(转)语音处理基础知识
转:https://www.cnblogs.com/mengnan/p/9465402.html
前置知识
-
激励:信号处理中的输入
-
谐振:等同于共振,不同领域的不同称谓。当电路中激励的频率等于电路的固有频率时,电路的电磁振荡的振幅也将达到峰值,这就称作谐振。参见谐振-百度百科
-
白噪声:指功率谱密度在整个频域内均匀分布的噪声。参见白噪声-百度百科
-
音素:phoneme,语音中最小的基本单位。音素是人类能区分一个单词和另一个单词的基础。音素构成音节,音节又构成不同的词和短语。音素可分为元音和辅音
-
元音:又称母音,是音素的一种。元音是在发音过程中由气流通过口腔不受阻碍的发出的音。不同的元音是由口腔不同的形状造成的。元音和共振峰关系密切
-
辅音:又称子音。辅音是气流在口腔或咽头受到阻碍而形成的音。
-
清音:发清音时声带不振动,因此清音没有周期性。清音由空气摩擦产生,在分析研究时等效为噪声。
-
浊音:发声时声带振动的产生音称为浊音。辅音有清有浊,而大多数语言中元音均为浊音,浊音具有周期性
-
发清音时声带完全舒展,发浊音时声带紧绷在气流作用下作周期性运动
-
预加重是一种在发送端对输入信号高频分量进行补偿的信号处理方式。参见预加重-百度百科
-
短时加窗处理:音频信号是动态变化的,为了能传统的方法对音频信号进行分析,假设音频信号在几十毫秒的短时间内是平稳的。为了得到短时的音频信号,要对音频信号进行加窗操作。窗函数平滑的在音频信号上滑动,将音频信号分成帧。分帧可以连续,也可以采用交叠分段的方法,交叠部分称为帧移,一般为窗长的一半。窗函数可以采用汉明窗、汉宁窗等。在时域上处理时,分帧之后处理手段的名称一般都在处理手段前加“短时”修饰。
-
发声机理
![]()
空气由肺部进入喉部,通过声带激励进入声道,最后通过嘴唇辐射形成语音。

语音信号的数字模型
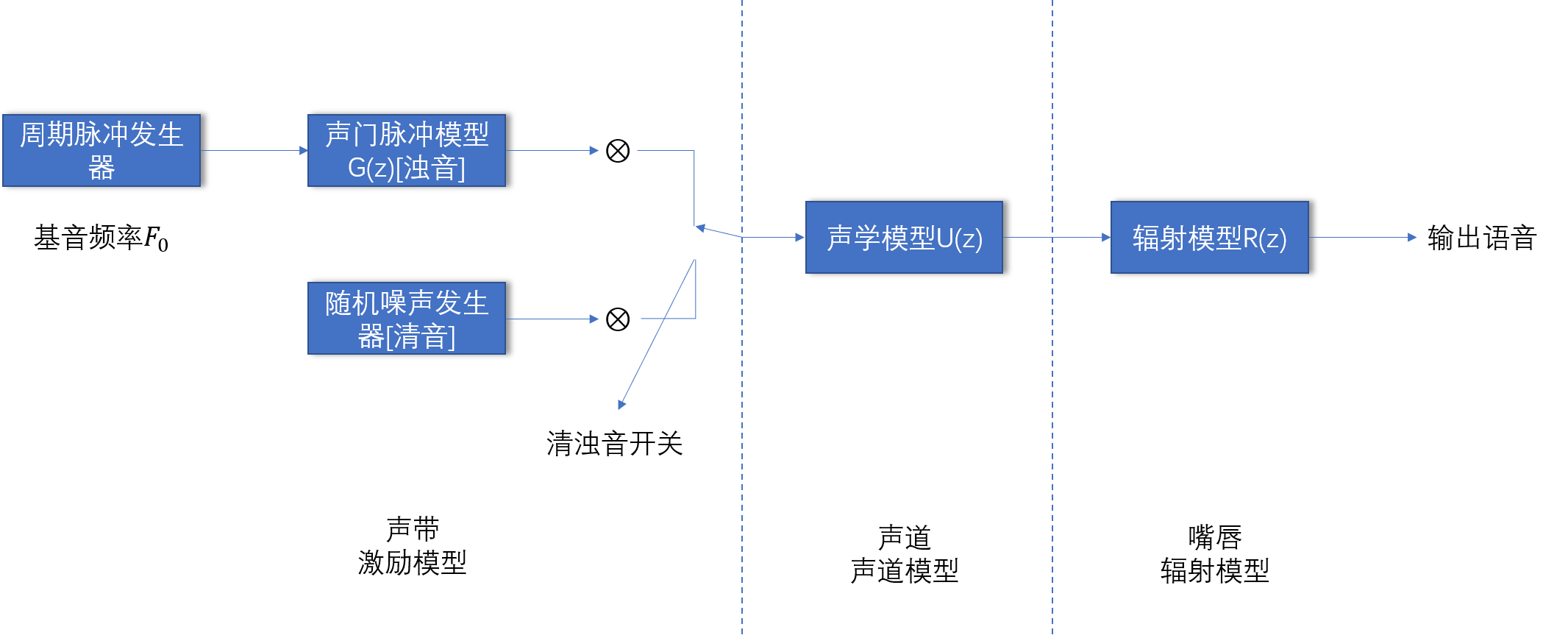
语音信号的数字模型由三部分组成:激励模型,声道模型和辐射模型
语音信号S(z)=G(z)∗U(z)∗R(z)S(z)=G(z)∗U(z)∗R(z)
