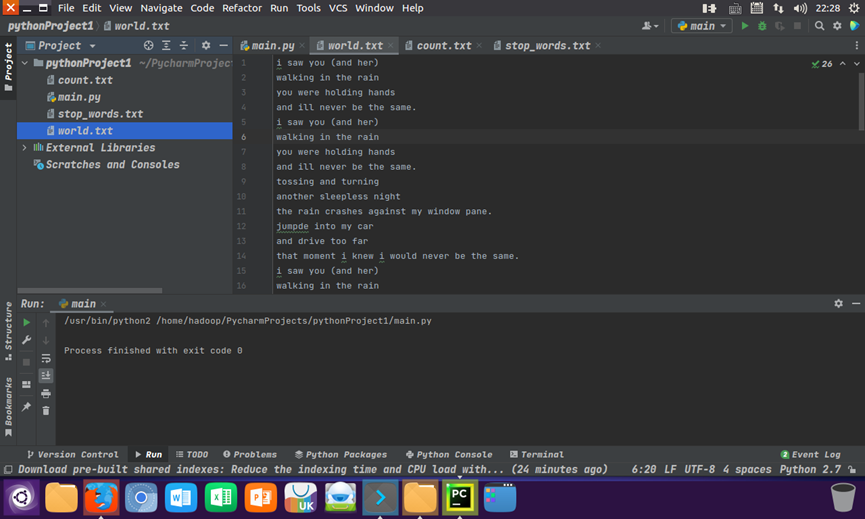
读文件,预处理:大小写,标点符号,停用词,分词 main.py
|
1
|
with open("Under the Red Dragon.txt", "r") as f: text=f.read() text = text.lower() for ch in '!@#$%^&*(_)-+=\\[]}{|;:\'\"`~,<.>?/': text=text.replace(ch," ") words = text.split() # 以空格分割文本 stop_words = [] with open('stop_words.txt','r') as f: # 读取停用词文件 for line in f: stop_words.append(line.strip('\n')) afterwords=[] for i in range(len(words)): z=1 for j in range(len(stop_words)): if words[i]==stop_words[j]: continue else: if z==len(stop_words): afterwords.append(words[i]) break z=z+1 continue |

