
python网络爬虫与信息提取mooc------request库
request
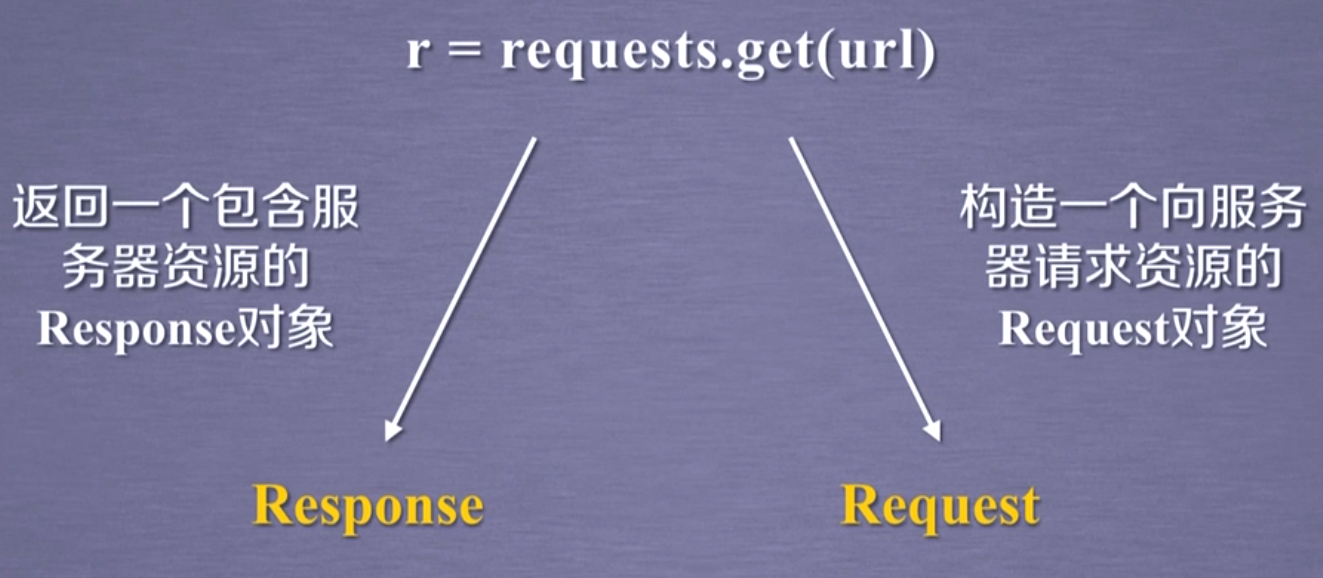
request.get(url,params=None,**kwargs)
url:url页面的链接
params:url中额外参数,字典或字节流格式,是可选的
**kwargs:12个控制访问的参数

