索引与慢查询优化
索引在mysql中也叫键,是存储引擎用于快速找到记录的一种数据结构
primary key
unique key
index key
注意:外键(foreign key)不是用来加速查询的,以上的三种key都是用来加速查询的,还具有额外的约束条件(primary key:非空且唯一,unique key:唯一),index key没有任何约束功能,只能iasu查询
索引是一种数据结构,类似于书的目录。
本质 :通过不断缩小想要的数据的范围来筛选出最终的结果,同时把随机的事件变成 顺序的事件,即我们可以通过同一种查找方式来锁定数据
索引的影响:
在表中由大量的数据的前提下,创建索引的速度会很慢
在索引创建完毕后,对表的查询性能会大幅度提升但是写的性能会降低。
b+树
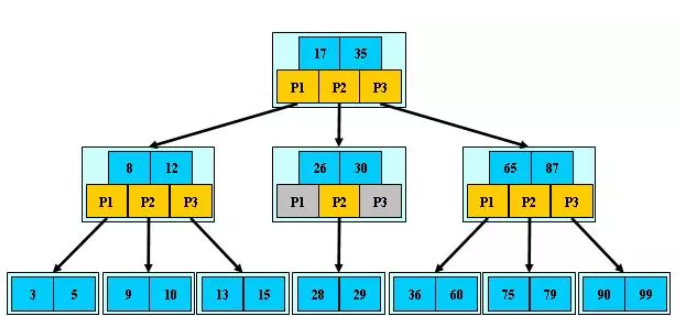
只有叶子节点是真实数据,根与树枝节点存的是虚拟数据
查询的次数由树的层数决定,层数越低次数越少
聚集索引(primary key)
所谓聚集索引就是主键,innodb引擎规定一张表里必须要有主键
特点:叶子节点存放的是一条完整的记录
辅助索引(unique,index)
辅助索引:查询数据时不可能只用id作为筛选条件,为此需要给其他字段建立索引,这些索引就是辅助索引
特点:叶子节点存放的是辅助索引字段对应的那条记录的主键值
栗子:
#1.准备表
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2.创建存储过程,实现批量插入记录
delimiter $$ #声明存储过程的结束符号为$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<30)do
insert into s1 values(i,'jason','male',concat('jason',i,'@oldboy'));
set i=i+1;
end while;
END$$ #$$结束
delimiter ; #重新声明分号为结束符号
#3.查看存储过程
show create procedure auto_insert1\G
#4.调用存储过程
call auto_insert1();
#5.表没有任何索引的情况下
select * from s1 where id=30000;
#6.避免打印带来的时间损耗
select count(id) from s1 where id = 30000;
select count(id) from s1 where id = 1;
#7.给id做一个主键
alter table s1 add primary key(id); # 速度很慢
select count(id) from s1 where id = 1; # 速度相较于未建索引之前两者差着数量级
select count(id) from s1 where name = 'jason' # 速度仍然很慢
"""
范围问题
"""
# 并不是加了索引,以后查询的时候按照这个字段速度就一定快
select count(id) from s1 where id > 1; # 速度相较于id = 1慢了很多
select count(id) from s1 where id >1 and id < 3;
select count(id) from s1 where id > 1 and id < 10000;
select count(id) from s1 where id != 3;
alter table s1 drop primary key; # 删除主键 单独再来研究name字段
select count(id) from s1 where name = 'jason'; # 又慢了
create index idx_name on s1(name); # 给s1表的name字段创建索引
select count(id) from s1 where name = 'jason'