
hadoop集群搭建(docker)
1.准备安装包(hadoop-3.3.2.tar.gz和jdk-8u371-linux-x64.tar.gz)
2.创建Dockerfile文件:
# 镜像源 FROM centos:7 # 添加元数据 LABEL author="作者" date="2023/05/30" # 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no RUN yum install -y openssh-server sudo RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config # 安装openssh-clients RUN yum install -y openssh-clients # 安装which RUN yum install -y which # 添加测试用户root,密码root,并且将此用户添加到sudoers RUN echo "root:root" | chpasswd RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key #启动sshd服务并且暴露22端口 RUN mkdir /var/run/sshd EXPOSE 22 # 拷贝并解压jdk ADD jdk-8u371-linux-x64.tar.gz /usr/local/ RUN mv /usr/local/jdk1.8.0_371 /usr/local/jdk1.8 ENV JAVA_HOME /usr/local/jdk1.8 ENV PATH $JAVA_HOME/bin:$PATH # 拷贝并解压hadoop ADD hadoop-3.3.2.tar.gz /usr/local RUN mv /usr/local/hadoop-3.3.2 /usr/local/hadoop ENV HADOOP_HOME /usr/local/hadoop ENV PATH $HADOOP_HOME/bin:$PATH
ENV LANG="en_US.utf8" # 设置容器启动命令 CMD ["/usr/sbin/sshd", "-D"]
3.构建并配置镜像
hadoop和jdk安装包要和Dockerfile文件放在同一目录,然后构建镜像
docker build -t hadoop-test .
构建容器:
docker run -d --name hadoop-test hadoop-test
进入容器:
docker exec -it hadoop-test bash
切换到hadoop配置目录:
cd /usr/local/hadoop/etc/hadoop/
配置hadoop环境变量:
vi hadoop-env.sh
追加以下内容:
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export JAVA_HOME=/usr/local/jdk1.8
配置核心参数:
vi core-site.xml
添加以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<!-- default 4096(4M) -->
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<!-- unit: minute, default 0 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
配置hdfs:
vi hdfs-site.xml
添加以下内容:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
</configuration>
配置资源管理:
vi yarn-site.xml
添加以下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
</configuration>
配置分布式计算:
vi mapred-site.xml
