2022-11-21-图像数据增强的常用方法
数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值。其原理是,**通过对原始数据融入先验知识,加工出更多数据的表示,有助于模型判别数据中统计噪声**,加强本体特征的学习,减少模型过拟合,提升泛化能力。
基于样本的数据增强
单样本增强
几何操作、颜色变换、随机擦除、添加噪声等方法,可参见imgaug开源库。
多样本数据增强
多样本增强是通过先验知识组合及转换多个样本,主要有Smote、SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值。
Smote
1、 对于各样本X_i,计算与同类样本的欧式距离,确定其同类的K个(如图3个)近邻样本;
2、从该样本k近邻中随机选择一个样本如近邻X_ik,生成新的样本:
Xsmote_ik = Xi + rand(0,1) ∗ ∣X_i − X_ik∣
3、重复2步骤迭代N次,可以合成N个新的样本。
SamplePairing
SamplePairing算法的核心思想是从训练集随机抽取的两幅图像叠加合成一个新的样本(像素取平均值),使用第一幅图像的label作为合成图像的正确label。
Mixup
1、从原始训练数据中随机选取的两个样本(xi, yi) and (xj, yj)。其中y(原始label)用one-hot 编码。
2、对两个样本按比例组合,形成新的样本和带权重的标签
x˜ = λxi + (1 − λ)xj
y˜ = λyi + (1 − λ)yj
基于深度学习的数据增强
将输入通过网络映射成低维向量、再进行数据增强
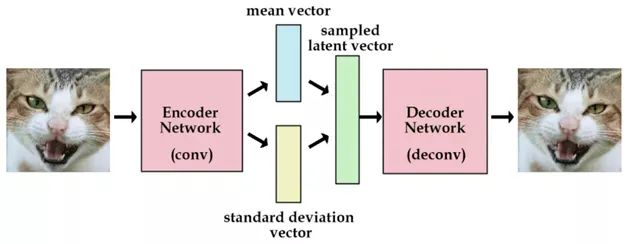
变分自编码器VAE
就是gan,将真实样本通过编码器网络变换成一个理想的数据分布,然后把数据分布再传递给解码器网络,构造出生成样本
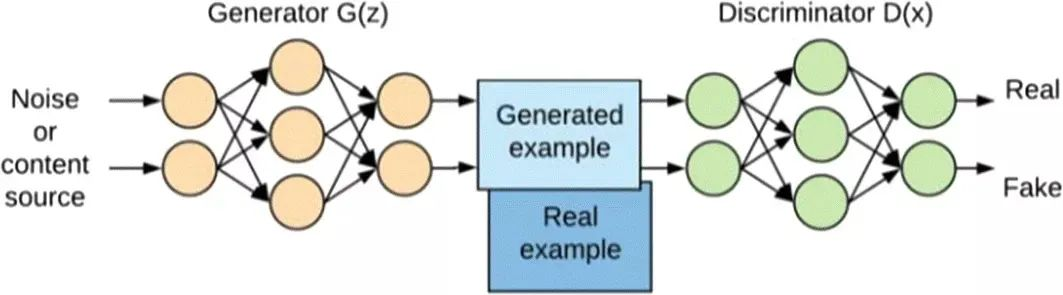
生成对抗网络GAN
基于神经风格迁移的数据增强
神经风格迁移是通过优化三类的损失来实现的:
style_loss:使生成的图像接近样式参考图像的局部纹理;
content_loss:使生成的图像的内容表示接近于基本图像的表示;
total_variation_loss:是一个正则化损失,它使生成的图像保持局部一致。
基于元学习的数据增强
- 神经增强
神经增强(Neural augmentation)是通过神经网络组的学习以获得较优的数据增强并改善分类效果的一种方法。其方法步骤如下:
1、获取与target图像同一类别的一对随机图像,前置的增强网络通过CNN将它们映射为合成图像,合成图像与target图像对比计算损失;
2、将合成图像与target图像神经风格转换后输入到分类网络中,并输出该图像分类损失;
3、将增强与分类的loss加权平均后,反向传播以更新分类网络及增强网络权重。使得其输出图像的同类内差距减小且分类准确。
transforms.ColorJitter 改变图像的属性:亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)
仿射变换:
transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, interpolation=<InterpolationMode.NEAREST: 'nearest'>, fill=0, fillcolor=None, resample=None, center=None)
degrees:可从中选择的度数范围。如果为非零数字,旋转角度从(-degrees,+degress),或者可设置为(min,max)
translate:水平和垂直平移的最大绝对偏移量。长度为2的元组,数值在(0,1)之间,dx在(-wa,wa),dy在(-hb,hb)
scale:比例因子区间,例如(a,b),则从范围a<=比例<=b中随机采样比例。默认情况下,将保留原始比例。
shear:可从中选择的度数范围。放射变换的角度
interpolation:插值的方法如果输入为Tensor只支持InterpolationMode.NEAREST, InterpolationMode.BILINEAR
fill:填充像素的值,
fillcolor:0.14以后版本被移除,使用fill代替
resample:0.14以后版本被移除,使用interpolation代替
center:旋转中心的位置,默认为图片的中心
[PyTorch 学习笔记] 2.3 二十二种 transforms 图片数据预处理方法 - 张贤同学 - 博客园 (cnblogs.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号