激励模型:发浊声时声带不断地开启和关闭将产生间歇的脉冲波;发清音时可等效成随机白噪声。
声道模型:声道部分的数字模型分为“声管模型”(多个截面积的管子串联而形成的系统)和“共振峰模型”(将声道视为一个谐振腔)
辐射模型:辐射模型表征口和唇的辐射效应和圆形头部的绕射效应
语音特征
语音处理中,需要把音频信号中具有辨识性的成分提取出来
-
过零率
过零率体现的是信号过零点的次数,体现的是频率特性。
Zn=∑m=0N−1|sgn(xn(m))−sgn(xn(m−1))|Zn=∑m=0N−1|sgn(xn(m))−sgn(xn(m−1))|其中,sgn(x)sgn(x)为符号函数,即:
sgn(x)={1, x≥0−1, x<0sgn(x)={1, x≥0−1, x<0 -
短时能量
短时能量体现的是信号在不同时刻的强弱程度。
设第n帧语音信号xn(m)xn(m)的短时能量用EnEn表示,则其计算公式为:
En=∑m=0N−1x2n(m)En=∑m=0N−1xn2(m)其中,N为信号帧长
-
声强和声强级
单位时间内通过垂直于声波传播方向的单位面积的平均声能,称作声强,声强用II表示,单位为“瓦/平米”。实验研究表明,人对声音的强弱感觉并不是与声强成正比,而是与其对数成正比,所以一般声强用声强级来表示
L=10log[II′]=10log(II′)L=10log[II′]=10log(II′)其中,II为声强,I′=10e−12w/m2I′=10e−12w/m2称为基本声强,声强级的常用单位是分贝(dB)。
-
响度
响度是一种主观心理量,是人类主观感觉到的声音强弱程度,又称音量。响度与声强和频率有关。一般来说,声音频率一定时,声强越强,响度也越大。相同的声强,频率不同时,响度也可能不同。响度若用对数值表示,即为响度级,响度级的单位定义为方,符号为phon。根据国际协议规定,0dB声强级的1000Hz纯音的响度级定义为0 phon,n dB声强级的1000Hz纯音的响度级就是n phon。其它频率的声强级与响度级的对应关系要从等响度曲线查出。 参见响度-百度百科
-
音高
