
Ceph使用---存储池、PG与CRUSH
一、存储池、PG与CRUSH
1.1、存储池
副本池:replicated, 定义每个对象在集群中保存为多少个副本, 默认为三个副本, 一主两备,实现高可用, 副本池是 ceph 默认的存储池类型。
纠删码池(erasure code): 把各对象存储为 N=K+M 个块(chunk), 其中 K 为数据块数量, M为编码快数量, 因此存储池的总大小 N 等于 K+M。即数据保存在 K 个数据块, 并提供 M 个冗余块提供数据高可用, 那么最多能故障的块就是M 个, 实际的磁盘占用就是 K+M 块, 因此相比副本池机制比较节省存储资源, 一般采用8+4 机制( 默认为 2+2), 即 8 个数据块+4 个冗余块, 那么也就是 12 个数据块有 8 个数据块保存数据, 有 4 个实现数据冗余, 即 1/3 的磁盘空间用于数据冗余, 比默认副本池的三倍冗余节省空间, 但是不能出现大于一定数据块故障。
但是不是所有的应用都支持纠删码池, RBD 只支持副本池而 radosgw 则可以支持纠删码池。
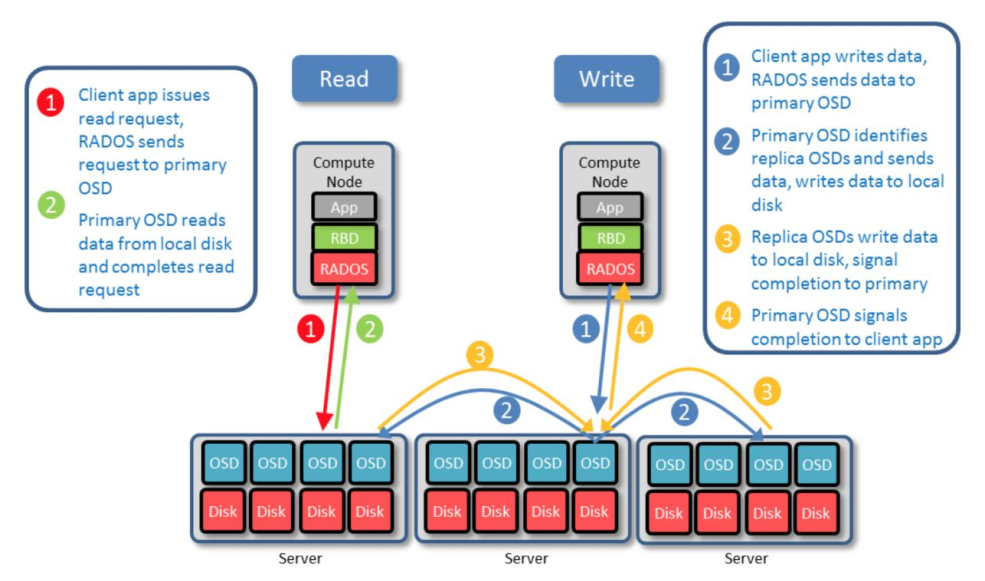
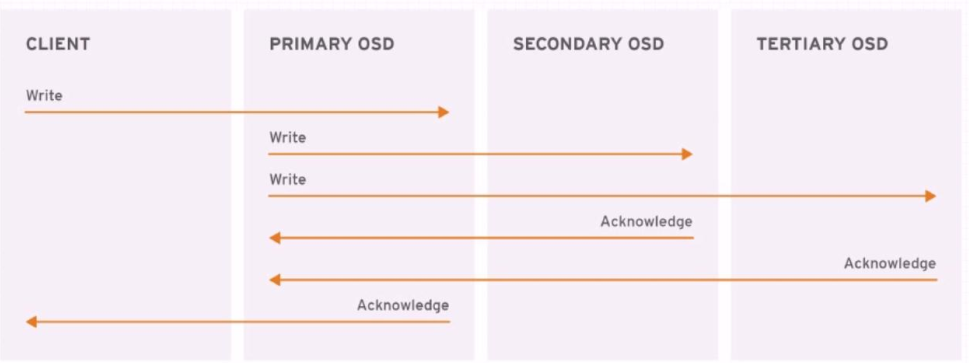
副本池 IO
将一个数据对象存储为多个副本在客户端写入操作时, ceph 使用 CRUSH 算法计算出与对象相对应的 PG ID 和 primary OSD主 OSD 根据设置的副本数、 对象名称、 存储池名称和集群运行图(cluster map)计算出 PG的各辅助 OSD, 然后由 OSD 将数据再同步给辅助 OSD。
读取数据:
- 客户端发送读请求, RADOS 将请求发送到主 OSD。
- 主 OSD 从本地磁盘读取数据并返回数据, 最终完成读请求。
写入数据:
- 客户端 APP 请求写入数据, RADOS 发送数据到主 OSD。
- 主 OSD 识别副本 OSDs, 并发送数据到各副本 OSD。
- 副本 OSDs 写入数据, 并发送写入完成信号给主 OSD。
- 主 OSD 发送写入完成信号给客户端 APP。
纠删码池 IO
http://ceph.org.cn/2016/08/01/ceph-%E7%BA%A0%E5%88%A0%E7%A0%81%E4%BB%8B%E7%BB%8D/
Ceph 从 Firefly 版本开始支持纠删码, 但是不推荐在生产环境使用纠删码池。
纠删码池降低了数据保存所需要的磁盘总空间数量, 但是读写数据的计算成本要比副本池高
RGW 可以支持纠删码池, RBD 不支持
纠删码池可以降低企业的前期 TCO 总拥有成本
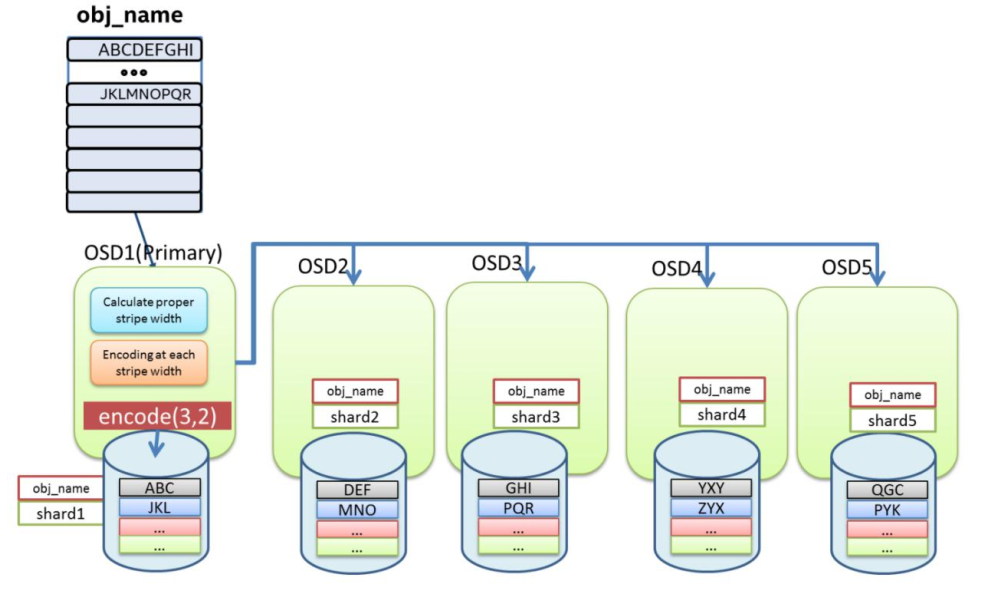
纠删码写:
数据将在主 OSD 进行编码然后分发到相应的 OSDs 上去。
1.计算合适的数据块并进行编码
2.对每个数据块进行编码并写入 OSD
#创建纠删码池 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create erasure-testpool 16 16 erasure pool 'erasure-testpool' created cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd erasure-code-profile get default k=2 m=2 plugin=jerasure technique=reed_sol_van
cephadmin@ceph-deploy:~/ceph-cluster$
k=2 #k 为数据块的数量, 即要将原始对象分割成的块数量,例如,如果 k = 2, 则会将一个10kB 对象分割成两个(k)各为 5kB 的对象。
m=2 #编码块(chunk)的数量, 即编码函数计算的额外块的数量。如果有2个编码块,则表示有两个额外的备份,最多可以从当前pg中宕机2个OSD,而不会丢失数据。
plugin=jerasure #默认的纠删码池插件technique=reed_sol_van
#写入数据
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados put -p erasure-testpool testfile1 /var/log/syslog cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$
#验证证数据:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd map erasure-testpool testfile1 osdmap e224 pool 'erasure-testpool' (9) object 'testfile1' -> pg 9.3a643fcb (9.b) -> up ([8,NONE,5,1], p8) acting ([8,NONE,5,1], p8) cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$
#验证pg状态
cephadmin@ceph-deploy:~/ceph-cluster$ ceph pg ls-by-pool erasure-testpool | awk '{print $1,$2,$15}' PG OBJECTS ACTING 9.0 0 [1,5,6,NONE]p1 9.1 0 [0,NONE,7,3]p0 9.2 0 [1,3,7,NONE]p1 9.3 0 [7,1,NONE,5]p7 9.4 0 [1,5,8,NONE]p1 9.5 0 [6,4,NONE,1]p6 9.6 0 [5,8,0,NONE]p5 9.7 0 [7,4,1,NONE]p7 9.8 0 [8,1,3,NONE]p8 9.9 0 [6,NONE,0,4]p6 9.a 0 [3,0,7,NONE]p3 9.b 1 [8,NONE,5,1]p8 9.c 0 [2,3,7,NONE]p2 9.d 0 [3,0,7,NONE]p3 9.e 0 [3,6,0,NONE]p3 9.f 0 [5,2,8,NONE]p5 * NOTE: afterwards cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$
获取测试数据
cephadmin@ceph-deploy:~/ceph-cluster$ rados --pool erasure-testpool get testfile1 -