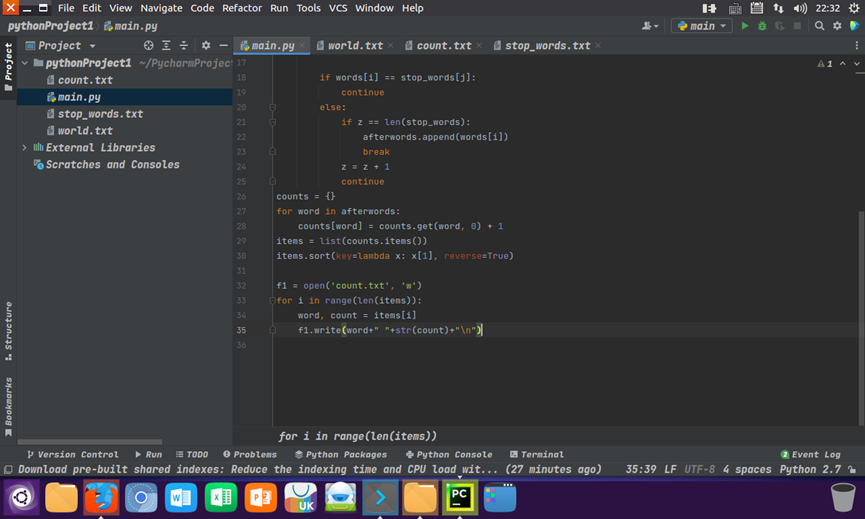
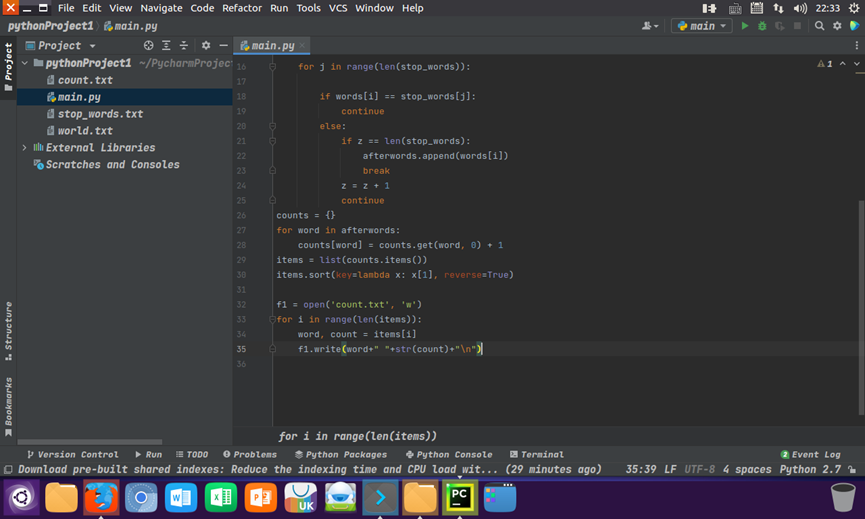
统计每个单词出现的次数,按词频大小排序,结果写文件 main.py
counts = {} for word in afterwords: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) f1 = open('count.txt', 'w') for i in range(len(items)): word, count = items[i] f1.write(word+" "+str(count)+"\n")
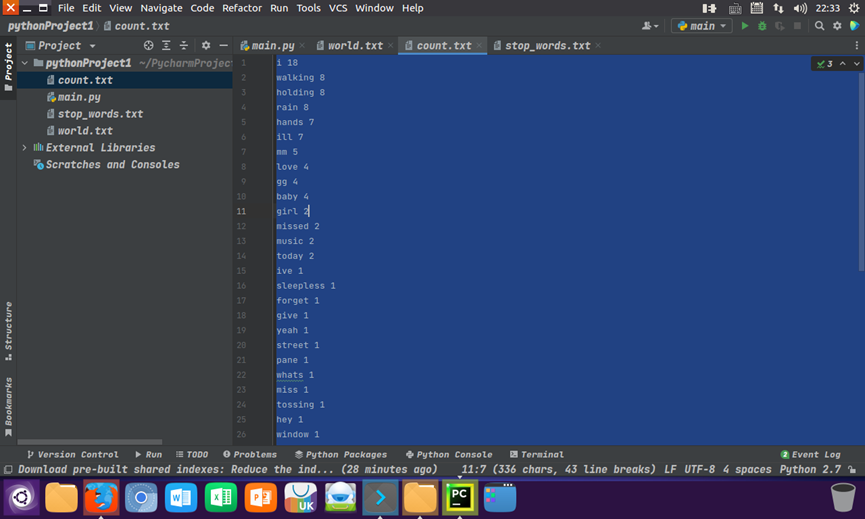
输出结果
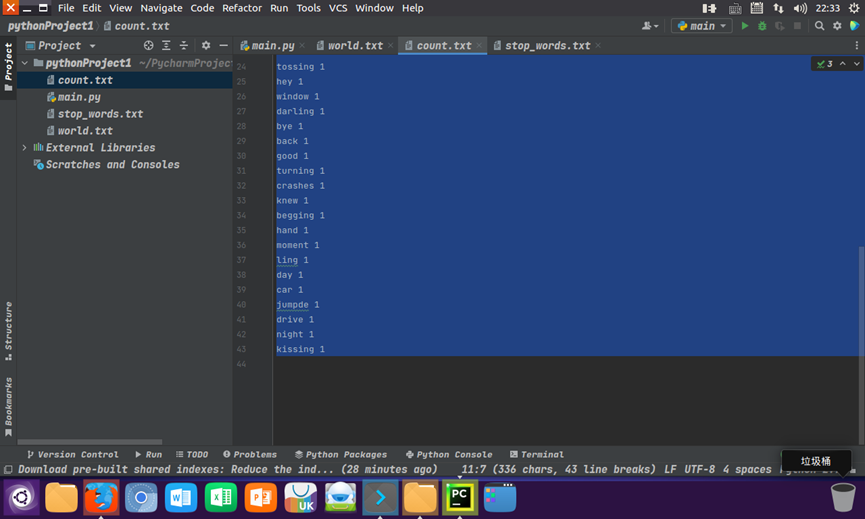
三、使用PyCharm搭建编程环境:Ubuntu 16.04 + PyCharm + spark
3.Spark设计与运行原理,基本操作
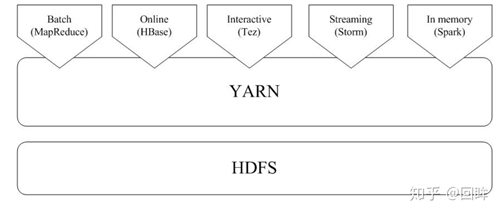
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。

