
docker的namespace和cgroup基础知识
Docker是使用容器container的平台,容器其实只是一个隔离的进程,除此之外啥都没有。这个进程包含一些封装特性,以便和主机还有其他的容器隔离开。一个容器依赖最多的是它的文件系统也就是image,image提供了容器运行的一切包括 code or binary, runtimes, dependencies, and 其他 filesystem 需要的对象。
容器在Linux上本地运行,并与其他容器共享主机的内核。它运行一个独立的进程,占用的内存不比其他的filesystem多,因此它是轻量级的。相比之下,虚拟机(VM)运行一个成熟的“guest”操作系统,通过hypervisor对主机资源进行虚拟访问。一般来说,vm会产生大量开销,超出应用程序逻辑所消耗的开销。
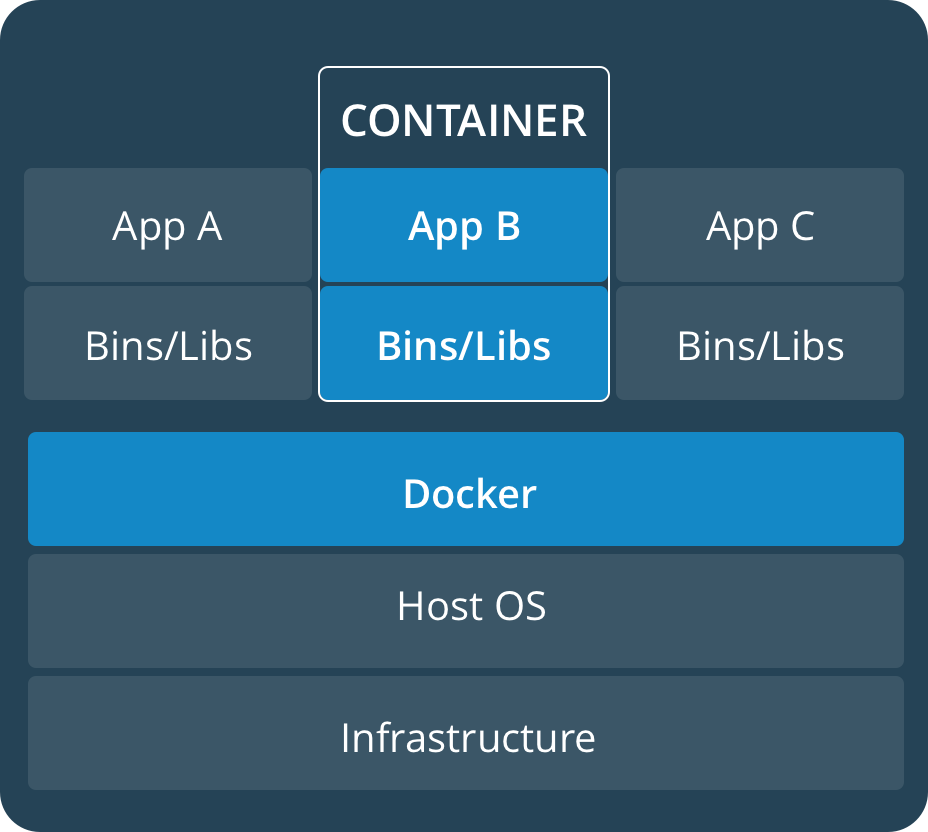
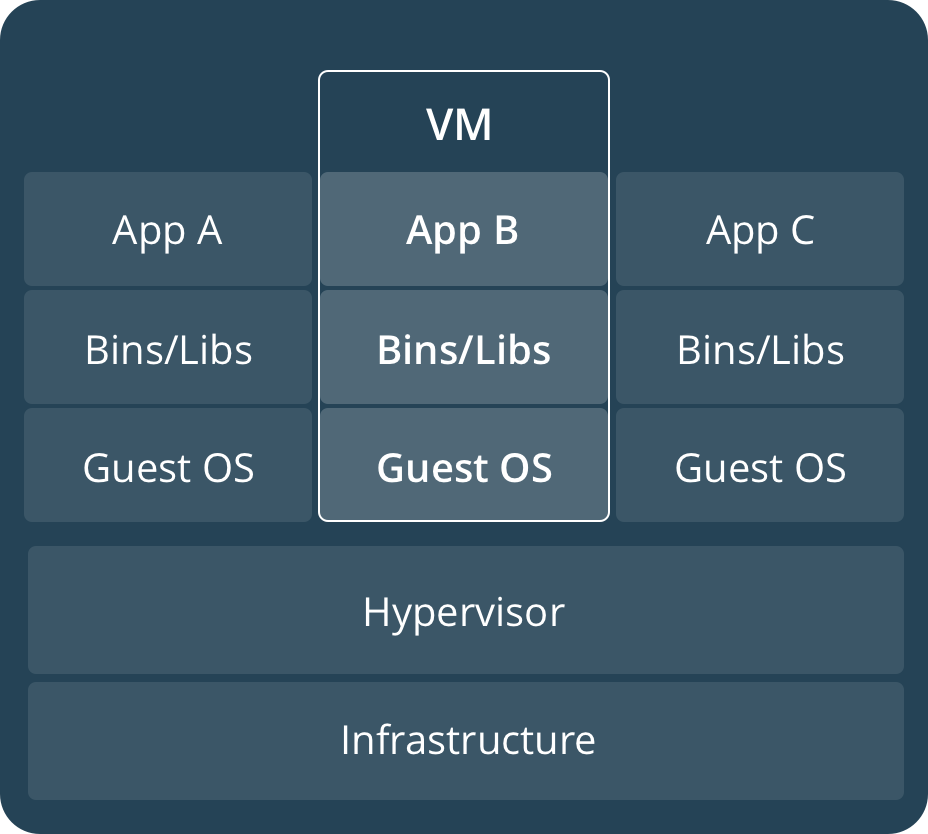
容器本质上是把系统中为同一个业务目标服务的相关进程合成一组,放在一个叫做namespace的空间中,同一个namespace中的进程能够互相通信,但看不见其他namespace中的进程。每个namespace可以拥有自己独立的主机名、进程ID系统、IPC、网络、文件系统、用户等等资源。在某种程度上,实现了一个简单的虚拟:让一个主机上可以同时运行多个互不感知的系统。 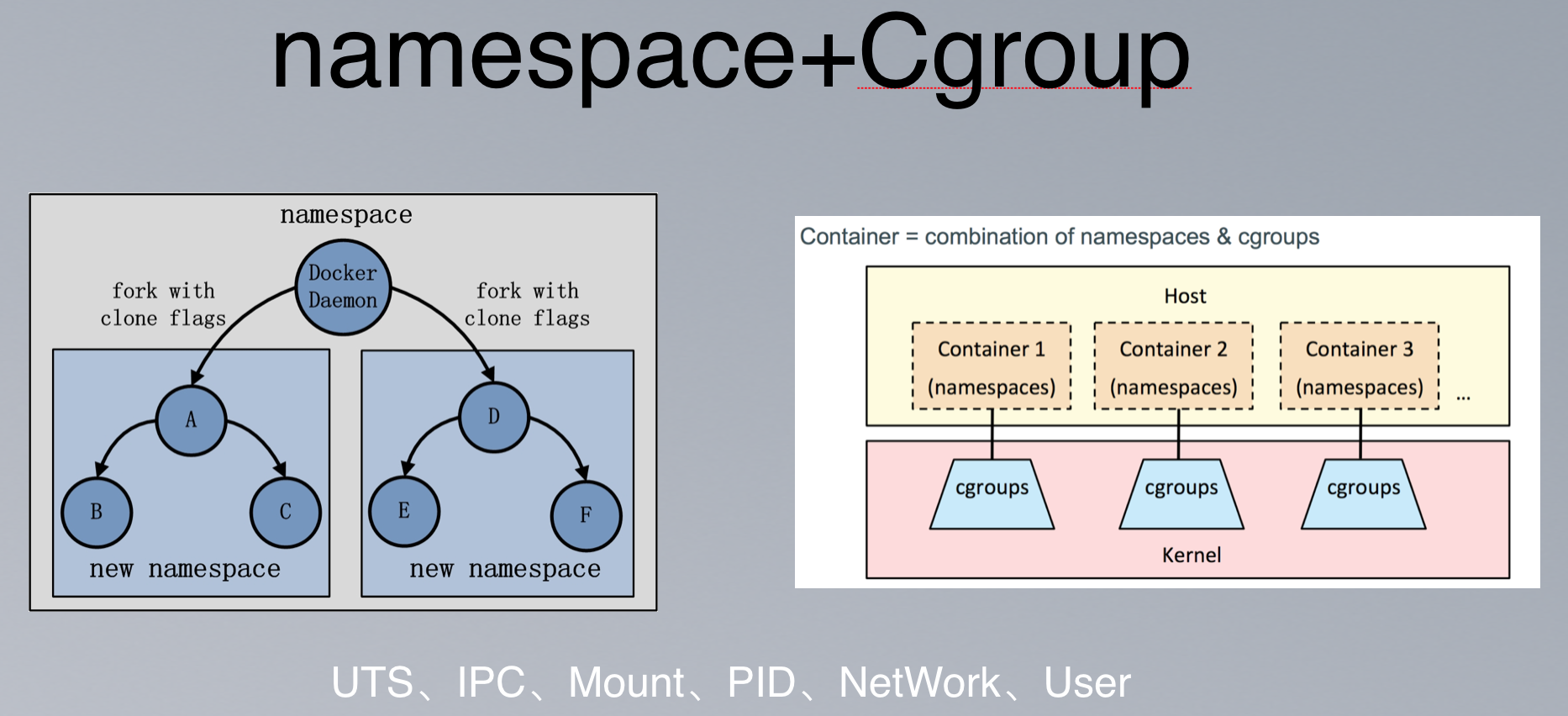
此外,为了限制namespace对物理资源的使用,对进程能使用的CPU、内存等资源需要做一定的限制。这就是Cgroup技术,Cgroup是Control group的意思。比如我们常说的4c4g的容器,实际上是限制这个容器namespace中所用的进程,最多能够使用4核的计算资源和4GB的内存。
简而言之,Linux内核提供namespace完成隔离,Cgroup完成资源限制。namespace+Cgroup构成了容器的底层技术(rootfs是容器文件系统层技术)。
namespace
一个namespace把一些全局系统资源封装成一个抽象体,该抽象体对于本namespace中的进程来说有它们自己的隔离的全局资源实例。改变这些全局资源对于该namespace中的进程是可见的,而对其他进程来说是不可见的。
Linux 提供一下几种 namespaces:
Namespace Constant Isolates - IPC CLONE_NEWIPC System V IPC, POSIX message queues 进程间通信隔离 - Network CLONE_NEWNET Network devices, stacks, ports, etc. 隔离网络资源 - Mount CLONE_NEWNS Mount points 隔离文件系统 - PID CLONE_NEWPID Process IDs 进程隔离 - User CLONE_NEWUSER User and group IDs 隔离用户权限 - UTS CLONE_NEWUTS Hostname and NIS domain name (UNIX Time Sharing)用来隔离系统的hostname以及NIS domain name
为了在分布式的环境下进行通信和定位,容器必然需要一个独立的IP、端口、路由等等,自然就想到了网络的隔离。同时,你的容器还需要一个独立的主机名以便在网络中标识自己。想到网络,顺其自然就想到通信,也就想到了进程间通信的隔离。可能你也想到了权限的问题,对用户和用户组的隔离就实现了用户权限的隔离。最后,运行在容器中的应用需要有自己的PID,自然也需要与宿主机中的PID进行隔离。
Linux内核为以上6种namespace隔离提供了系统调用,具体就是namespacede API包括clone()、setns()以及unshare(),还有/proc下的部分文件。为了确定隔离的到底是哪6项namespace,在使用这些API时,通常需要指定CLONE_NEWNS、CLONE_IPC、CLONE_NEWNET、CLONE_NEWPID、CLONE_USER和CLONE_UTS. 其中CLONE_NEWNS是mount,因为它是第一个linux namespace所以标识位比较特殊。
cgroups
Cgroups是control groups的缩写,最初由google的工程师提出,后来被整合进Linux内核。Cgroups是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:CPU、内存、IO等)的机制。对开发者来说,cgroups 有如下四个有趣的特点:
- cgroups 的 API 以一个伪文件系统的方式实现,即用户可以通过文件操作实现 cgroups 的组织管理。
- cgroups 的组织管理操作单元可以细粒度到线程级别,用户态代码也可以针对系统分配的资源创建和销毁 cgroups,从而实现资源再分配和管理。