音高也是一种主观心理量,是人类听觉系统对于声音频率高低的感觉。音高的单位是美尔(Mel)。响度级为40 phon,频率为1000Hz的声音的音高定义为1000Mel。
-
谱熵
谱熵(spectral entropy)这一概念描述了功率谱和熵率之间的关系。研究表明,由自回归模型估计出的谱具有最大的谱熵,因而是一种理想的求谱方法,称为最大熵谱估计法,简称MEM,所得的谱称为最大熵谱。参见谱熵-百度百科
谱熵的定义:首先对每一帧信号的频谱绝对值归一化:
pi=Ym(fi)∑N−1k=0Ym(fk)i=1,2,...,Npi=Ym(fi)∑k=0N−1Ym(fk)i=1,2,...,N这样就得到了概率密度,进而求取熵:
Hm=−∑i=0N−1p(i)log(p(i))Hm=−∑i=0N−1p(i)log(p(i))注:“频谱”表征频率和能量之间的关系,参见频谱-百度百科及下文“梅尔频率倒谱系数MFCC”部分的相关说明。对于语音而言,“能量”正比于“振幅”,振幅越大,能量也越大。
-
共振峰
声门处的准周期激励进入声道时会引起共振特性,产生一组共振频率,这一组共振频率称为共振峰频率或简称共振峰。共振峰包含在语音的频谱包络中,频谱极大值就是共振峰。
-
基音周期和基音频率
也有称作“基频”,“基频周期”等
-
基音周期:反映了声门相邻两次开闭之间的时间间隔或开闭的频率。它是语音激励源的一个重要特征,比如可以通过基频区分性别
-
基音周期的估算方法
基音周期的估算方法很多,比较常用的有自相关法,倒谱法(提基频用的倒谱法),平均幅度差函数法,线性预测法,小波—自相关函数法,谱减—自相关函数法等。
-
自相关函数
相关函数用于测定两个信号在时域内的相似程度,可以分为互相关函数和自相关函数。互相关函数主要研究两个信号之间的相关性,如果两个信号完全不同、相互独立,那么互相关函数接近于零。自相关函数主要研究信号本身的同步性、周期性。对于离散的音频信号x(n)x(n),它的自相关函数定义如下:
R(k)=∑m=−∞+∞x(m)x(m+k)R(k)=∑m=−∞+∞x(m)x(m+k)如果信号时随机的或者周期的,这时的定义为:
R(k)=limN→∞12N+1∑m=−NNx(m)x(m+k)R(k)=limN→∞12N+1∑m=−NNx(m)x(m+k)上式表示一个信号和延迟kk点后的该信号本身的相似性。在任何一种情况下,信号的自相关函数都是描述信号特性的有效方法。
短时自相关函数是在自相关函数的基础上将信号加窗后获得的:
Rn(k)=∑m=−∞∞x(m)w(n−m)x(m+k)w(n−(m+k))=∑m=nn+N−k−1xw(m)xw(m+k)Rn(k)=∑m=−∞∞x(m)w(n−m)x(m+k)w(n−(m+k))=∑m=nn+N−k−1xw(m)xw(m+k)其中,kk为时间的延迟量,N为帧长,ww为窗函数。短时自相关函数具有以下的性质:若原信号具有周期性,则它的自相关函数也具有周期性,并且周期性与原信号的周期相同。且在时间延迟量kk等于周期整数倍时会出现峰值。
清音信号无周期性,它的自相关函数会随着kk的增大呈衰减趋势。浊音具有周期性,它的自相关函数R(k)R(k)在基音周期整数倍上具有峰值。通常取第一最大峰值点作为基音周期点。自相关函数正是利用这一性质进行基音周期检查的。
-
平均幅度差函数
短时平均幅度差函数也可以用于基音周期检查,而且计算上比短时自相关函数方法更简单。计算短时自相关函数需要很大的计算量,其原因主要是乘法运算所需的时间较长。为了避免乘法运算,可以对一个周期为PP的单纯的周期信号做差分。
d(n)=x(n)−x(n−k)d(n)=x(n)−x(n−k)其中kk为时间延迟量,时间差
则在k=0,±P,±2P,...k=0,±P,±2P,...时,上式为零。即当kk与周期信号吻合时,作为d(n)d(n)的短时平均幅度差值总是最小,因此短时平均幅度差函数的定义为:
γn(k)=∑m=nn+N−k−1|xw(m+k)−xw(m)|γn(k)=∑m=nn+N−k−1|xw(m+k)−xw(m)|对于周期性的x(n)x(n),γn(k)γn(k)也呈周期性。它的平均幅度差函数γnγn在基音周期整数倍上具有谷值。
-
-
-
梅尔频率倒谱系数MFCC
前置知识
描述声音信号的方式:参见傅里叶分析之掐死教程(完整版)更新于2014.06.06