2、请详细阐述Spark的几个主要概念及相互关系
Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Claster Manager
1.Task(任务):RDD中的一个分区对应一个task,task是单个分区上最小的处理流程单元
2.TaskSet(任务集):一组关联的,但相互之间没有Shuffle依赖关系的Task集合。
3.Stage(调度阶段):一个taskSet对应的调度阶段,每个job会根据RDD的宽依赖关系被切分很多Stage,每个stage都包含 一个TaskSet。
4.job(作业):由Action算子触发生成的由一个或者多个stage组成的计算作业。
5.application:用户编写的spark应用程序,由一个或者多个job组成,提交到spark之后,spark为application分派资源,将程序转换并执行。
6.DAGScheduler:根据job构建基于stage的DAG,并提交stage给TaskScheduler。
7.TaskScheduler:将Taskset提交给Worker Node集群运行并返回结果。
关系:
1,Application
一个SparkContext就是一个application,通过spark-submit脚本提交给集群。
2,DAG
RDD依赖组成的有向无环图,来表明一个Application中RDD的依赖关系。
3,Job
(1)没有检查点的正常情况下一个行动算子触发一个Job。
(2)如果行动算子的依赖链中有检查点(checkpoint),则至少有一个额外的Job来专门执行检查点功能。如果有多个checkpoint,需要根据下面参数来确定checkpoint Job的数量:spark.checkpoint.checkpointAllMarkedAncestors
如果值为true,则所有检查点都会执行,父RDD的checkpoint Job先执行。
否则只执行最靠后的RDD的checkpoint Job任务。
(3)主线程是串行阻塞式提交Job的,一个行动操作Job执行完毕后执行其依赖链中的checkpoint Job;然后执行下一个行动操作Job及其checkpoint Job。
4 Stage
(1)stage分为两类:ShuffleMapStage和ResultStage
(2)Spark根据ShuffleDependency来划分Stage,一个ShuffleDependency依赖关系的父RDD为前一个Stage的结束,子RDD(都是ShuffledRDD)下一个stage的开始。一个ShuffleDependency一个ShuffleMapStage,另外还会有一个ResultStage。
(3)一个Job stage的总数=零个或者多个ShuffleMapStage+一个ResultStage。
(4)stage之间有依赖关系,按照依赖关系的顺序串行执行。
5 Task
(1)Task分为两类:ShfflueMapTask和ResultTask。
(2)每个ShuffleMapStage都有一个或者多个ShfflueMapTask,数量为ShuffleMapStage中最后一个RDD的分区数量;
(3)每个ResultStage都有一个或者多个ResultStage,数量为ShuffleMapStage中最后一个RDD的分区数量。
(4)同一个stage的task之间并行执行,不同stage的task遵循stage的顺序。
(5)只有Task才会发送到spark Excutor中执行,涉及到数据计算。其它的概念都只存在于ApplicationMaster中。
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
my.txt