Oct 7 09:39:04 ceph-deploy rsyslogd: [origin software="rsyslogd" swVersion="8.2001.0" x-pid="684" x-info="https://www.rsyslog.com"] rsyslogd was HUPed Oct 7 09:39:04 ceph-deploy snapd[687]: AppArmor status: apparmor is enabled and all features are available Oct 7 09:39:04 ceph-deploy systemd[1]: logrotate.service: Succeeded. Oct 7 09:39:04 ceph-deploy systemd[1]: Finished Rotate log files. Oct 7 09:39:04 ceph-deploy dbus-daemon[672]: [system] AppArmor D-Bus mediation is enabled Oct 7 09:39:04 ceph-deploy systemd[1]: Started Login Service. Oct 7 09:39:04 ceph-deploy dbus-daemon[672]: [system] Successfully activated service 'org.freedesktop.systemd1' Oct 7 09:39:04 ceph-deploy wpa_supplicant[691]: Successfully initialized wpa_supplicant Oct 7 09:39:04 ceph-deploy systemd[1]: Started WPA supplicant. Oct 7 09:39:04 ceph-deploy systemd[1]: Started Dispatcher daemon for systemd-networkd. Oct 7 09:39:06 ceph-deploy mandb[735]: /usr/bin/mandb: can't set the locale; make sure $LC_* and $LANG are correct Oct 7 09:39:08 ceph-deploy udisksd[690]: failed to load module mdraid: libbd_mdraid.so.2: cannot open shared object file: No such file or directory Oct 7 09:39:08 ceph-deploy udisksd[690]: Failed to load the 'mdraid' libblockdev plugin Oct 7 09:39:08 ceph-deploy dbus-daemon[672]: [system] Activating via systemd: service name='org.freedesktop.PolicyKit1' unit='polkit.service' requested by ':1.8' (uid=0 pid=690 comm="/usr/lib/udisks2/udisksd " label="unconfined") Oct 7 09:39:08 ceph-deploy snapd[687]: AppArmor status: apparmor is enabled and all features are available Oct 7 09:39:08 ceph-deploy polkitd[682]: started daemon version 0.105 using authority implementation `local' version `0.105' Oct 7 09:39:08 ceph-deploy dbus-daemon[672]: [system] Successfully activated service 'org.freedesktop.PolicyKit1' Oct 7 09:39:08 ceph-deploy systemd[1]: Started Authorization Manager. Oct 7 09:39:08 ceph-deploy systemd[1]: Starting Modem Manager... 。。。。。。。。。。。。。。。。。。。。
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados get -p erasure-testpool testfile1 /tmp/testfile1 #下载数据
cephadmin@ceph-deploy:~/ceph-cluster$ sudo ls -lh /tmp/ total 48K drwx------ 3 root root 4.0K Oct 7 09:39 snap.lxd drwx------ 3 root root 4.0K Oct 7 09:39 systemd-private-88a6e6460a864685b951fe9597d3b16a-ModemManager.service-JCEDxi drwx------ 3 root root 4.0K Oct 7 09:39 systemd-private-88a6e6460a864685b951fe9597d3b16a-systemd-logind.service-PGlEvf drwx------ 3 root root 4.0K Oct 7 09:38 systemd-private-88a6e6460a864685b951fe9597d3b16a-systemd-resolved.service-k4fs0f drwx------ 3 root root 4.0K Oct 7 09:38 systemd-private-88a6e6460a864685b951fe9597d3b16a-systemd-timesyncd.service-RU2i9h -rw-r--r-- 1 root root 26K Oct 7 15:22 testfile1 cephadmin@ceph-deploy:~/ceph-cluster$
纠删码读:
从相应的 OSDs 中获取数据后进行解码。
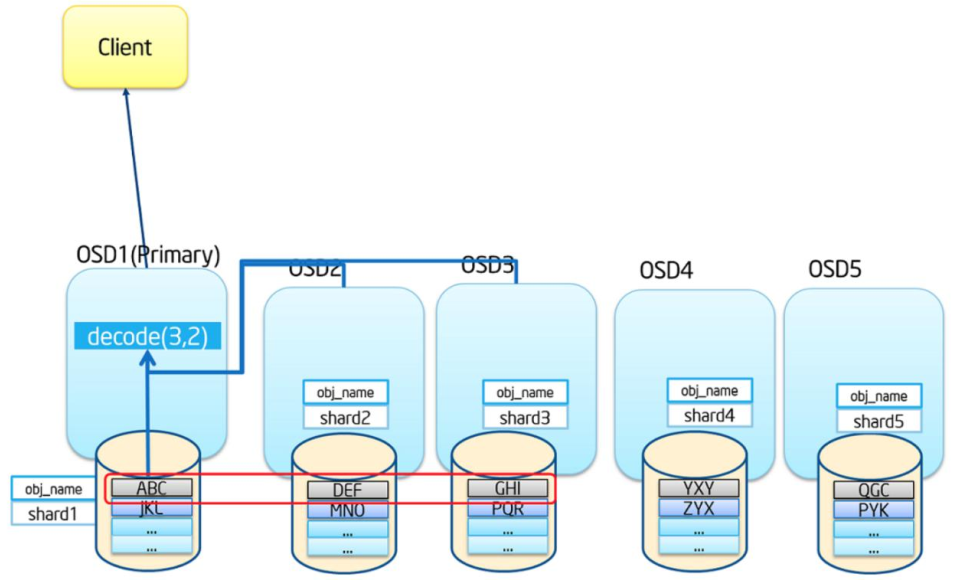
如果此时有数据丢失, Ceph 会自动从存放校验码的 OSD 中读取数据进行解码。

1.2、PG与PGP
PG = Placement Group #归置组, 默认每个 PG 三个 OSD(数据三个副本)
PGP = Placement Group for Placement purpose #归置组的组合, pgp 相当于是 pg 对应
osd 的一种逻辑排列组合关系(在不同的 PG 内使用不同组合关系的 OSD)。
加入 PG=32, PGP=32, 那么,数据最多被拆分为 32 份(PG), 写入到有 32 种组合关系(PGP)的 OSD 上。
归置组(placement group)是用于跨越多 OSD 将数据存储在每个存储池中的内部数据结构。
归置组在 OSD 守护进程和 ceph 客户端之间生成了一个中间层,CRUSH 算法负责将每个对象动态映射到一个归置组,然后再将每个归置组动态映射到一个或多个 OSD 守护进程,从而能够支持在新的 OSD 设备上线时进行数据重新平衡。
