2024年9月学习月报
一、学习目标
- 学习 VLM 的基本原理和架构,理解视觉和语言信息的融合方式,掌握 VLM 的训练方式与评估方法。
- 学习 VLM 在遥感领域的应用(RemoteCLIP、ChangeCLIP),并尝试本地复现。
二、学习内容
文献
An Introduction to Vision-Language Modeling
VLM 分类
-
基于对比式训练的 VLM
通过对比式学习的方法来对齐图像和文本之间的表示,使得模型能够理解和生成跨模态的内容。一般是用 InfoNCE 作为损失函数。常见的基于对比式训练的 VLM 有 CLIP。 -
基于掩码目标的 VLM
通过掩码部分图像或文本,模型被迫理解未掩盖部分的上下文,从而提高对整体图像和文本关系的理解能力。然而,更多学习的是图像的表象特征(如纹理等),难以捕获深层的语义信息,并且不适合做生成任务。- 在 FLAVA 模型中,图片被分为多个 patch,经过 dVAE 映射后随机替换 patches,文本则随机用 ‘[mask]’ 遮蔽,概率都为 15%。经过各自的多模态编码器得到输出后进行融合。
-
基于生成的 VLM
通过生成任务让模型学习视觉和语言的多模态表示。- CoCa 通过对比训练学习图像和文本之间的对比关系,然后在生成任务中根据图像逐步生成文本描述,模型同时优化这两种任务的损失。
-
基于预训练骨干网络的 VLM
通过利用预训练模型,使模型只需要学习一个文本模态和图像模态之间的映射,从而减少计算资源的需求。然而,仅仅学习文本和视觉表示之间的映射可能不足以捕捉两者之间的深层次关联。
VLM 训练指南
-
训练数据
通过其他模型生成合成数据,数据增强,人工标注。 -
软件
(待补充) -
模型选择
- 基于对比式训练的 VLM 适合做图像-文本对齐或图像-文本检索任务。
- 基于掩码语言或图像的 VLM 适合处理上下文依赖的任务,如视觉问答、图像字幕生成。
- 基于生成的 VLM 通常以生成任务为主。