运行spark程序






RDD转换关系图

1.分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
SparkSQL出现的原因:为了替代Mapreduce,解决Mapreduce计算短板。
SparkSQL的起源与发展:Hadoop刚开始出来的时候,使用的是hadoop自带的分布式计算系统MapReduce,但是MapReduce的使用难度较大,所以就开发了Hive,Hive编程用的是类SQL的HQL的语句,这样编程的难度就大大的降低了,Hive的运行原理就是将HQL语句经过语法解析、逻辑计划、物理计划转化成MapReduce程序执行。当Spark出来以后,Spark团队也开发了一个Shark,就是在Spark集群上安装一个Hive的集群,执行引擎是Hive转化成Mapreduce的执行引擎,这样的框架就是Hive on Spark,但是这样是有局限性的,因为Shark的版本升级是依赖Hive的版本的,所以2014年7月1日spark团队就将Shark转给Hive进行管理,Spark团队开发了一个SparkSQL,这个计算框架就是将Hive on Spark的将SQL语句转化为Spark RDD的执行引擎换成自己团队从新开发的执行引擎。
(1)1.0版本以前:Hive on Spark Shark
(2)1.0.x版本:Spark SQL Alpha版本(测试版本,不建议商业项目使用),这个版本让Spark升为了Apache的顶级项目。
(3)1.3.x版本:SparkSQL DataFrame、Release(成熟,可以使用)
(4)spark 1.5.x版本:钨丝计划(底层代码的优化)
(5) spark 1.6.x版本:DataSet(alpha版本)
(6)Spark 2.x.x版本:DataSet(正式的)、Structrued Streaming
2. 简述RDD 和DataFrame的联系与区别。
联系:
(1)都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
(2)都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action才会运算
(3)都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
(4)三者都有partition的概念
(5)三者有许多共同的函数,如filter,排序等
区别:
(1)RDD是分布式的java对象的集合,但是对象内部结构对于RDD而言却是不可知的。
(2)DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息,相当于关系数据库中的一张表
3.1 PySpark-DataFrame创建:
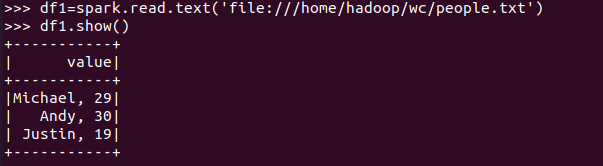
spark.read.text(url)
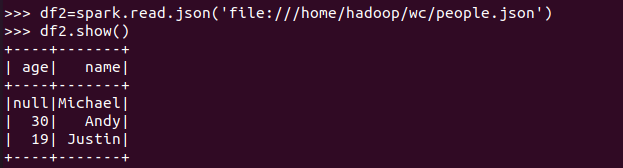
spark.read.json(url)
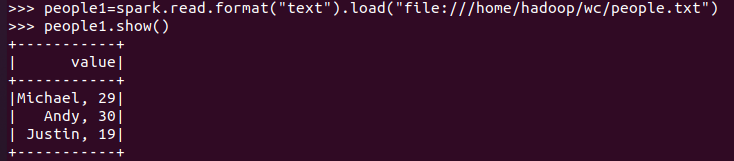
spark.read.format("text").load("people.txt")
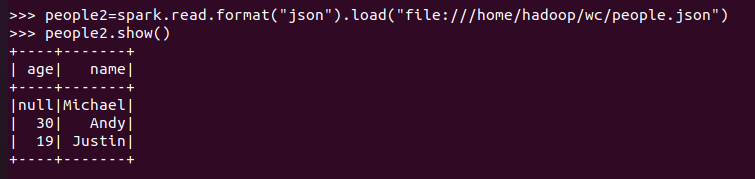
spark.read.format("json").load("people.json")
描述从不同文件类型生成DataFrame的区别。
txt文件:创建的DataFrame数据没有结构
json文件:创建的DataFrame数据有结构
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。
1.RDD在创建之后,你知道有这个类,但是你不知道他的内部结构的,DataFrame是以列式存储,它有schema是可以知道的。
2.DataRrame比RDD的执行效率要高一点,因为在大数据的处理中,RDD即使用mappartition或者foreachRDD都要消耗不少的core,但是DataFrame他可以进行sql操作,先过滤掉一部分数据,在RDD中是不好实现的。
3.2 DataFrame的保存
df.write.text(dir)