相对于存储池来说,PG 是一个虚拟组件,它是对象映射到存储池时使用的虚拟层。可以自定义存储池中的归置组数量。ceph 出于规模伸缩及性能方面的考虑,ceph 将存储池细分为多个归置组,把每个单独的对象映射到归置组,并为归置组分配一个主OSD。
存储池由一系列的归置组组成,而CRUSH算法则根据集群运行图和集群状态,将个PG均匀、伪随机(基于 hash 映射,每次的计算结果够一样)的分布到集群中的 OSD 之上。
如果某个OSD失败或需要对集群进行重新平衡,ceph则移动或复制整个归置组而不需要单独对每个镜像进行寻址。
PG与OSD关系
ceph 基于 crush 算法将归置组 PG 分配至 OSD
当一个客户端存储对象的时候, CRUSH 算法映射每一个对象至归置组(PG)
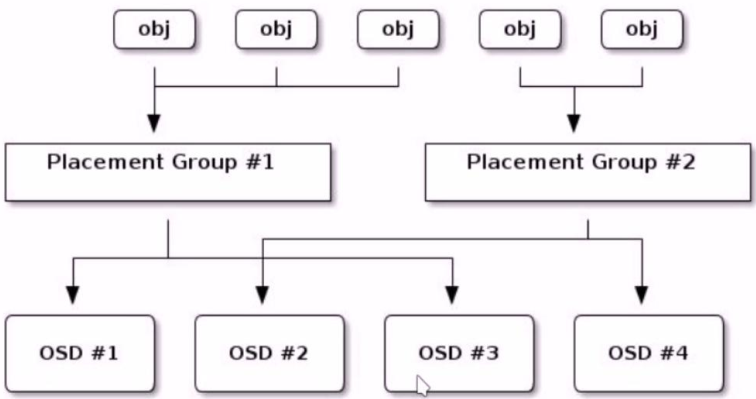
PG分配计算
一个 pool 应该使用多少个 PG, 可以通过下面的公式计算后,将 pool 的 PG 值四舍五入到最近的 2 的 N 次幂, 如下先计算出 ceph 集群的总 PG 数:
Total OSDs * PGPerOSD/replication factor => total PGs
磁盘总数 x 每个磁盘 PG 数/副本数 => ceph 集群总 PG 数(略大于 2^n 次方)
官方的计算公式:
Total PGs = (Total_number_of_OSD * 100) / max_replication_count
单个 pool 的 PG 计算如下:
有 100 个 osd, 3 副本, 5 个 pool
Total PGs =100*100/3=3333
每个 pool 的 PG=3333/5=512, 那么创建 pool 的时候就指定 pg 为 512
PG状态
Peering: 正在同步状态, 同一个 PG 中的 OSD 需要将准备数据同步一致, 而 Peering(对等)就是 OSD同步过程中的状态。 Activating: Peering 已经完成, PG 正在等待所有 PG 实例同步 Peering 的结果(Info、 Log 等) Clean: 干净态,PG 当前不存在待修复的对象,并且大小等于存储池的副本数,即 PG 的活动集(Acting Set)和上行集(Up Set)为同一组OSD且内容一致。 活动集(Acting Set):由 PG 当前主的 OSD 和其余处于活动状态的备用 OSD 组成, 当前 PG内的 OSD 负责处理用户的读写请求。 上行集(Up Set):在某一个OSD故障时,需要将故障的OSD更换为可用的OSD,并主PG内部的主OSD同步数据到新的OSD上, 例如PG内有OSD1、OSD2、OSD3,当OSD3故障后需要用OSD4替换OSD3,那么OSD1、OSD2、OSD3 就是上行集,替换后OSD1、OSD2、OSD4 就是活动集,OSD替换完成后活动集最终要替换上行集。 Active: 就绪状态或活跃状态, Active 表示主 OSD 和备 OSD 处于正常工作状态, 此时的 PG 可以正常处理来自客户端的读写请求, 正常的 PG 默认就是 Active+Clean 状态。 Degraded:降级状态: 降级状态出现于OSD被标记为down以后, 那么其他映射到此OSD的PG都会转换到降级状态。 如果此OSD还能重新启动完成并完成 Peering 操作后,那么使用此OSD的PG将重新恢复为clean状态。 如果此OSD被标记为down的时间超过5分钟还没有修复,那么此 OSD 将会被ceph踢出集群,然后ceph会对被降级的PG启动恢复操作,直到所有由于此OSD而被降级的PG重新恢复为clean状态。 恢复数据会从PG内的主OSD恢复,如果是主OSD故障,那么会在剩下的两个备用OSD重新选择一个作为主 OSD。 Stale:过期状态: 正常状态下,每个主 OSD 都要周期性的向 RADOS 集群中的监视器(Mon)报告其作为主OSD,所持有的所有 PG 的最新统计数据, 因任何原因导致某个 OSD 无法正常向监视器发送汇报信息的、 或者由其他 OSD 报告某个 OSD 已经 down 的时候, 则所有以此 OSD 为主 PG 则会立即被标记为 stale 状态, 即他们的主 OSD 已经不是最新的数据了,如果是备份的OSD发送down的时候,则ceph会执行修复而不会触发 PG 状态转换为stale状态。 undersized: PG当前副本数小于其存储池定义的值的时候,PG会转换为undersized状态,比如两个备份OSD都down了,那么此时PG中就只有一个主OSD了,不符合ceph最少要求一个主OSD加一个备OSD的要求,那么就会导致使用此OSD的PG转换为undersized状态,直到添加备份OSD添加完成,或者修复完成。 Scrubbing: scrub 是 ceph 对数据的清洗状态, 用来保证数据完整性的机制, Ceph 的 OSD 定期启动 scrub 线程来扫描部分对象, 通过与其他副本比对来发现是否一致, 如果存在不一致, 抛出异常提示用户手动解决, scrub 以 PG 为单位, 对于每一个 pg, ceph 分析该 pg 下所有的 object, 产生一个类似于元数据信息摘要的数据结构, 如对象大小, 属性等, 叫 scrubmap, 比较主与副 scrubmap, 来保证是不是有 object 丢失或者不匹配, 扫描分为轻量级扫描和深度扫描, 轻量级扫描也叫做 light scrubs 或者 shallow scrubs 或者 simply scrubs 即轻量级扫描. Light scrub(daily)比较 object size 和属性, deep scrub (weekly)读取数据部分并通过checksum(CRC32算法)对比和数据的一致性,深度扫描过程中的PG会处于scrubbing+deep 状态。 Recovering: 正在恢复态,集群正在执行迁移或同步对象和他们的副本,这可能是由于添加了一个新的OSD到集群中或者某个OSD宕掉后,PG可能会被CRUSH算法重新分配不同的OSD,而由于 OSD 更换导致 PG 发生内部数据同步的过程中的 PG 会被标记为 Recovering。 Backfilling: 正在后台填充态,backfill是recovery的一种特殊场景,指peering完成后,如果基于当前权威日志无法对 Up Set(上行集)当中的某些PG实例实施增量同步(例如承载这些 PG 实例的 OSD 离线太久, 或者是新的 OSD 加入集群导致的 PG 实例整体迁移) 则通过完全拷贝当前 Primary 所有对象的方式进行全量同步, 此过程中的 PG 会处于 backfilling。 Backfill-toofull: 某个需要被Backfill的PG实例,其所在的OSD可用空间不足,Backfill流程当前被挂起时PG给的状态。
数据读写流程
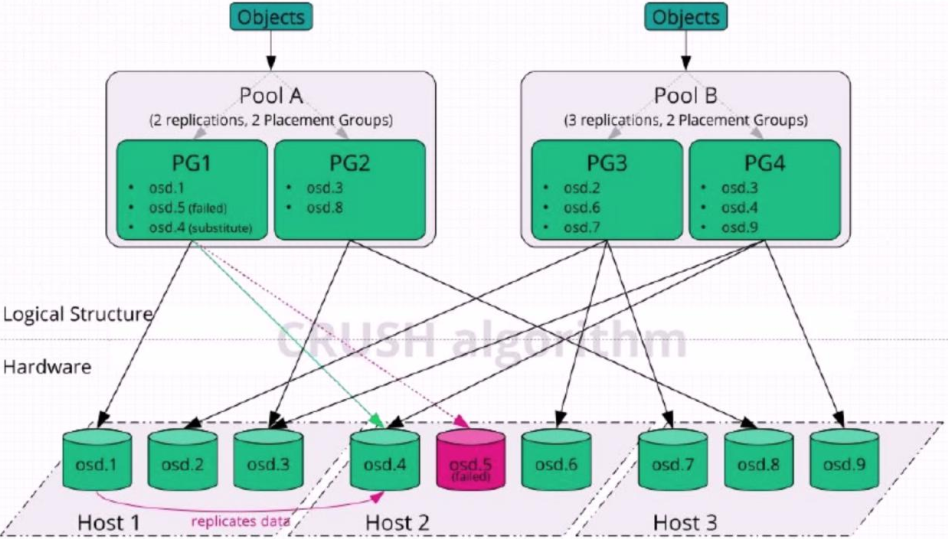
ceph 读写对象的时候,客户端从 ceph 监视器检索出集群运行图(cluster map),然后客户端访问指定的存储池,并对存储池内PG的对象执行读写操作。