一段音乐的描述:
![]()
这是对声音最普遍的理解,一个随着时间变化的震动。另一方面,音乐更为直观的理解是:
![]()
将上述两图简化
时域:
![]()
频域:
![]()
而贯穿时域和频域的方法之一,就是傅里叶分析。傅里叶分析可分为傅里叶级数和傅里叶变换。
![]()
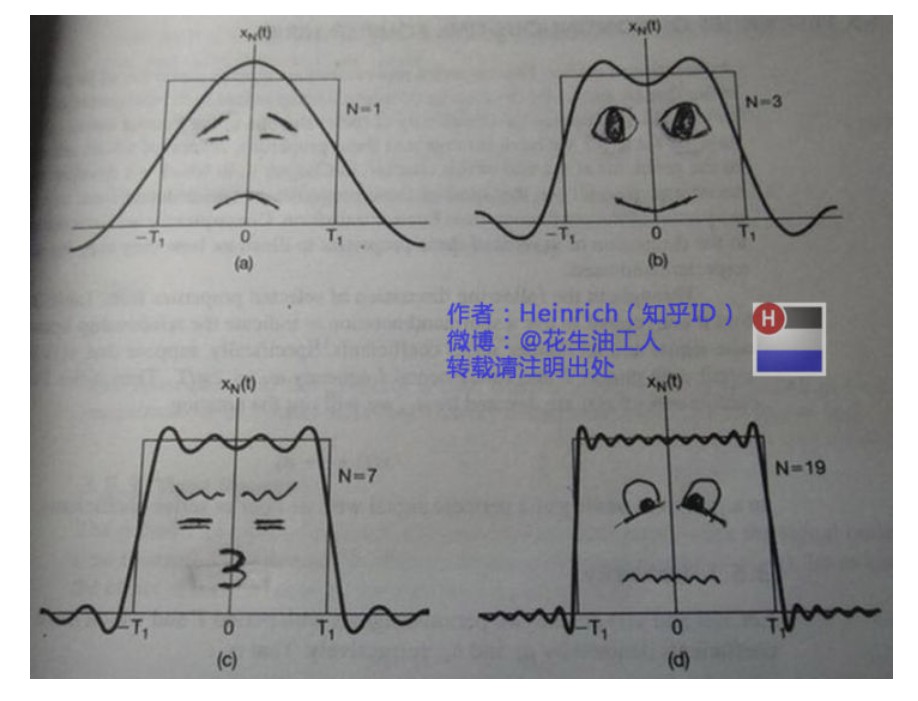
上图表示,随着正弦波数量逐渐的增长,他们最终会叠加成一个标准的矩形。
如果将第一个频率最低的频率分量看作“1”,我们就有了构建频域的最基本单元。对于我们最常见的有理数轴,数字“1”就是有理数轴的基本单元。时域的基本单元就是“1秒”,如果我们将一个角频率为w0w0的正弦波cos(w0t)cos(w0t)看作基础,那么频域的基本单元就是w0w0。有了“1”,还要有“0”才能构成完整的世界。cos(0t)cos(0t)就是一个周期无限长的正弦波,也就是一条直线。所以在频域,0频率也被称作直流分量,在傅里叶级数的叠加中,其仅仅影响全部波形相对于数轴整体向上或是向下而不改变波的形状。
下图展示了矩形波在频域中的模样:
![]()
频域图像,也就是俗称的频谱,能够切换个角度去看到:
![]()
可以看到,在频谱中,偶数项的振幅都是0,也就对应了图中的彩色直线,振幅为0的正弦波。
-
声谱图:描述语音信号
声谱图可以通过快速傅里叶变换(FFT)或者DCT(离散余弦变换)实现。FFT延展与DCT等价。
基于FFT声谱图的定义:分帧->每一帧FFT->求取FFT之后的幅度(即能量)
对每一帧语音信号FFT:
Xn(ejw)=∑m=−∞∞x(m)∗w(n−m)∗e−jwmXn(ejw)=∑m=−∞∞x(m)∗w(n−m)∗e−jwm![]()
一些声谱图示例:
![]()
![]()
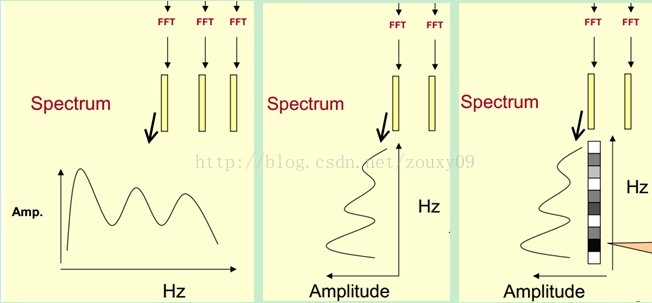
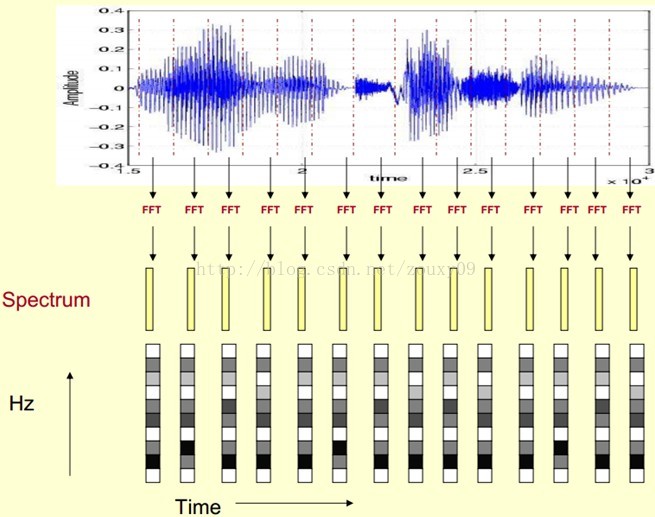
绘制过程
语音信号先被分为很多帧,每帧语音通过短时傅里叶变换,对应于一个频谱。频谱表示频率与能量的关系。如下图左,取出某一帧语音信号求频谱。