df.write.json(dri)

df.write.format("text").save(dir)

df.write.format("json").save(dir)

4.选择题:
1单选(2分)关于Shark,下面描述正确的是:C
A.Shark提供了类似Pig的功能
B.Shark把SQL语句转换成MapReduce作业
C.Shark重用了Hive中的HiveQL解析、逻辑执行计划翻译、执行计划优化等逻辑
D.Shark的性能比Hive差很多
2单选(2分)下面关于Spark SQL架构的描述错误的是:D
A.在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题
B.Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据
C.Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
D.Spark SQL执行计划生成和优化需要依赖Hive来完成
3单选(2分)要把一个DataFrame保存到people.json文件中,下面语句哪个是正确的:A
A.df.write.json("people.json")
B.df.json("people.json")
C.df.write.format("csv").save("people.json")
D.df.write.csv("people.json")
4多选(3分)Shark的设计导致了两个问题:AC
A.执行计划优化完全依赖于Hive,不方便添加新的优化策略
B.执行计划优化不依赖于Hive,方便添加新的优化策略
C.Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支
D.Spark是进程级并行,而MapReduce是线程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支
5 多选(3分)下面关于为什么推出Spark SQL的原因的描述正确的是:AB
A.Spark SQL可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系操作
B.可以支持大量的数据源和数据分析算法,组合使用Spark SQL和Spark MLlib,可以融合传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力
C.Spark SQL无法对各种不同的数据源进行整合
D.Spark SQL无法融合结构化数据管理能力和机器学习算法的数据处理能力
6多选(3分)下面关于DataFrame的描述正确的是:ABCD
A.DataFrame的推出,让Spark具备了处理大规模结构化数据的能力
B.DataFrame比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能
C.Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
D.DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
7多选(3分)要读取people.json文件生成DataFrame,可以使用下面哪些命令:AC
A.spark.read.json("people.json")
B.spark.read.parquet("people.json")
C.spark.read.format("json").load("people.json")
D.spark.read.format("csv").load("people.json")
8单选(2分)以下操作中,哪个不是DataFrame的常用操作:D
A.printSchema()
B.select()
C.filter()
D.sendto()
9多选(3分)从RDD转换得到DataFrame包含两种典型方法,分别是:AB
A.利用反射机制推断RDD模式
B.使用编程方式定义RDD模式
C.利用投影机制推断RDD模式
D.利用互联机制推断RDD模式
10多选(3分)使用编程方式定义RDD模式时,主要包括哪三个步骤:ABD
A.制作“表头”
B.制作“表中的记录”
C.制作映射表
D.把“表头”和“表中的记录”拼装在一起
4. PySpark-DataFrame各种常用操作
基于df的操作:
打印数据 df.show()默认打印前20条数据

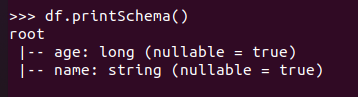
打印概要 df.printSchema()
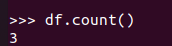
查询总行数 df.count()
df.head(3) #list类型,list中每个元素是Row类