- 所有资源管理的功能都以“subsystem(子系统)”的方式实现,接口统一。
- 子进程创建之初与其父进程处于同一个 cgroups 的控制组。
本质上来说,cgroups 是内核附加在程序上的一系列钩子(hooks),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。实现 cgroups 的主要目的是为不同用户层面的资源管理,提供一个统一化的接口。从单个进程的资源控制到操作系统层面的虚拟化。Cgroups 提供了以下四大功能:
- 资源限制(Resource Limitation):cgroups 可以对进程组使用的资源总额进行限制。如设定应用运行时使用内存的上限,一旦超过这个配额就发出 OOM(Out of Memory)。
- 优先级分配(Prioritization):通过分配的 CPU 时间片数量及硬盘 IO 带宽大小,实际上就相当于控制了进程运行的优先级。
- 资源统计(Accounting): cgroups 可以统计系统的资源使用量,如 CPU 使用时长、内存用量等等,这个功能非常适用于计费。
- 进程控制(Control):cgroups 可以对进程组执行挂起、恢复等操作。
Docker正是使用cgroup进行资源划分,每个容器都作为一个进程运行起来,每个业务容器都会有一个基础的pause容器也就是POD作为基础容器。pause容器提供了划分namespace的内容,并连通同一POD下的所有容器,共享网络资源。查看容器的PID,对应/proc/pid/下是该容器的运行资源,每一个文件保持打开的话,对应的namespace就会一直存在。
在分析 K8s、Docker 等 cgroup 相关操作时。比如 docker run xxx 时,可以看到 /sys/fs/cgroup/cpuset/docker/xxx/cpuset.cpus、/sys/fs/cgroup/cpuset/docker/xxx/cpuset.mems 等 cgroup 文件被打开,也可以查看 kube-proxy 在周期性刷新 cgroup 相关文件。这些都是资源划分相关文件。 可以通过cat /proc/mount来查看 cgroups 挂载的目录,一般在 /sys/fs/cgroup。
参考文档:https://www.cnblogs.com/janeysj/p/11274515.html