![]()
先将上上图中的一帧语音拿出,频谱通过坐标表示出来,如上图左。将左边的频谱图旋转90°,可得中间的图。然后将幅度映射到一个灰度值表示,幅度值越大,相应的区域越黑。这样就可以得到右侧的图。
这样就会得到一个随着时间变换的频谱图,这就是描述语音信号的声谱图。
![]()
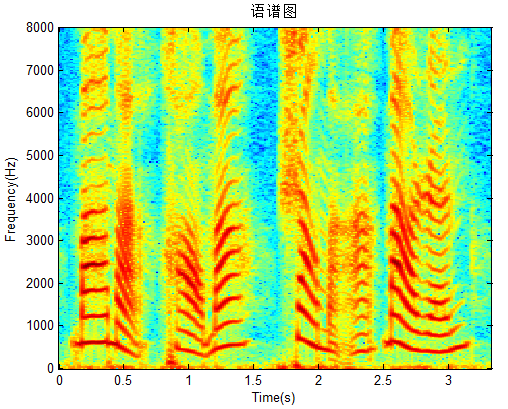
下图是一段语音的声谱图,很黑的地方就是频谱图中的峰值(共振峰)
![]()
音素的属性可以更好的在这里面观察出来。通过观察共振峰和它们的转变可以更好的识别声音。隐马尔科夫模型就是隐含的对声谱图建模以达到好的识别性能。另外,它可以直观的评估TTS系统的好坏,即:直接对比合成语音和自然语音的声谱图的匹配度。
-
倒谱分析
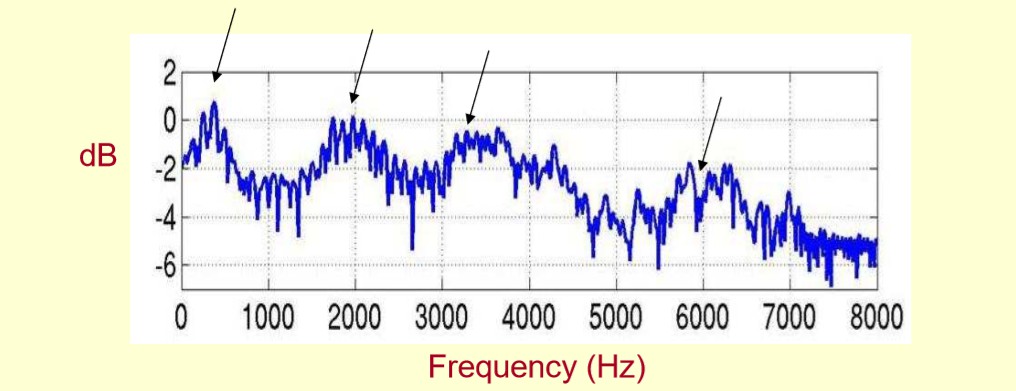
这里用到的是对数频谱,纵坐标单位就是dBdB
![]()
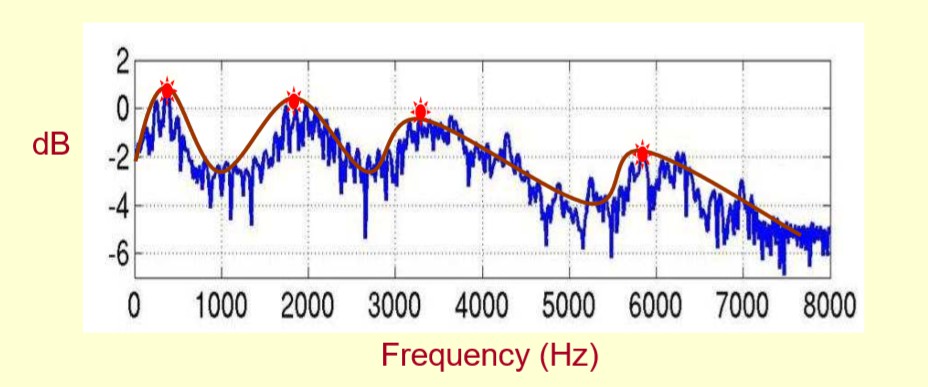
上图是一个语音的频谱图。峰值就表示语音的主要频率成分,将这些峰值称作共振峰。共振峰携带了声音的辨识属性。用它可以识别出不同的声音。
这么重要的特征就需要把它们提取出来。需要提取的不仅仅是共振峰的位置,还得提取它们转变的过程,因此实际提取的就是频谱的包络。所谓包络就是一条连接共振峰点的平滑曲线。
![]()
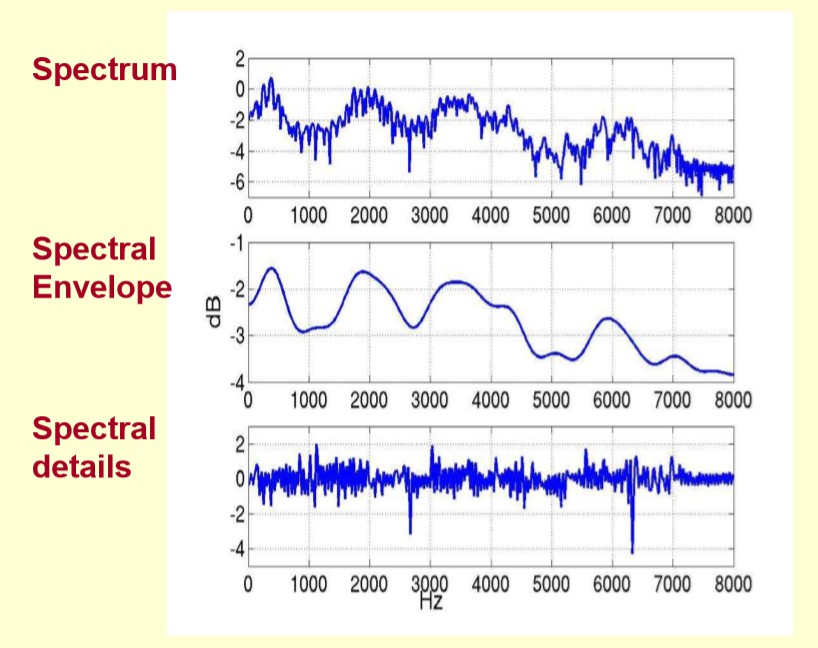
原始的频谱由两部分组成:包络和频谱细节。我们需要将这两部分分离开来,就可以得到包络了。如下图所示:
![]()
也即是,给定logX[k]logX[k],求得logH[k]logH[k]和logE[k]logE[k],以满足logX[k]=logH[k]+logE[k]logX[k]=logH[k]+logE[k]
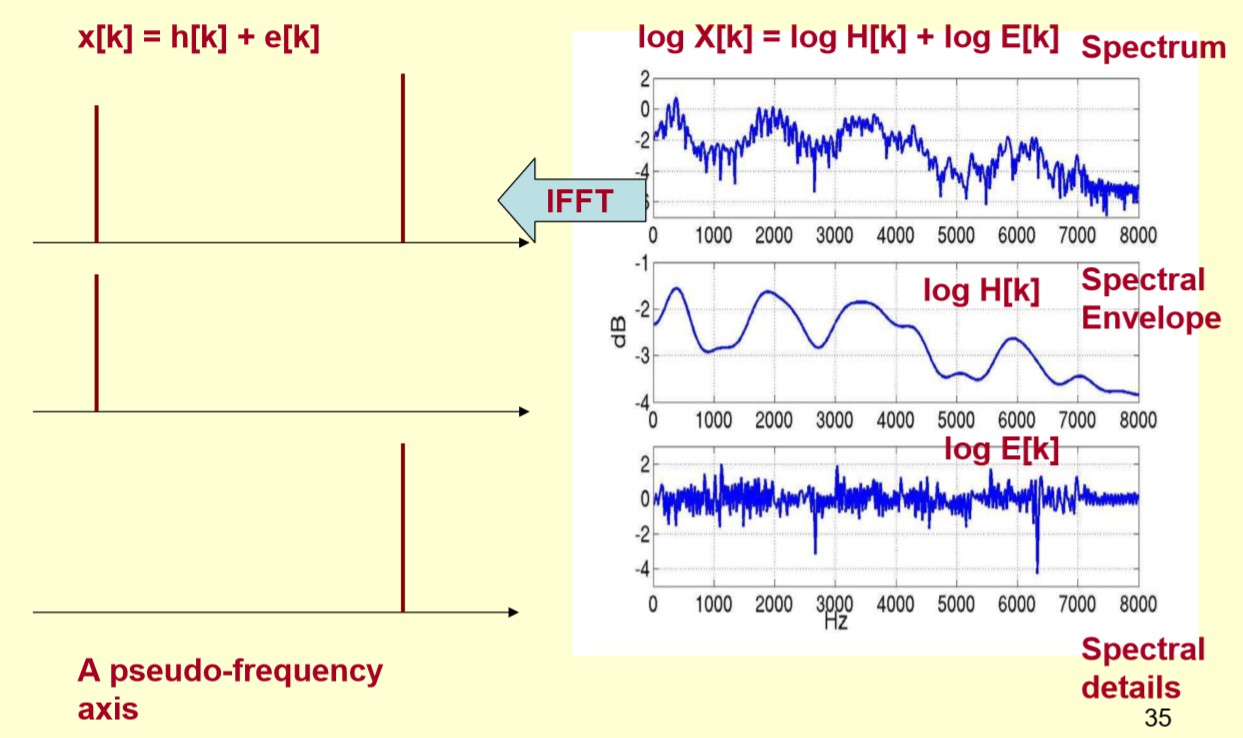
为了达到这一目标,需要对频谱做FFT。在频谱上做傅里叶变换实际就是逆傅里叶变换(IFFT)。需要注意的一点是,需要在频谱的对数域上面处理,在对数频谱上面做逆傅里叶变换就相当于在伪频率坐标轴上面描述信号。