存储池的CRUSH计算结果和PG的数量,是决定ceph如何放置数据的关键因素。基于集群的最新运行图,客户端能够了解到集群中的所有监视器和OSD以及他们各自当前的状态。但是客户端仍然不知道对象的保存位置。
客户端在读写对象时,需要提供的是对象标识和存储池名称。客户端需要在存储池中读写对象时,需要客户端将对象名称、对象名称的hash码、存储池中的PG数量和存储池名称作为输入信息提供给ceph,然后由CRUSH计算出PG的ID以及此PG针对的主OSD即可读写OSD中的对象。
具体写操作如下:
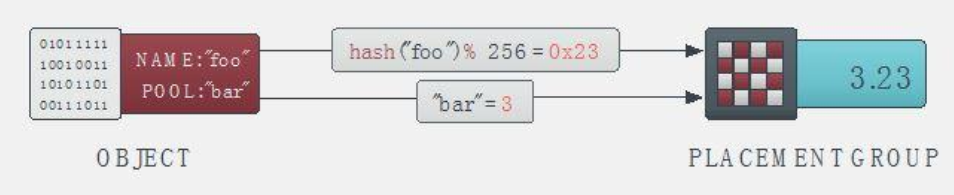
1.APP 向 ceph 客户端发送对某个对象的请求, 此请求包含对象和存储池, 然后 ceph 客户端对访问的对象做 hash 计算, 并根据此 hash 值计算出对象所在的 PG, 完成对象从 Pool至 PG 的映射。
APP 访问 pool ID 和 object ID (比如 pool = pool1 and object-id = “name1” )
ceph client 对 objectID 做哈希
ceph client 对该 hash 值取 PG 总数的模, 得到 PG 编号(比如 32),(第 2 和第 3 步基本保证了一个 pool 内部的所有 PG 将会被均匀地使用)
ceph client 对 pool ID 取 hash(比如 “pool1” = 3)
ceph client 将 pool ID 和 PG ID 组合在一起(比如 3.23)得到 PG 的完整 ID。
2.然后客户端据 PG、 CRUSH 运行图和归置组(placement rules)作为输入参数并再次进行计算, 并计算出对象所在的 PG 内的主 OSD , 从而完成对象从 PG 到 OSD 的映射。
Ceph client 从 MON 获取最新的 cluster map。
Ceph client 根据上面的第(2)步计算出该object将要在的PG的ID。
Ceph client 再根据CRUSH算法计算出 PG 中目标主和备OSD的ID,即可对OSD的数据进行读写。
3.客户端开始对主OSD进行读写请求(副本池IO),如果发生了写操作,会有ceph服务端完成对象从主OSD到备份OSD的同步。 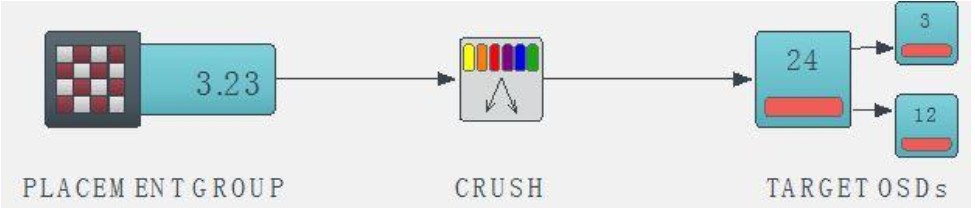
1.3、存储池的删除
如果把存储池删除会导致把存储池内的数据全部删除, 因此 ceph 为了防止误删除存储池设置了两个机制来防止误删除操作。
第一个机制是 NODELETE 标志, 需要设置为 false 但是默认就是 false 了。
#创建一个测试pool
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create mypool2 32 32 pool 'mypool2' created cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool2 nodelete nodelete: false 如果设置为了 true 就表示不能删除, 可以使用 set 指令重新设置为 fasle
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool2 nodelete true set pool 10 nodelete to true cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool2 nodelete nodelete: true cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool2 nodelete false set pool 10 nodelete to false cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool2 nodelete nodelete: false cephadmin@ceph-deploy:~/ceph-cluster$
第二个机制是集群范围的配置参数mon allow pool delete,默认值为false,即监视器不允许删除存储池,可以在特定场合使用tell指令临时设置为(true)允许删除,在删除指定的 pool之后再重新设置为 false。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool rm mypool2 mypool2 --yes-i-really-really-mean-it Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool cephadmin@ceph-deploy:~/ceph-cluster$ ceph tell mon.* injectargs --mon-allow-pool-delete=true mon.ceph-mon1: {} mon.ceph-mon1: mon_allow_pool_delete = 'true' mon.ceph-mon2: {} mon.ceph-mon2: mon_allow_pool_delete = 'true' mon.ceph-mon3: {} mon.ceph-mon3: mon_allow_pool_delete = 'true' cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool rm mypool2 mypool2 --yes-i-really-really-mean-it pool 'mypool2' removed cephadmin@ceph-deploy:~/ceph-cluster$ ceph tell mon.* injectargs --mon-allow-pool-delete=false mon.ceph-mon1: {} mon.ceph-mon1: mon_allow_pool_delete = 'false' mon.ceph-mon2: {} mon.ceph-mon2: mon_allow_pool_delete = 'false' mon.ceph-mon3: {} mon.ceph-mon3: mon_allow_pool_delete = 'false' cephadmin@ceph-deploy:~/ceph-cluster$
存储池配额
