

第一次个人编程作业
PART 1 GitHub链接
PART 2 计算模块接口的设计与实现过程
-
(1)首先,凭借我的能力想必是没办法完成这个任务的,在柯老板的指导下:“拥抱开源”,于是我在csdn寻找答案。在看了许多大佬的博客之后就打算用余弦相似度算法,为什么余弦可以计算相似度呢,这个时候就需要引出一篇大佬博客--> 余弦计算相似度度量
PS:这里要附上找到的大佬的GitHub链接内含五种相似度计算方法的大佬的GitHub仓库 <--我的代码就是借鉴里面的 -
(2)算法实现流程图
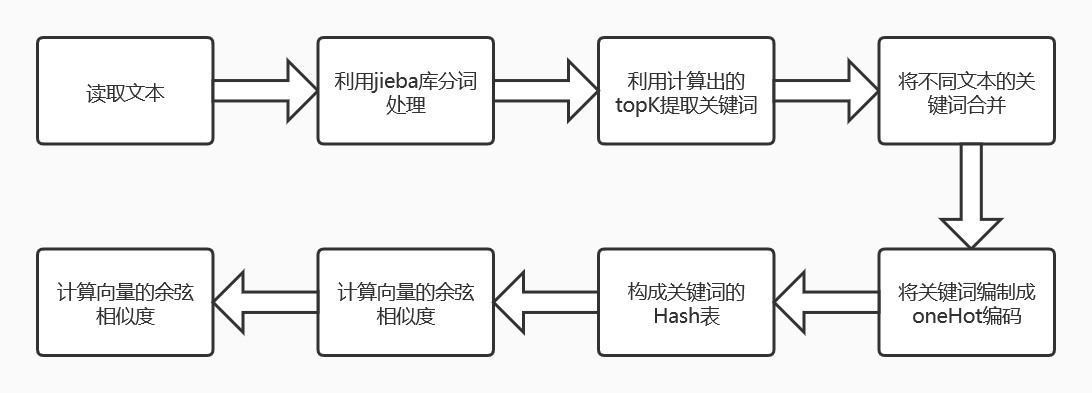
-
(3)模块介绍
- 首先需要安装python的一些库
- jieba(中文分词)
- sklearn(机器学习)
- 整段代码用一个类(CosineSimilarity)封装,每个步骤封装成函数
- 定义了一个对类CosineSimilarity的构造
# 对CosineSimilarity的构造 def __init__(self, file1, file2): self.s1 = file1 self.s2 = file2- get_keyword先通过jieba分词,提取出前K个权重最大的关键词
def get_keyword(content): # 提取关键词 seg = [i for i in jieba.cut(content, cut_all=True) if i != ''] # 分词 # 按照权重返回前topK个关键词 keywords = jieba.analyse.extract_tags("|".join(seg), topK=K, withWeight=False) return keywords- 用one_hot函数对关键词进行编码 (什么是OneHot编码,如何构建-->one hot 编码及数据归一化 )
# oneHot编码 def one_hot(keyword_dict, keywords): cut_code = [0] * len(keyword_dict) for word in keywords: cut_code[keyword_dict[word]] += 1 return cut_code- calculate函数用于构建关键词hash表并计算余弦相似度
def calculate(self): # 提取关键词 keywords1 = self.get_keyword(self.s1) keywords2 = self.get_keyword(self.s2) # 词的并集 union = set(keywords1).union(set(keywords2)) # 构造hash表 keyword_dict = {} i = 0 for word in union: keyword_dict[word] = i i += 1 # oneHot编码 vector1 = self.one_hot(keyword_dict, keywords1) vector2 = self.one_hot(keyword_dict, keywords2) sample = [vector1, vector2] # 除0处理 try: simRate = cosine_similarity(sample) # 用sklearn自带的余弦相似度计算 return simRate[1][0] except Exception as e: print(e) return 0.0- 最后用主函数读取文件并生成类获得结果并输出