添加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
配置子节点:
vi workers
把默认的localhost改为datanode的hostname:
#localhost
slave1
slave2
退出并关闭容器:
exit
docker stop hadoop-test
把容器保存为新的镜像:
docker commit hadoop-test hadoop:base
4.搭建集群
创建network:
docker network create --subnet=192.168.0.0/24 hadoop
构建master、slave1、slave2三个容器:
docker run -d --name master --hostname master --network hadoop --ip 192.168.0.10 -P -p 8088:8088 -p 9870:9870 -p 19888:19888 hadoop:base docker run -d --name slave1 --hostname slave1 --network hadoop --ip 192.168.0.11 -P hadoop:base docker run -d --name slave2 --hostname slave2 --network hadoop --ip 192.168.0.12 -P hadoop:base
配置node免密登录:
进入master容器:
docker exec -it master bash
生成密钥,一直回车就行:
ssh-keygen
把密钥分发给其它node,需要输入yes和密码,密码是Dockerfile中配置的root:
ssh-copy-id master ssh-copy-id slave1 ssh-copy-id slave2
进入其它datanode做同样的操作。
在master容器中启动服务:
格式化hdfs(第一次需要格式化,后续不需要):
hdfs namenode -format
启动服务:
$HADOOP_HOME/sbin/start-all.sh
启动历史日志服务:
$HADOOP_HOME/bin/mapred --daemon start historyserver
查看启动的服务:
jps
如下所示:
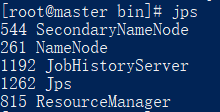
进入slave1、slave2容器,
查看启动的服务:
jps
如下所示:
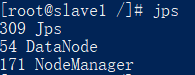
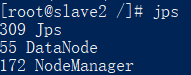
关闭服务:
$HADOOP_HOME/bin/mapred --daemon stop historyserver $HADOOP_HOME/sbin/stop-all.sh
5.hadoop测试
在master容器新建一个文件,随便输入一些内容,保存:
vi test.txt welcome hadoop
把文件保存到hdfs根目录:
hdfs dfs -put test.txt /
查看hdfs根目录:
hadoop fs -ls /
可以看到以下内容:

也可以访问浏览器页面localhost:9870,如下所示:
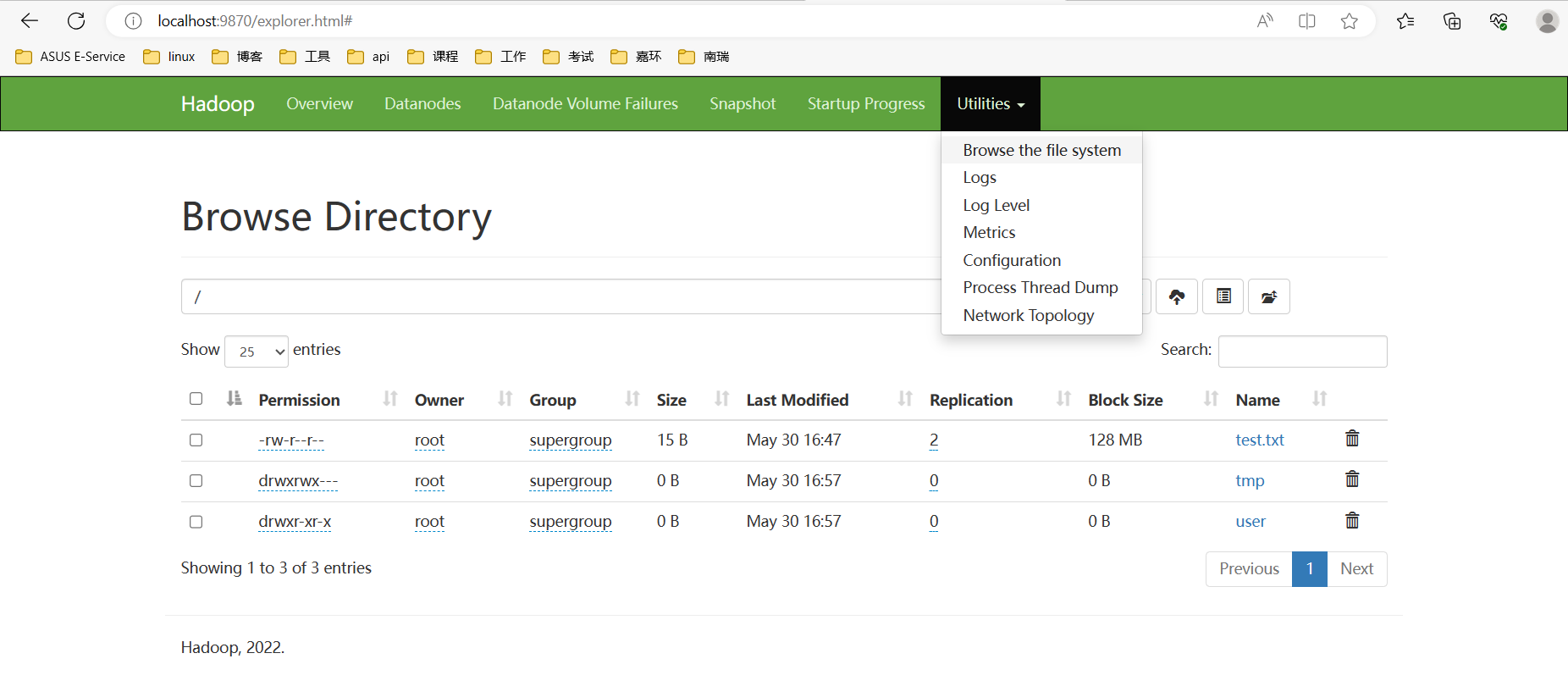
mapreduce服务测试:
切换到hadoop计算样例目录:
cd $HADOOP_HOME/share/hadoop/mapreduce
运行测试样例,调用jar包计算pi的值,计算100次:
hadoop jar hadoop-mapreduce-examples-3.3.2.jar pi 3 100
可以通过浏览器页面localhost:8088查看任务情况和日志等。
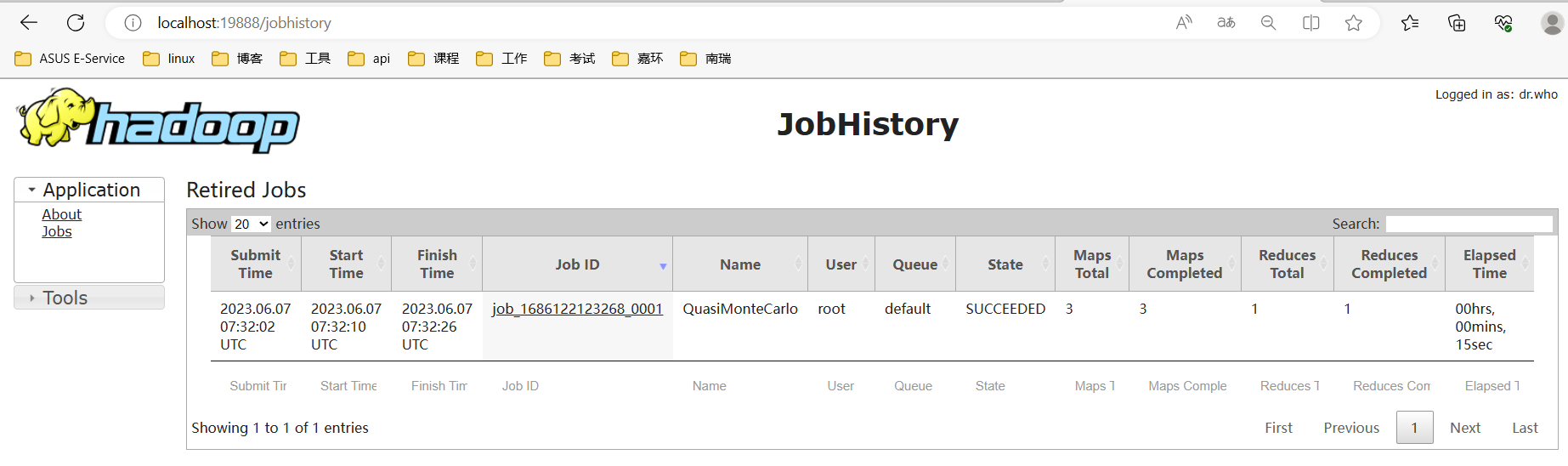
运行完的任务可以到浏览器页面localhost:19888查看,如下所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号