存储池可以设置两个配对存储的对象进行限制,一个配额是最大空间(max_bytes),另外一个配额是对象最大数量(max_objects)。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create mypool 32 32 pool 'mypool' created cephadmin@ceph-deploy:~/ceph-cluster$ ceph df --- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 900 GiB 900 GiB 259 MiB 259 MiB 0.03 TOTAL 900 GiB 900 GiB 259 MiB 259 MiB 0.03 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL device_health_metrics 1 1 0 B 0 0 B 0 285 GiB myrbd1 2 64 10 MiB 18 31 MiB 0 285 GiB .rgw.root 3 32 1.3 KiB 4 48 KiB 0 285 GiB default.rgw.log 4 32 3.6 KiB 177 408 KiB 0 285 GiB default.rgw.control 5 32 0 B 8 0 B 0 285 GiB default.rgw.meta 6 8 0 B 0 0 B 0 285 GiB cephfs-metadata 7 32 31 KiB 23 192 KiB 0 285 GiB cephfs-data 8 64 373 KiB 1 1.1 MiB 0 285 GiB erasure-testpool 9 16 32 KiB 1 48 KiB 0 570 GiB mypool 12 32 0 B 0 0 B 0 285 GiB cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get-quota mypool quotas for pool 'mypool': max objects: N/A #默认不限制对象数量 max bytes : N/A #默认不限制空间大小
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set-quota mypool max_objects 1000 set-quota max_objects = 1000 for pool mypool cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set-quota mypool max_bytes 10737418240 set-quota max_bytes = 10737418240 for pool mypool cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get-quota mypool quotas for pool 'mypool': max objects: 1k objects (current num objects: 0 objects) #最多 1000 对象 max bytes : 10 GiB (current num bytes: 0 bytes)#最大 10G 空间 cephadmin@ceph-deploy:~/ceph-cluster$
存储池可用参数
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool size #size:存储池中的对象副本数,默认一主两个备 3 副本。 size: 3 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool min_size min_size: 2 cephadmin@ceph-deploy:~/ceph-cluster$ min_size:提供服务所需要的最小副本数,如果定义size为3,min_size也为3,坏掉一个OSD,如果pool池中有副本在此块OSD上面,那么此pool将不提供服务,如果将min_size定义为2,那么还可以提供服务,如果提供为1,表示只要有一块副本都提供服务。
cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool pg_num #查看当前PG数量 pg_num: 32 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool pgp_num #查看当前PGP数量 pgp_num: 32 cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool crush_rule crush_rule: replicated_rule ##默认为副本池 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool nodelete #nodelete: 控制是否可删除, 默认可以 nodelete: false cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool nopgchange #nopgchange: 控制是否可更改存储池的 pg num 和 pgp num nopgchange: false cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool pg_num 64 #修改指定 pool 的 pg 数量 set pool 12 pg_num to 64 cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool nosizechange #nosizechange: 控制是否可以更改存储池的大小 nosizechange: false cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get-quota mypool quotas for pool 'mypool': max objects: 1k objects (current num objects: 0 objects) max bytes : 10 GiB (current num bytes: 0 bytes) cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set-quota mypool max_bytes 21474836480 set-quota max_bytes = 21474836480 for pool mypool cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set-quota mypool max_objects 1000 set-quota max_objects = 1000 for pool mypool cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get-quota mypool quotas for pool 'mypool': max objects: 1k objects (current num objects: 0 objects) max bytes : 20 GiB (current num bytes: 0 bytes) cephadmin@ceph-deploy:~/ceph-cluster$