if __name__ == '__main__': # 命令行输入绝对路径 root_Path = sys.argv[1] copy_Path = sys.argv[2] ans_Path = sys.argv[3] # 读入两个文本 计算topK try: with open(root_Path, encoding='UTF-8') as fp: root = fp.read() seg = [i for i in jieba.cut(root, cut_all=True) if i != ''] K = int(len(seg) / 8) except: K = 0 try: with open(root_Path, encoding='UTF-8') as fp: ori = fp.read() with open(copy_Path, encoding='UTF-8') as fp: copy = fp.read() except Exception as e: print(e) model = CosineSimilarity(ori, copy) # 保留两位小数 similarity = round(model.calculate(), 2) # 输出答案到文本 try: with open(ans_Path, "w+", encoding='UTF-8') as fp: fp.write(str(similarity)) except Exception as e: print(e) - 首先需要安装python的一些库
PART 3 计算模块接口部分的性能改进
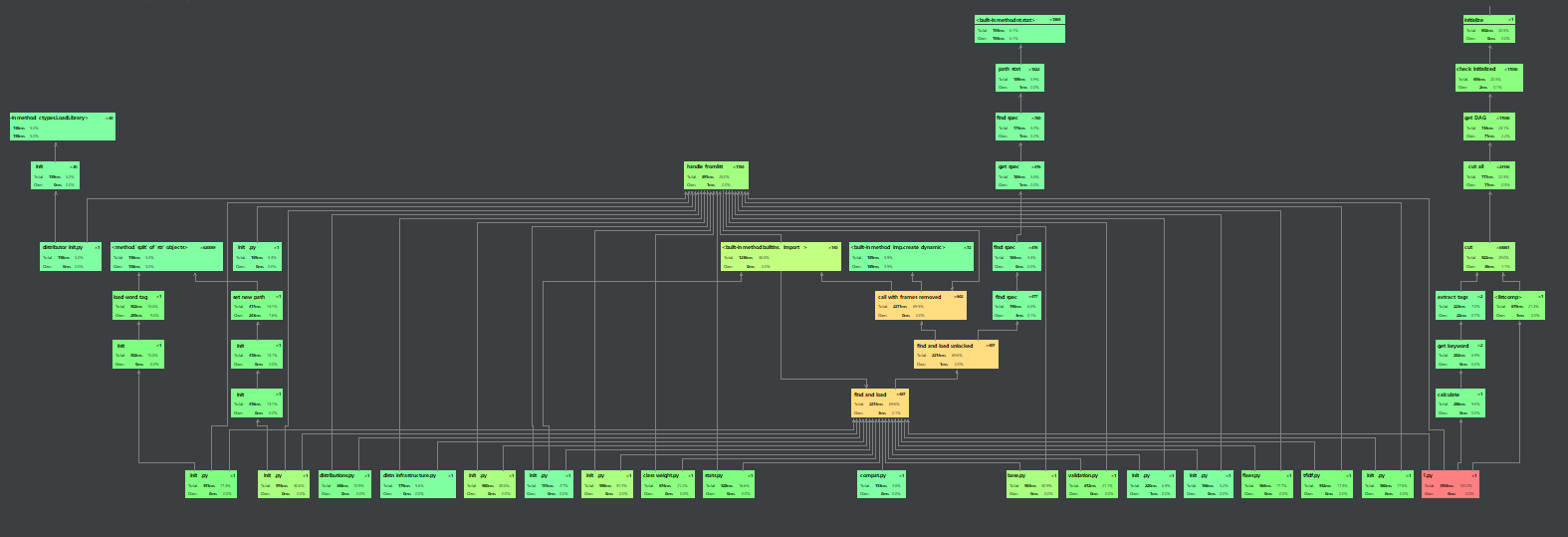
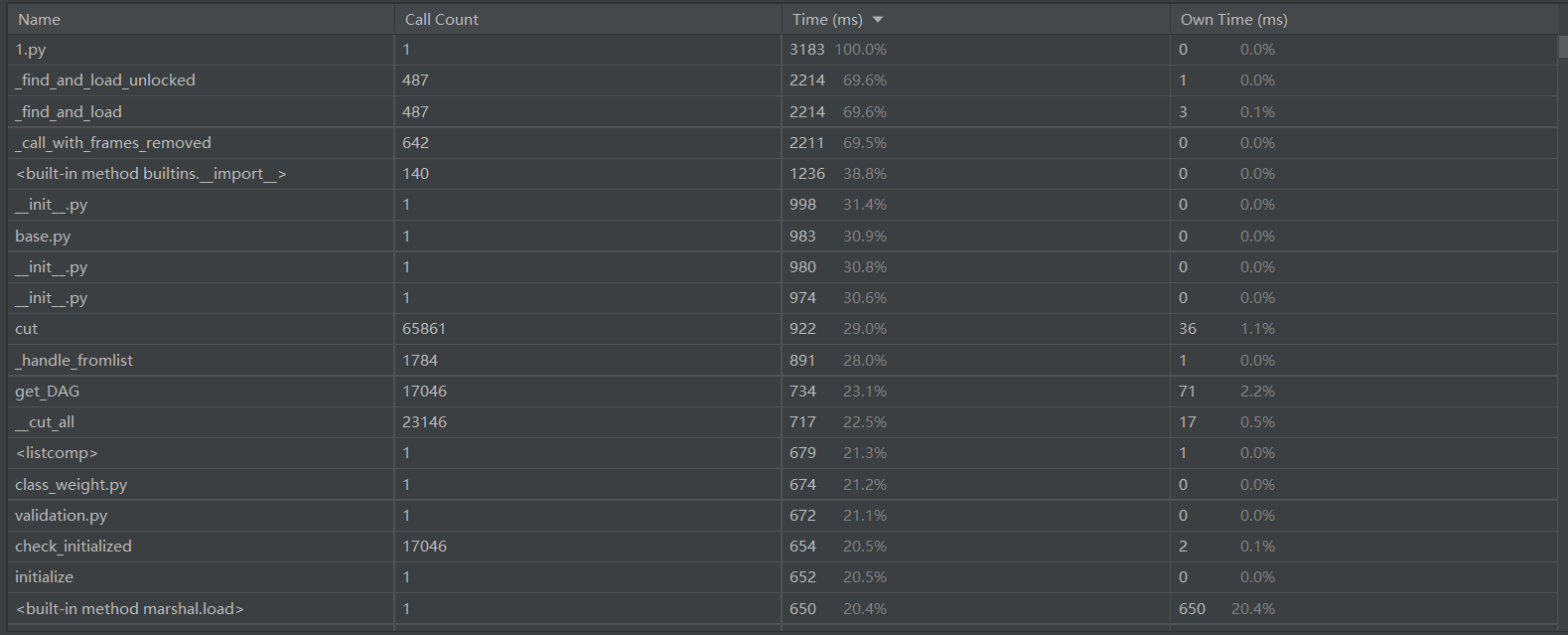
- 各个模块的消耗时间一览,可以看出分词这部分会占用大部分的内存和时间,如果想要优化的话要使用更加高效的分词方法
(对于我来说约等于没办法)
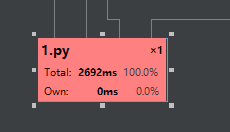
- 整个程序的运行时间满足要求
PART 4 计算模块部分单元测试展示
-
一开始还在想要如何测试,在偷偷看了强大的同学的博客之后发现了python自带的unittest测试函数,于是又打开了CSDN ╮(╯▽╰)╭
-
在尝试了好多好多好多次之后终于成功了( ̄∇ ̄) 并且得到的数据大概符合我的心理预期
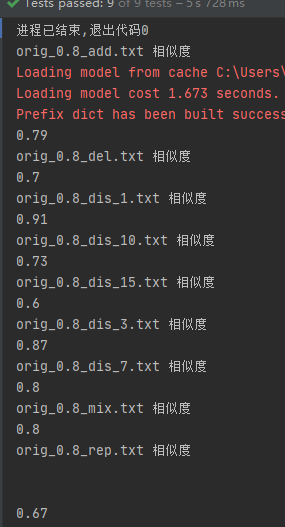
-
测试代码
import unittest
import project
class MyTest(unittest.TestCase):
def test_add(self):
print("orig_0.8_add.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_add.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_del(self):
print("orig_0.8_del.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_del.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_1(self):
print("orig_0.8_dis_1.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_dis_1.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_3(self):
print("orig_0.8_dis_3.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_dis_3.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_7(self):
print("orig_0.8_dis_7.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_dis_7.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_10(self):
