

http报文示例与详解
一般来说,http头部header组成一般由:1、general header 2、request headers 3、response headers三个部分组成,什么,你说还有entity-header?这个是response-headers的一个从属啦
当然,我们知道,我们的http分为请求和响应,对吧?所以,我们的请求,即http请求,
分为1、general header 2、request headers 3、request body
所以http响应分为:1、generalheader 2、response headers 3、response body
这里,我们以百度为例
以下三部分组成http headers
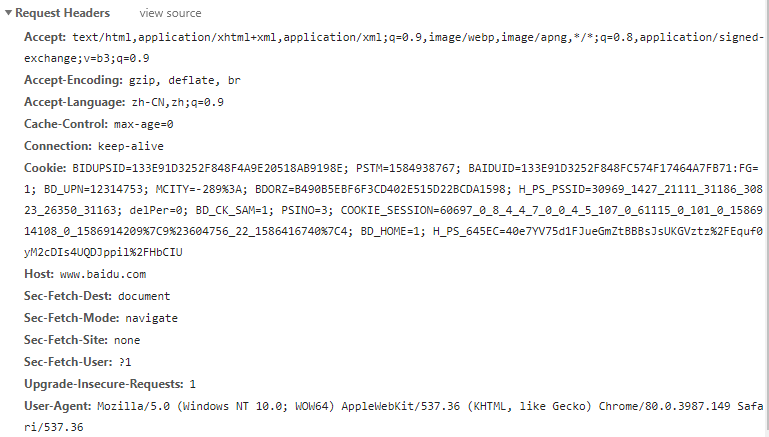
General head,顾名思义,请求和响应报文中,用来描述报文一般信息的头部,比如说这个报文请求和响应的Request URL是“http://www.baidu.com”,这种描述给人感觉有什么特点?
可以相互匹配把?请求和响应是成对出现的,除了没有响应以外,如果双方出现,必然是有部分general header是一致的,这样才是这一般信息的意义所在嘛,
而且,发送报文和接收报文都是消息,消息包含了信息,那信息也得需要描述把?信息所包含的信息量?你怎么来描述?这个时候,我们的general header的用处,就来啦!!!!

RequestHeaders
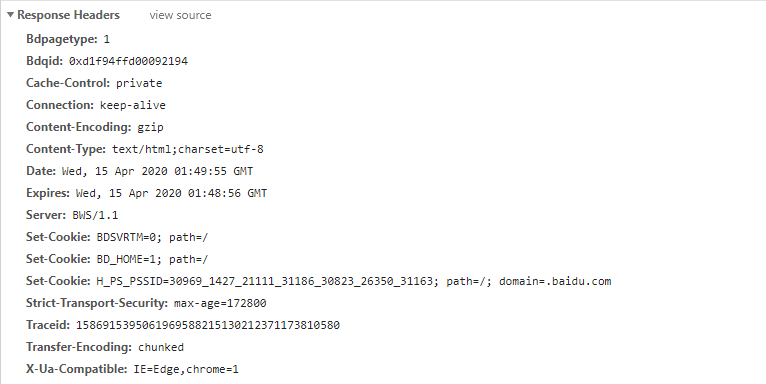
ResponseHeaders
说到这里,我们还没有枚举出entity header是什么,
https://www.w3.org/Protocols/rfc2616/rfc2616-sec7.html
这个是w3c标砖,rfc2626标准有讲到entity-header所包含的内容,如下:
Content-Encoding ; Section 14.11 | Content-Language ; Section 14.12 | Content-Length ; Section 14.13 | Content-Location ; Section 14.14 | Content-MD5 ; Section 14.15 | Content-Range ; Section 14.16 | Content-Type ; Section 14.17 | Expires ; Section 14.21 | Last-Modified ; Section 14.29 | extension-header
大家看到我们熟悉的Content-type,这个是存在response-headers里面的,所以entity-header就是response-header的一部分,
而我们的request-header里面,一般较为熟悉的有:
当然,这里的三个部分head是包含了请求和响应的所有header,至于body部分,get请求没有body,并非说不可以携带,并没有这个要求,然而绝大多数get请求基本上都没有携带body,你会发现,携带了body将显得多此一举,为何?
理由:服务段处理get请求返回响应时,返回的数据,一般应用场景,诸如浏览器,连接等场景,这种场景,直接一个请求url就可以搞定,试想?如果你在浏览网页的时候,发现有一个链接,你点击进去,而弹出网页,提示您需要添加body信息才能完整显示,难道这样的操作,或许只有专业的开发者或者程序员才能做?如果你这样开发服务端,我觉得挺6的,如果这个用户就喜欢这样的体验方式,我觉的也不是不能接受
如果不是“www.baidu.com”,其他的web操作,诸如post操作,那应该是看得到body主体的,这些东西,我将会在其他文章中作进一步的阐述,这里就不多赘述了
====================================================================================================================================================================================
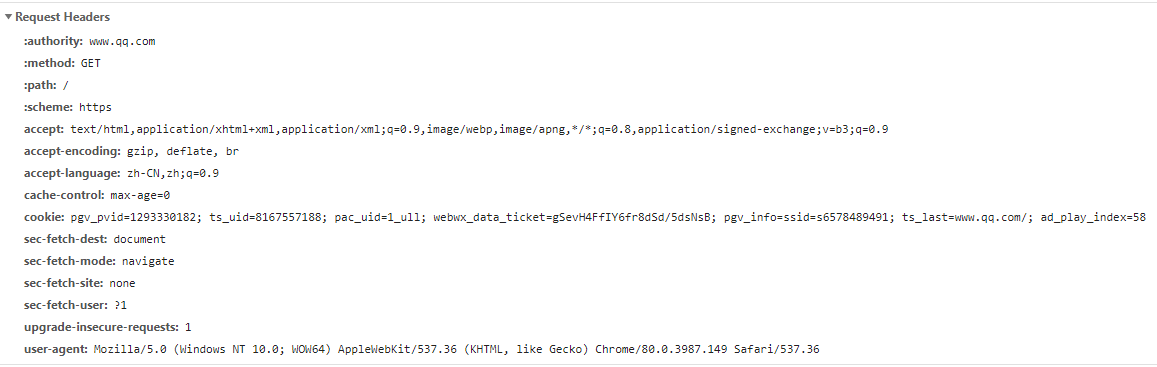
所谓一流公司卖标准,这样标准的协议是怎么来的呢??
response-headers
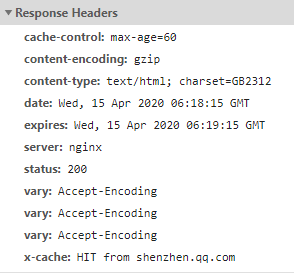
general-header
这说明了什么?
显然,关于header,鹅厂已经赶在了百度的前面了,已经聪明的认识到将请求头统统改为小写,这样无论服务端是大写还是小写,都能很好的体验,当然百度这样做,问题也不大,如果他的服务端是1.1的,那也没有影响,但这个细节体现出鹅厂的细致和潮流呀