noscrub 和 nodeep-scrub: 控制是否不进行轻量扫描或是否深层扫描存储池, 可临时解决高 I/O 问题
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool noscrub noscrub: false ##查看当前是否关闭轻量扫描数据, 默认为不关闭, 即开启 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool noscrub true set pool 12 noscrub to true #可以修改某个指定的 pool 的轻量级扫描测量为 true,即不执行轻量级扫描 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool noscrub noscrub: true ##再次查看就不进行轻量级扫描了 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool nodeep-scrub nodeep-scrub: false ##查看当前是否关闭深度扫描数据, 默认为不关闭, 即开启 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool nodeep-scrub true set pool 12 nodeep-scrub to true #可以修改某个指定的 pool 的深度扫描测量为 true, 即不执行深度扫描 cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool nodeep-scrub nodeep-scrub: true #再次查看就不执行深度扫描了
scrub_min_interval:集群存储池的最小清理时间间隔,默认值没有设置,可以通过配置文件中的 osd_scrub_min_interval 参数指定间隔时间。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool scrub_min_interval Error ENOENT: option 'scrub_min_interval' is not set on pool 'mypool'
scrub_max_interval:整理存储池的最大清理时间间隔,默认值没有设置,可以通过配置文件中的osd_scrub_max_interval参数指定。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool scrub_max_interval Error ENOENT: option 'scrub_max_interval' is not set on pool 'mypool'
deep_scrub_interval:深层整理存储池的时间间隔,默认值没有设置,可以通过配置文件中的osd_deep_scrub_interval参数指定。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool deep_scrub_interval Error ENOENT: option 'deep_scrub_interval' is not set on pool 'mypool' cephadmin@ceph-deploy:~/ceph-cluster$
ceph node 的默认配置
[root@ceph-node1 ~]# ll -h /var/run/ceph/ total 0 drwxrwx--- 2 ceph ceph 100 Oct 7 09:41 ./ drwxr-xr-x 30 root root 900 Oct 7 16:11 ../ srwxr-xr-x 1 ceph ceph 0 Oct 7 09:41 ceph-osd.0.asok= srwxr-xr-x 1 ceph ceph 0 Oct 7 09:41 ceph-osd.1.asok= srwxr-xr-x 1 ceph ceph 0 Oct 7 09:41 ceph-osd.2.asok= [root@ceph-node1 ~]# ceph daemon osd.0 config show | grep scrub "mds_max_scrub_ops_in_progress": "5", "mon_scrub_inject_crc_mismatch": "0.000000", "mon_scrub_inject_missing_keys": "0.000000", "mon_scrub_interval": "86400", "mon_scrub_max_keys": "100", "mon_scrub_timeout": "300", "mon_warn_pg_not_deep_scrubbed_ratio": "0.750000", "mon_warn_pg_not_scrubbed_ratio": "0.500000", "osd_debug_deep_scrub_sleep": "0.000000", "osd_deep_scrub_interval": "604800.000000", ##定义深度清洗间隔, 604800 秒=7天 "osd_deep_scrub_keys": "1024", "osd_deep_scrub_large_omap_object_key_threshold": "200000", "osd_deep_scrub_large_omap_object_value_sum_threshold": "1073741824", "osd_deep_scrub_randomize_ratio": "0.150000", "osd_deep_scrub_stride": "524288", "osd_deep_scrub_update_digest_min_age": "7200", "osd_max_scrubs": "1", #定义一个 ceph OSD daemon 内能够同时进行 scrubbing的操作数 "osd_requested_scrub_priority": "120", "osd_scrub_auto_repair": "false", "osd_scrub_auto_repair_num_errors": "5", "osd_scrub_backoff_ratio": "0.660000", "osd_scrub_begin_hour": "0", "osd_scrub_begin_week_day": "0", "osd_scrub_chunk_max": "25", "osd_scrub_chunk_min": "5", "osd_scrub_cost": "52428800", "osd_scrub_during_recovery": "false", "osd_scrub_end_hour": "0", "osd_scrub_end_week_day": "0", "osd_scrub_extended_sleep": "0.000000", "osd_scrub_interval_randomize_ratio": "0.500000", "osd_scrub_invalid_stats": "true", #定义 scrub 是否有效 "osd_scrub_load_threshold": "0.500000", "osd_scrub_max_interval": "604800.000000", #定义最大执行 scrub 间隔, 604800秒=7 天 "osd_scrub_max_preemptions": "5", "osd_scrub_min_interval": "86400.000000", #定义最小执行普通 scrub 间隔, 86400秒=1 天 "osd_scrub_priority": "5", "osd_scrub_sleep": "0.000000", [root@ceph-node1 ~]#