print("orig_0.8_dis_10.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_dis_10.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_15(self):
print("orig_0.8_dis_15.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_dis_15.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_mix(self):
print("orig_0.8_mix.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_mix.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_rep(self):
print("orig_0.8_rep.txt 相似度")
with open("D:\\pythonProject\\sim_0.8\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("D:\\pythonProject\\sim_0.8\\orig_0.8_rep.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = project.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
if __name__ == '__main__':
unittest.main()
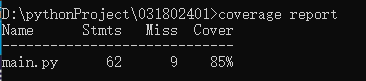
- 单元测试代码覆盖率
PART 5 计算模块部分异常处理说明
- 对输入两篇文本如果生成的余弦向量是零向量(即为空文本),那么直接对两零向量求余弦值会出问题的,需要进行异常处理
try:
simRate = cosine_similarity(sample)
return simRate[1][0]
except Exception as e:
print(e)
return 0.0
PART 6 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 50 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 40 | 40 |
| Development | 开发 | 450 | 500 |
| · Analysis | · 需求分析 (包括学习新技术) | 500 | 600 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 40 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 40 | 60 |
| · Coding | · 具体编码 | 180 | 240 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 60 | 60 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1530 | 1800 |
PART 7 总结
-
一开始学这门课,我要好好学习提高自己的代码能力。看到作业题目,
我是废物,我退学了,一脸懵逼。直到看到一些大佬早早的发博客and自己不断面向百度编程才有了一点思路。当然真叫我打我也是打不出来的——拥抱开源万岁!(读书人的事情能叫抄吗!) -
说实话学习代码和算法的时间并不是特别多,很多时间也花在使用工具上面了,比如git的链接到GitHub。
-
自己真的有太多东西不懂了,每次都是贼多浏览器窗口打开放着,直接进入递归学习模式。
希望人没事 -
写博客的过程也是对整个过程的回顾,让我对自己学到的东西有更加深刻的理解。

