


索引法则--最佳左前缀法则
===============
最佳左前缀法则学习和Demo演示
1 准备数据
1.1 建表
DROP TABLE IF EXISTS staff; CREATE TABLE IF NOT EXISTS staff ( id INT PRIMARY KEY auto_increment, name VARCHAR(50), age INT, pos VARCHAR(50) COMMENT '职位', salary DECIMAL(10,2) );
1.2 插入数据
INSERT INTO staff(name, age, pos, salary) VALUES('Alice', 22, 'HR', 5000); INSERT INTO staff(name, age, pos, salary) VALUES('Bob', 22, 'RD', 10000); INSERT INTO staff(name, age, pos, salary) VALUES('David', 22, 'Sale', 120000);
2 测试&Explain分析
2.1 创建索引
CREATE INDEX idx_nameAgePos ON staff(name, age, pos);
创建了一个基于 name, age, pos 三个字段的索引
2.2 索引测试
Case#1:只根据 name 字段来查询
EXPLAIN SELECT * FROM staff WHERE name = 'Alice';
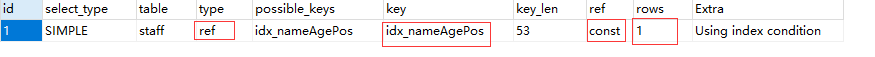
结果:
- type=ref
- key=索引
- ref=const
- ken_len=53
Case#2:只根据 name & age 字段来查询
EXPLAIN SELECT * FROM staff WHERE name = 'Alice' AND age = 22;

结果:和 Case#1 差不多,但是:
- key_len=58
- ref=const, const
Case#3:根据 name & age & pos 来查询
EXPLAIN SELECT * FROM staff WHERE name = 'Alice' AND age = 22 AND pos = 'HR';

结果:索引仍然生效,同时,key_len & ref 比 Case#2 中的结果更丰富
Case#4:根据 age & pos 来查询
EXPLAIN SELECT * FROM staff WHERE age = 22 AND pos = 'HR';

结果:没有索引,全表扫描
Case#5:根据 name & pos 来查询
EXPLAIN SELECT * FROM staff where name = 'Alice' AND pos = 'HR';

结果:和 Case#1 相同(说明 pos 字段没有用上索引)
3 总体分析
Case1,2,3都用了上索引,且使用索引长度依次增加(key_len=53,58,111 且 ref=1个const,2个const,3个const),符合最佳左前缀法则;
Case4中没有带头大哥(火车头),于是,全表扫描;
Case5中只有 name 字段使用上了索引,中间兄弟(中间车厢)age 断了,于是,后面的兄弟(车厢)pos 挂了;
4 总结
最佳左前缀法则:带头大哥不能死、中间兄弟不能断