1.4、存储池快照
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool ls device_health_metrics myrbd1 .rgw.root default.rgw.log default.rgw.control default.rgw.meta cephfs-metadata cephfs-data erasure-testpool mypool cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool mksnap mypool mypool-snap #创建快照方法一 created pool mypool snap mypool-snap cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ rados -p mypool mksnap mypool-snap2 #创建快照方法二 created pool mypool snap mypool-snap2 cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ rados lssnap -p mypool #查看快照 1 mypool-snap 2022.10.07 17:01:06 2 mypool-snap2 2022.10.07 17:01:21 2 snaps cephadmin@ceph-deploy:~/ceph-cluster$
回滚快照
测试上传文件后创建快照, 然后删除文件再还原文件,基于对象还原。
cephadmin@ceph-deploy:~/ceph-cluster$ rados -p mypool put testfile /etc/hosts #上传文件 cephadmin@ceph-deploy:~/ceph-cluster$ rados -p mypool ls #查看上传文件 testfile cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ rados -p mypool put testfile2 /etc/passwd #上传文件 cephadmin@ceph-deploy:~/ceph-cluster$ rados -p mypool ls 查看上传文件 testfile2 testfile cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool mksnap mypool mypool-snapshot001 #创建快照 created pool mypool snap mypool-snapshot001 cephadmin@ceph-deploy:~/ceph-cluster$ rados lssnap -p mypool #查看快照 1 mypool-snap 2022.10.07 17:01:06 2 mypool-snap2 2022.10.07 17:01:21 3 mypool-snapshot001 2022.10.07 17:13:47 3 snaps cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ rados -p mypool rm testfile #删除文件 cephadmin@ceph-deploy:~/ceph-cluster$ rados -p mypool rm testfile #再次删除文件,提示文件不存在 error removing mypool>testfile: (2) No such file or directory cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$ rados rollback -p mypool testfile mypool-snapshot001 #通过快照还原某个文件 rolled back pool mypool to snapshot mypool-snapshot001 cephadmin@ceph-deploy:~/ceph-cluster$ rados -p mypool rm testfile #再次删除,可以执行成功 cephadmin@ceph-deploy:~/ceph-cluster$
删除快照
cephadmin@ceph-deploy:~/ceph-cluster$ rados lssnap -p mypool 1 mypool-snap 2022.10.07 17:01:06 2 mypool-snap2 2022.10.07 17:01:21 3 mypool-snapshot001 2022.10.07 17:13:47 3 snaps cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool rmsnap mypool mypool-snap removed pool mypool snap mypool-snap cephadmin@ceph-deploy:~/ceph-cluster$ rados lssnap -p mypool 2 mypool-snap2 2022.10.07 17:01:21 3 mypool-snapshot001 2022.10.07 17:13:47 2 snaps cephadmin@ceph-deploy:~/ceph-cluster$
1.5、数据压缩
如果使用bulestore存储引擎,ceph 支持称为”实时数据压缩”即边压缩边保存数据的功能,该功能有助于节省磁盘空间,可以在BlueStore OSD上创建的每个Ceph池上启用或禁用压缩,以节约磁盘空间,默认没有开启压缩,需要后期配置并开启。
启用压缩并指定压缩算法:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool compression_algorithm snappy set pool 12 compression_algorithm to snappy #默认算法为 snappy cephadmin@ceph-deploy:~/ceph-cluster$