输出全部行 df.collect() #list类型,list中每个元素是Row类

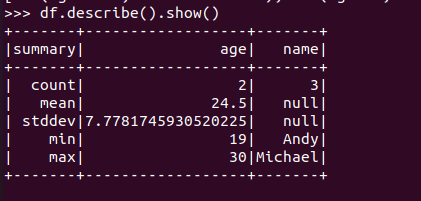
查询概况 df.describe().show()
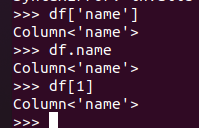
取列 df[‘name’], df.name, df[1]
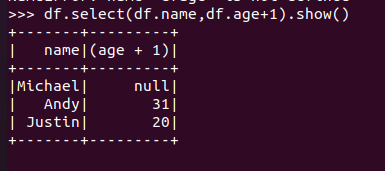
选择 df.select() 每个人的年龄+1
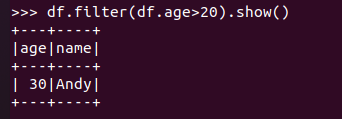
筛选 df.filter() 20岁以上的人员信息
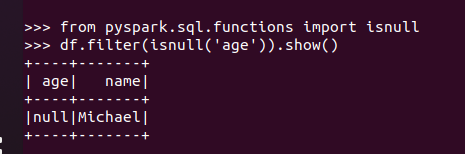
筛选年龄为空的人员信息
分组df.groupBy() 统计每个年龄的人数

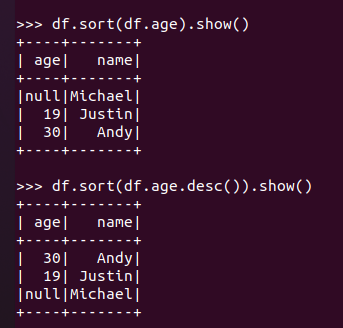
排序df.sortBy() 按年龄进行排序
基于spark.sql的操作:
创建临时表虚拟表 df.registerTempTable('people')
spark.sql执行SQL语句

5. Pyspark中DataFrame与pandas中DataFrame
分别从文件创建DataFrame

比较两者的异同
1.地址写法不同
2.pyspark的df要通过操作查看结果
3.pandas的df自动加索引
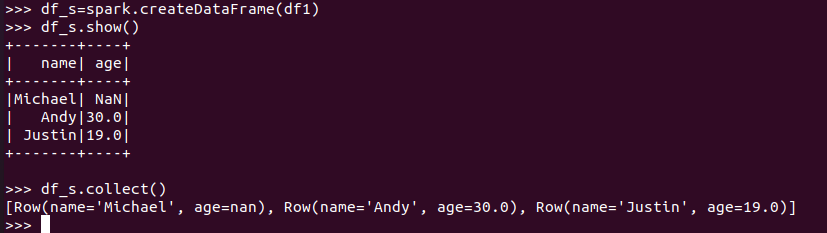
pandas中DataFrame转换为Pyspark中DataFrame
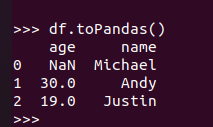
Pyspark中DataFrame转换为pandas中DataFrame
6.从RDD转换得到DataFrame
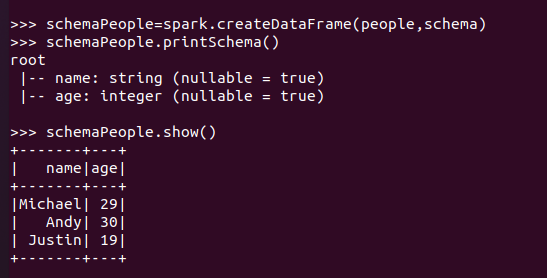
6.1 利用反射机制推断RDD模式
创建RDD sc.textFile(url).map(),读文件,分割数据项
每个RDD元素转换成 Row
由Row-RDD转换到DataFrame

6.2 使用编程方式定义RDD模式
#下面生成“表头”

#下面生成“表中的记录”

#下面把“表头”和“表中的记录”拼装在一起


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!