- 基于预训练骨干网络的 VLM 在计算资源有限的情况下很有帮助。
论文
RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
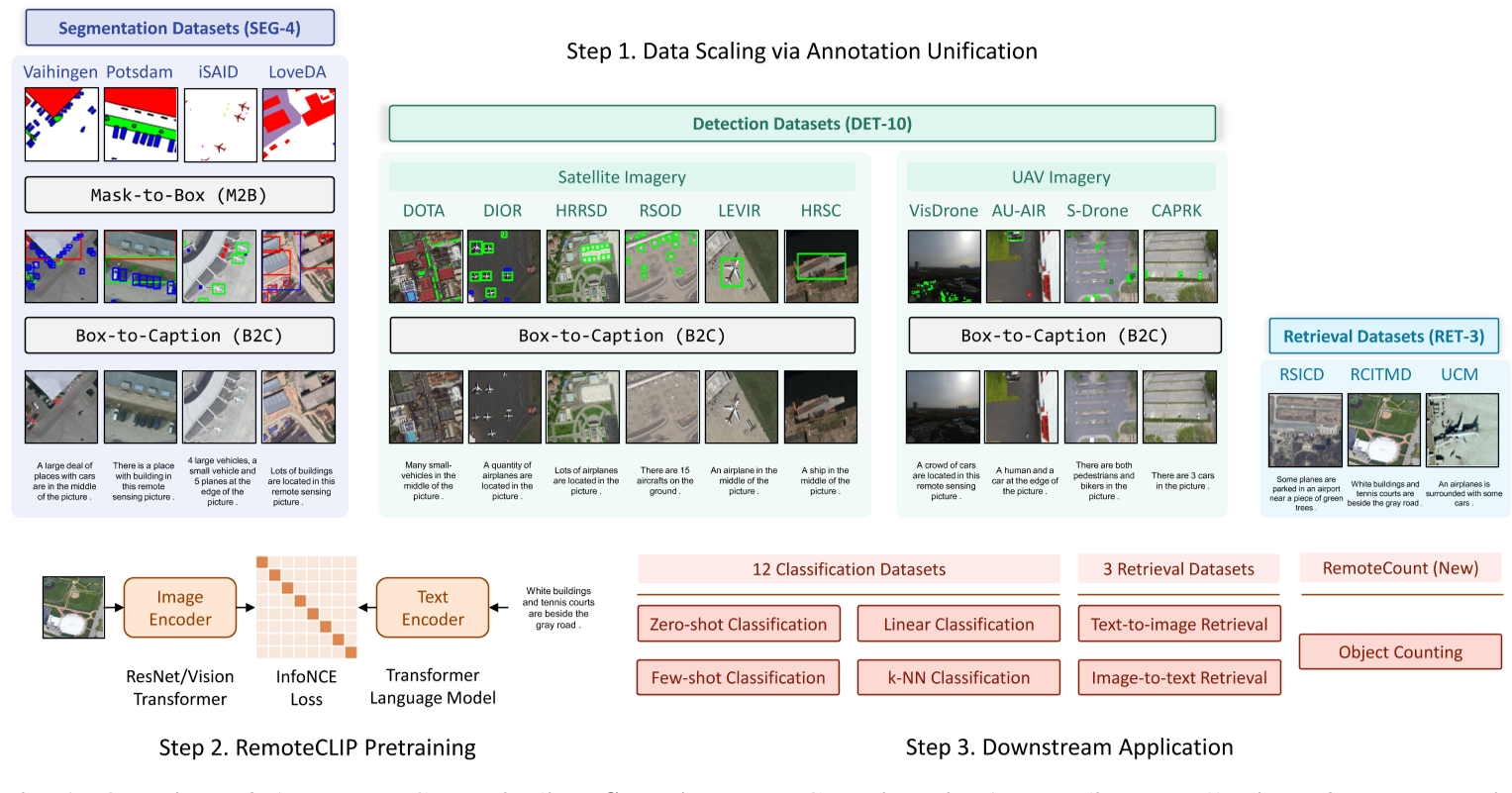
- RemoteCLIP 的创新之处主要有数据扩展策略,通过 box-to-caption (B2C) 方法将目标框转换为文本注释,使目标检测数据集能够用于训练。对于语义分割数据集,另外通过 mask-to-box (M2B) 将掩码转为目标框。这个方法扩充了数据集,解决了训练数据不足的问题。
![]()
- RemoteCLIP 还可以完成目标计数任务,通过将原始描述中的数字替换为 1 到 10 的所有可能数字,生成九个额外的描述,并计算图像与每个描述的相似度分数,获取最高分。但精确度有限,且数目也受到限制。(感觉引入目标检测任务会更加精确)
ChangeCLIP
- ChangeCLIP 主要用于视觉变化检测任务,由四个模块组成:
- 第一个模块利用 CLIP 模型生成两张不同时刻的遥感图像的文本提示。
- 第二个模块用 CLIP 的图像和文本编码器作为特征提取器。
- 第三个模块加入了差异特征补偿 (DFC) 模块,增强模型捕获双时态变化的能力。
- 第四个模块是一个视觉-语言解码器。
下载在 SYSU_CD 数据集上预训练的权重的本地测试结果:
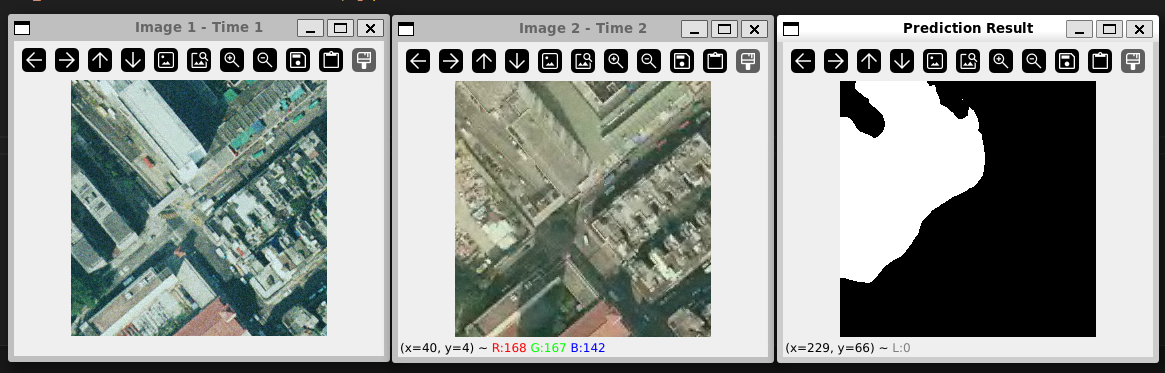
- Idea:如果改进模型使之能监测城市建筑的增减(具体数量),或者植被覆盖率的变化,帮助城市的管理。
三、下阶段目标
- 计划探索多模态的目标检测或语义分割任务,寻找在遥感影像更精细的影像搜索方法。
- 探索VLM在遥感领域关于环境方面的应用。
- 提升源码和论文的阅读能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号