Response对象:对象包含爬虫返回的内容
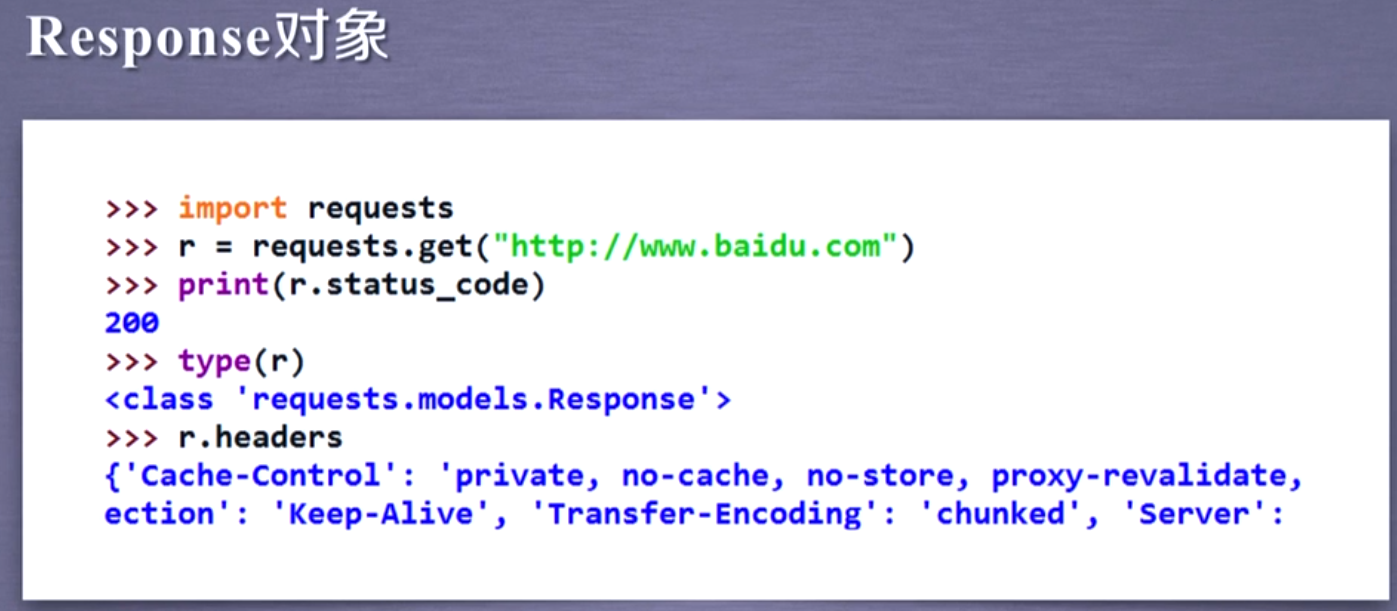
访问成功则状态码是200 r.headers:返回页面头部信息
Response对象的属性


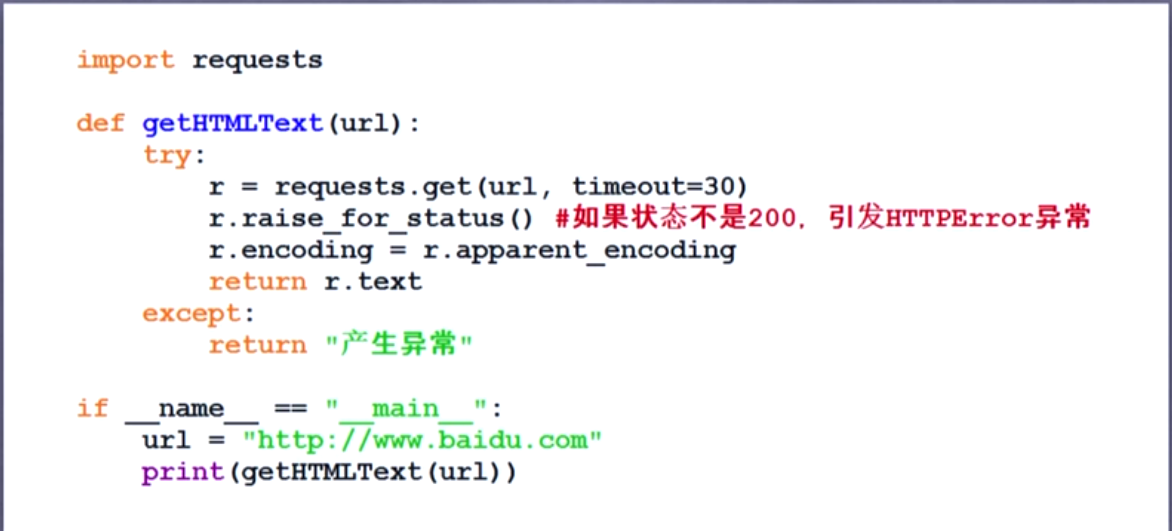
爬取网页框架
requests库的异常


timeout是整个过程的超时异常,connectimeout是链接过程超时异常
爬取网页通用代码框架及访问结果:

requests库的7个主要方法:

URL格式:http://host[:port][path]
host:合法的Internet主机域名或ip地址
port:端口号,缺省端口为80
path:请求资源的路径

patch只改变部分内容,put未提及的内容就会删除,原有数据覆盖掉
向url post一个字典自动编为form(表单);字符串时则是data字段下
requests.request(method,url,**kwargs)
method:请求方式,对应get/put/post七种
**kwargs:控制访问的参数,共13个

