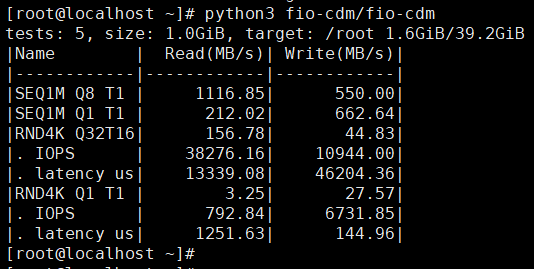
PVE-Ceph-RBD测试
集群型号与规模 CPU型号:3X24 x Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz (2 插槽) 内 存:110G 磁 盘:3 X 12 X 三星850 evo 500G (osd以raid0模式加入ceph)+3X1nvme 500G
可用osd个数:33个
ceph集群副本:3副本
ceph版本:ceph version 17.2.6 (810db68029296377607028a6c6da1ec06f5a2b27) quincy (stable)
内核版本 Linux 6.2.16-3-pve #1 SMP PREEMPT_DYNAMIC PVE 6.2.16-3 (2023-06-17T05:58Z)
PVE管理器版本 pve-manager/8.0.3/bbf3993334bfa916
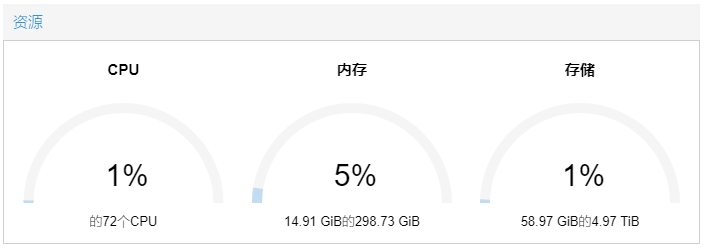
虚机测试


#!/usr/bin/env python # Author: Lu Xu <oliver_lew at outlook dot com> # License: MIT # Repo: https://github.com/OliverLew/fio-cdm import argparse import configparser import json import logging import os import shutil import sys import tempfile from subprocess import Popen, PIPE class Job: def __init__(self, args): args.target = os.path.realpath(args.target) # Standradize the size args.size = self.readable2byte(args.size) self._jobs = [] self._jobfile_id, self._jobfile_name = tempfile.mkstemp(suffix='.jobfile') self._jobfile = os.fdopen(self._jobfile_id, 'w') self._testfile_name = '.fio_testmark' self._blocksize = {'seq': '1m', 'rnd': '4k'} self._config = configparser.ConfigParser(allow_no_value=True) self._config.read_dict({ 'global': { 'ioengine': 'windowsaio' if os.name == 'nt' else 'libaio', 'filename': self._testfile_name, # escape colons, see man page 'filename' 'directory': args.target.replace(':', r'\:'), 'size': args.size, 'direct': '1', # borrowed configuration from shell version 'runtime': '5', 'refill_buffers': None, 'norandommap': None, 'randrepeat': '0', 'allrandrepeat': '0', 'group_reporting': None } }) if args.zero_buffers: self._config.read_dict({'global': {'zero_buffers': None}}) # Windows does not support pthread mutexes, suppress the warning if os.name == 'nt': self._config.read_dict({'global': {'thread': None}}) # TODO: fit output of different lengths self._header = "|Name | Read(MB/s)| Write(MB/s)|" self._sep = "|------------|------------|------------|" self._template_row = "|{jobname}|{read:12.2f}|{write:12.2f}|" if args.mix: self._header += " Mix(MB/s)|" self._sep += "------------|" self._template_row += "{mix:12.2f}|" def readable2byte(self, raw): try: num = raw.lower().rstrip("b").rstrip("i") units = {'k': 1, 'm': 2, 'g': 3, 't': 4, 'p': 5} return float(num[:-1]) * 1024 ** units[num[-1]] if num[-1] in units else float(num) except ValueError: logging.error("Unrecognised size: %s. Need: [0-9]*[KMGTP][i][B]", raw) exit(1) def byte2readable(self, num): for unit in ['B', 'KiB', 'MiB', 'GiB', 'TiB']: if abs(num) < 1024.0: return "{:3.1f}{}".format(num, unit) num /= 1024.0 return "{:.1f}{}".format(num, 'PiB') def _jobname_templ(self, job, rw): return "{}-{rw}-{}-q{}-t{}".format(job["rnd"], job["bs"], job["q"], job["t"], rw=rw) def _displayname(self, job): return "{}{} Q{:<2}T{:<2}".format(job["rnd"], job["bs"], job["q"], job["t"]).upper() def create_job(self, rnd_type, queue_size, thread_num): try: blocksize = self._blocksize[rnd_type] except KeyError as e: logging.error("Job type only accepts 'seq' and 'rnd'") raise e job = {"rnd": rnd_type, "bs": blocksize, "q": queue_size, "t": thread_num} self._jobs.append(job) for rw in ["read", "write", "rw"] if args.mix else ["read", "write"]: self._config.read_dict({ self._jobname_templ(job, rw): { 'rw': rw if rnd_type == 'seq' else 'rand' + rw, 'bs': blocksize, 'rwmixread': args.mix, 'iodepth': queue_size, 'numjobs': thread_num, 'loops': args.number, 'stonewall': None } }) def run(self): # Will exit if not enough space available space_info = self._check_disk_space() if args.dump_jobfile: if args.dump_jobfile == '-': self._config.write(sys.stdout, space_around_delimiters=False) else: with open(args.dump_jobfile, 'w') as fp: self._config.write(fp, space_around_delimiters=False) exit() else: self._config.write(self._jobfile, space_around_delimiters=False) self._jobfile.close() print("tests: {}, size: {}, target: {} {}".format( args.number, self.byte2readable(args.size), args.target, space_info )) if args.mix: print("Mixed rw: read {:2.0f}%, write {:2.0f}%".format(args.mix, 100 - args.mix)) FIO_COMMAND = ['fio', '--output-format', 'json', self._jobfile_name] try: res = Popen(FIO_COMMAND, stdout=PIPE) output, _ = res.communicate() except KeyboardInterrupt: logging.info('interrupted, cleaning up before exit...') exit() finally: if