
python pandas DataFrame 关于重复索引取值的一些坑
情况:重复索引与非重复索引的取值返回类型是不一样的。
dfa = pd.DataFrame(np.random.randn(6, 4),index=list('aacdeb'),columns=list('ABCD')) dfa
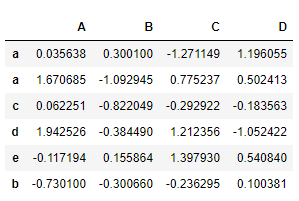
print('存在重复索引取一列的情况:',type(dfa.loc['a','A']),'取值方法:',dfa.loc['a','A'].iloc[0]) print('----------------------------------------------------------------------') print('不存在重复索引取一列的情况:',type(dfa.loc['c','A']),'取值方法:',dfa.loc['c','A']) print('----------------------------------------------------------------------') # # 如果在程序中需要通用的话,需要先转换 # 或者对返回结果类型先进行判断 # print('通用取值方法,假设多个返回取其中一个:','重复情况:',pd.Series(dfa.loc['a','A']).iloc[0]) print('通用取值方法,:','不重复情况:',pd.Series(dfa.loc['c','A']).iloc[0])
输出情况:

最终,就是要清晰,使用的数据情况,从而选择具体的取值方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号