snappy:该配置为指定压缩使用的算法默认为sanppy,还有none、zlib、lz4、zstd和snappy等算法,zstd压缩比好,但消耗CPU,lz4和snappy对CPU占用较低,不建议使用zlib。
指定压缩模式
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool compression_mode aggressive set pool 12 compression_mode to aggressive cephadmin@ceph-deploy:~/ceph-cluster$
- aggressive:压缩的模式,有none、aggressive、passive和force,默认none。
- none:从不压缩数据。
- passive:除非写操作具有可压缩的提示集,否则不要压缩数据。
- aggressive:压缩数据,除非写操作具有不可压缩的提示集。
- force:无论如何都尝试压缩数据,即使客户端暗示数据不可压缩也会压缩,也就是在所有情况下都使用压缩。
存储池压缩设置参数:
- compression_algorithm #压缩算法
- compression_mode #压缩模式
- compression_required_ratio #压缩后与压缩前的压缩比,默认为.875
- compression_max_blob_size:#大于此的块在被压缩之前被分解成更小的blob(块),此设置将覆盖bluestore压缩 max blob的全局设置。
- compression_min_blob_size:#小于此的块不压缩,此设置将覆盖bluestore压缩 min blob的全局设置。
全局压缩选项, 这些可以配置到 ceph.conf 配置文件, 作用于所有存储池:
- bluestore_compression_algorithm #压缩算法
- bluestore_compression_mode #压缩模式
- bluestore_compression_required_ratio #压缩后与压缩前的压缩比, 默认为.875
- bluestore_compression_min_blob_size #小于它的块不会被压缩,默认 0
- bluestore_compression_max_blob_size #大于它的块在压缩前会被拆成更小的块,默认 0
- bluestore_compression_min_blob_size_ssd #默认 8k
- bluestore_compression_max_blob_size_ssd 默认 64k
- bluestore_compression_min_blob_size_hdd #默认 128k
- bluestore_compression_max_blob_size_hdd #默认 512k
在node验证
[root@ceph-node1 ~]# ceph daemon osd.1 config show | grep compression "bluestore_compression_algorithm": "snappy", "bluestore_compression_max_blob_size": "0", "bluestore_compression_max_blob_size_hdd": "65536", "bluestore_compression_max_blob_size_ssd": "65536", "bluestore_compression_min_blob_size": "0", "bluestore_compression_min_blob_size_hdd": "8192", "bluestore_compression_min_blob_size_ssd": "8192", "bluestore_compression_mode": "none", "bluestore_compression_required_ratio": "0.875000", "bluestore_rocksdb_options": "compression=kNoCompression,max_write_buffer_number=4,min_write_buffer_number_to_merge=1,recycle_log_file_num=4,write_buffer_size=268435456,writable_file_max_buffer_size=0,compaction_readahead_size=2097152,max_background_compactions=2,max_total_wal_size=1073741824", "filestore_rocksdb_options": "max_background_jobs=10,compaction_readahead_size=2097152,compression=kNoCompression", "kstore_rocksdb_options": "compression=kNoCompression", "leveldb_compression": "true", "mon_rocksdb_options": "write_buffer_size=33554432,compression=kNoCompression,level_compaction_dynamic_level_bytes=true", "rbd_compression_hint": "none", [root@ceph-node1 ~]#
修改压缩算法
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool compression_algorithm snappy set pool 12 compression_algorithm to snappy cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool compression_algorithm compression_algorithm: snappy cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:~/ceph-cluster$
修改压缩模式
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool set mypool compression_mode passive set pool 12 compression_mode to passive cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool get mypool compression_mode compression_mode: passive cephadmin@ceph-deploy:~/ceph-cluster$