os.path.exists(self._jobfile_name): os.remove(self._jobfile_name) if os.path.exists(os.path.join(args.target, self._testfile_name)): os.remove(os.path.join(args.target, self._testfile_name)) if res.returncode == 0: fio_output = json.loads(output) else: exit() # rearrange to make jobname as keys info = {job.pop("jobname"): job for job in fio_output["jobs"]} logging.debug(info) self._print(info) def _printline(self, info, job, name, f): read = f(info.get(self._jobname_templ(job, "read"))['read']) write = f(info.get(self._jobname_templ(job, "write"))['write']) if args.mix: mixr = f(info.get(self._jobname_templ(job, "rw"))['read']) mixw = f(info.get(self._jobname_templ(job, "rw"))['write']) mix = (mixw * (100 - args.mix) + mixr * args.mix) / 100.0 else: mix = None print(self._template_row.format(jobname=name, read=read, write=write, mix=mix)) def _info_get_bw_megabytes(self, info): # Unit of I/O speed, use MB/s(10^6) instead of MiB/s(2^30). return info.get('bw_bytes', info['bw'] * 1e3) / 1e6 def _print(self, info): print(self._header) print(self._sep) for job in self._jobs: self._printline(info, job, self._displayname(job), self._info_get_bw_megabytes) if job['rnd'] == 'rnd' and args.extra_info: self._printline(info, job, ". IOPS ", lambda d: d['iops']) self._printline(info, job, ". latency us", lambda d: d['lat_ns']['mean'] / 1000) def _check_disk_space(self): if hasattr(shutil, "disk_usage"): # Python3 du = shutil.disk_usage(args.target) free = du.free used = du.used total = du.total elif hasattr(os, "statvfs"): # Python2 + Unix-like stat = os.statvfs(args.target) free = stat.f_bsize * stat.f_bavail total = stat.f_bsize * stat.f_blocks used = total - stat.f_bsize * stat.f_bfree else: # Python2 + Windows? No way! logging.warning("It's hard to get disk usage for current system and" " python version,\nskipping available space checking.") return "(disk usage not avallable)" if free >= args.size: return "{}/{}".format(self.byte2readable(used), self.byte2readable(total)) logging.error("Not enough space available in %s:", args.target) logging.error("Needed: %s. Available: %s", self.byte2readable(args.size), self.byte2readable(free)) exit(1) def get_parser(): parser = argparse.ArgumentParser( description='A python script to show disk test results with fio') parser.add_argument('target', nargs='?', default='.', help='The path of the directory to test. ' 'Default to current directory') parser.add_argument('-0', dest='zero_buffers', action='store_true', help='Initialize buffers with zeros. ' 'Default to use random buffers.') parser.add_argument('-a', metavar='job', dest='jobs', action="append", help='Manually add multiple jobs. Format is ' '"seq|rnd,<queue depth>,<thread number>". ' 'This overrides the preset jobs. ' 'This option can be used more than once.') parser.add_argument('-E', dest='extra_info', action='store_false', help='Disable extra information (iops, latency) for ' 'random IO tests. Default is enabled.') parser.add_argument('-f', metavar='jobfile', dest='dump_jobfile', help='Save jobfile and quit without running fio. ' 'Use "-" to print to stdout.') parser.add_argument('-n', metavar='number', dest='number', type=int, default=5, help='Number of tests, default is 5.') parser.add_argument('-s', metavar='size', dest='size', default='1G', help='The size of file I/O. ' 'It is directly passed to fio. ' 'Default is 1G.') parser.add_argument('-x', metavar='mix', dest='mix', type=float, nargs="?", const=70, default=0, help='Add mixed rw test. Default is disabled. ' '<mix> is read percentage. Default is 70.') # hidden option, enable to show debug information parser.add_argument('-g', dest='debug', action='store_true', help=argparse.SUPPRESS) return parser if __name__ == '__main__': # TODO: Real-time visual feedback, with fio --debug=io? Seams hard. # TODO: Linux: vendor and model with lsblk -o +VENDOR,MODEL or /sys/block/*/device/{vendor,model} # TODO: Specify device instead of directory parser = get_parser() args = parser.parse_args() logging.basicConfig(level=logging.DEBUG if args.debug else logging.INFO, format="%(message)s") fio_job = Job(args) if args.jobs: for job in args.jobs: rnd_type, qd, tn = job.split(',') fio_job.create_job(rnd_type, int(qd), int(tn)) else: fio_job.create_job('seq', 8, 1) fio_job.create_job('seq', 1, 1) fio_job.create_job('rnd', 32, 16) fio_job.create_job('rnd', 1, 1) fio_job.run()