![]()
上图中横轴是伪频率。
由上图可以看到,包络主要是低频,可以将它看作是一个每秒4个周期的正弦信号,这样在伪频率坐标轴4Hz的地方给它一个峰值。而频谱的细节部分主要是高频,可以将它看作是一个每秒100周期的正弦信号,这样在伪频率坐标轴100Hz的地方给它一个峰值。
实际应用中,已经知道logX[k]logX[k],所以可以得到x[k]x[k]。由上图可知,h[k]h[k]是x[k]x[k]的低频部分,那么将x[k]x[k]通过一个低通滤波器就可以得到h[k]h[k]。这样,就可以将它们分离开来,得到想要的h[k]h[k],也就是得到了频谱的包络。
x[k]x[k]实际上就是倒谱,需要关心的包络h[k]h[k]就是倒谱的低频部分。
所谓倒谱就是一种信号的傅里叶变换经过对数运算后,再进行傅里叶反变换得到的谱。主要过程:
- 将原语音信号经过傅里叶变换获得频谱:X[k]=H[k]E[k]X[k]=H[k]E[k]。只考虑幅度就是:|X[k]|=|H[k]||E[k]||X[k]|=|H[k]||E[k]|
- 两边取对数:log|X[k]|=log|H[k]|+log|E[k]|log|X[k]|=log|H[k]|+log|E[k]|
- 两边取逆傅里叶变换得到:x[k]=h[k]e[k]x[k]=h[k]e[k]
-
Mel频率分析
刚刚可以获得语音的频谱包络了,也就是能够得到语音所有共振峰点的平滑曲线。但是对于人类的听觉感知的实验表明,人类听觉感知只聚焦在某些特定的区域,而非整个频谱包络。
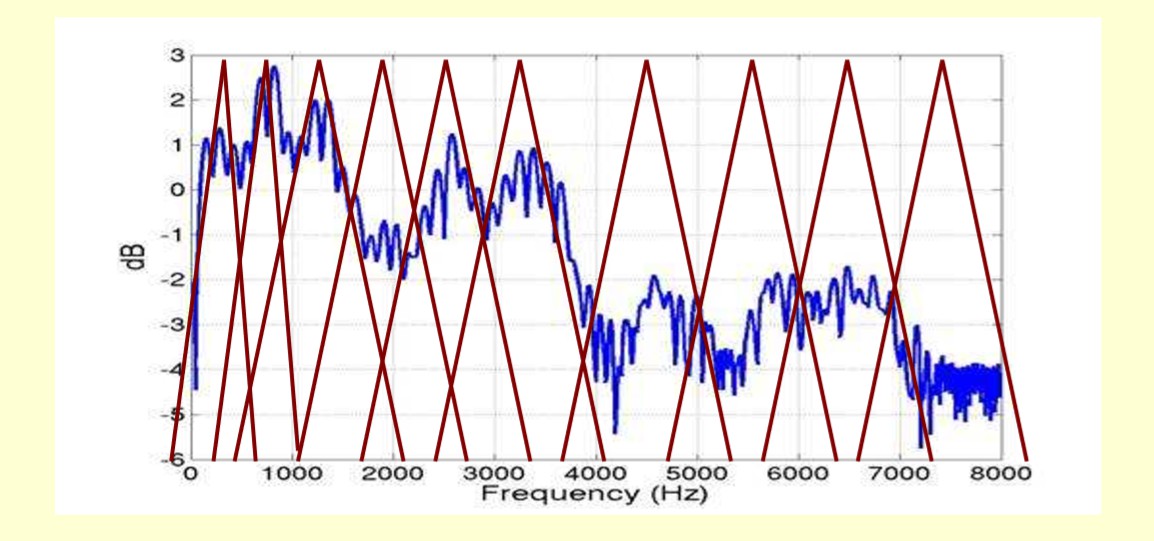
Mel频率分析基于人类的听觉感知实验。实验观测发现人耳就像一个滤波器组一样,它只关注某些特定的频率分量。但是这些滤波器在频率坐标轴上却不是统一分布的,在低频区域有很多的滤波器,分布比较密集,但在高频区域,滤波器的数目就变得比较少,分布很稀疏。
![]()
梅尔频率倒谱系数考虑了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。
