
python requests 网页编码问题
简介:不同的服务器采用的网页编码可能不一样,如果使用错误的编码发送数据,将不会得到正确的数据。
目的:识别访问网页的编码,发送正确的编码数据和解码。
参考链接:
Python+request:根据四种不同的提交数据方式进行post请求
Python 爬虫 (requests) 发送中文编码的 HTTP POST 请求
1、http请求编码的大致过程
浏览器->提交数据->数据编码->服务器->反编码->后台处理数据->反馈数据->编码数据->浏览器接受数据->解码数据->显示
2、网页编码的识别方式
在网页的<head>的<meta>标签里面,一般会有注释。
url = 'https://www.ip138.com/post/' # <meta charset="gb2312">
对于返回的数据编码,可以通过response.headers的content-type属性获得。如果返回的response中没有的话,则一般为网页中的编码。

3、实例测试--访问一个gbk编码的网站
初始化。
url = 'https://www.ip138.com/post/' # <meta charset="gb2312"> headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36', } req = requests.Session() req.headers.update(headers) r = req.get(url) data = { 'area':'北京', 'action':'area2zone' }
requests默认为utf8编码,如果以非gbk编码访问gbk的一个查询页面,并对返回值进行utf8编码,则会造成无法正确查询,返回结果形成乱码。
如果将字典传给 requests 的 data 属性:requests 自动为数据进行编码
如果将字符串传给 requests 的 data 属性:requests 会直接发送字符串数据
url = 'https://www.ip138.com/post/search.asp' r = req.get(url,params=data) # t.text 查询乱码 status_code=200 状态码为正常 print(r.url) r.encoding = 'utf8' print(r.text) with open('utfgetgbk.html', 'wb') as f: f.write(r.content)
查询结果图:
正确的方式,应该以gbk编码方式进行访问。顺利查询。urlencode将字典对象编码为字符串。
url = 'https://www.ip138.com/post/search.asp' r = req.get(url,params=urlencode(data,encoding='gbk')) # 正常返回 t.text status_code=200 print(r.url) r.encoding = 'gb2312' with open('getgbk.html', 'wb') as f: f.write(r.content)
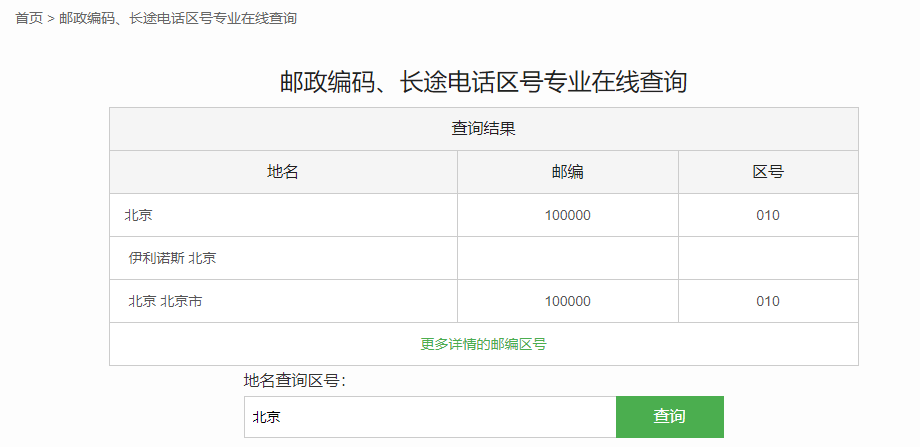
小结:
爬虫的过程中,编码的错误会造成错误。因此要对编码具有一定掌握。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号