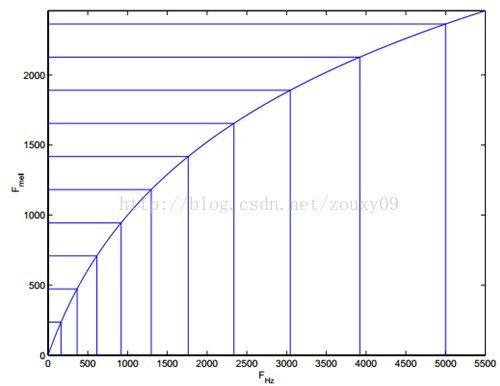
将普通频率转化到Mel频率的公式为:
mel(f)=2595∗log10(1+f700)mel(f)=2595∗log10(1+f700)![]()
在Mel频域内,人对音频的感知度为线性关系。举例而言,如果两段语音的Mel频率相差两倍,则人类感知音高也相差两倍。
-
Mel频率倒谱系数
将频谱通过一组Mel滤波器就得到Mel频谱,在Mel频谱上面获得的倒谱系数h[k]h[k]就称为Mel频率倒谱系数,简称MFCC。
提取梅尔频率倒谱系数MFCC特征的过程:
![]()
-
对语音预加重、分帧和加窗
-
对每个短时分析窗,通过FFT得到对应的频谱
-
将获得的频谱通过Mel滤波器组得到Mel频谱
-
在Mel频谱上面进行倒谱分析:取对数,做逆变换。实际逆变换一般通过离散余弦变换DCT实现,取DCT后的第2个到第13个系数作为MFCC系数。从而获得梅尔频率倒谱系数MFCC。
![]()
这里提到的离散余弦变换(DCT)类似于离散傅里叶变换,只是只使用了实数。由于DCT的性能更接近于理想的KL变换,所以在信号处理中得到广泛的应用,主要用于对信号进行编码压缩,这是由于DCT具有很强的“能量聚集”特性,即大多数的自然信号(包括声音和图像)的能量都集中在DCT后的低频部分。参见离散余弦变换-百度百科,《音频信息处理技术》-韩纪庆、冯涛等p37~p38
-
-









Connect
Email: cncmn@sina.cn
GitHub: cnlinxi@github
参考文献
Mel Frequency Cepstral Coefficient (MFCC) tutorial
Speech Technology: Spectrogram, Cepstrum and Mel-Frequency Analysis(PDF)
《音频信息处理技术》-韩纪庆、冯涛等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号