
spark中的文件读取与存储
一、saveAsTextFile(path:String)
把RDD保存到hdfs中。
二、reparation(numPartitions:Int)
可以增加或减少此RDD的并行级别 在内部 它使用shuffle重新分发数据。
//首先查看这个RDD有多少分区
scala> allscores.partitions.size
res8: Int = 4
//把RDD的分区数量设为1 然后传入hdfs中。否则会在hdfs中默认创建四个分区
scala> allscores.repartition(1).saveAsTextFile("hdfs://master:9000//usr/root/sparkdata/scores")
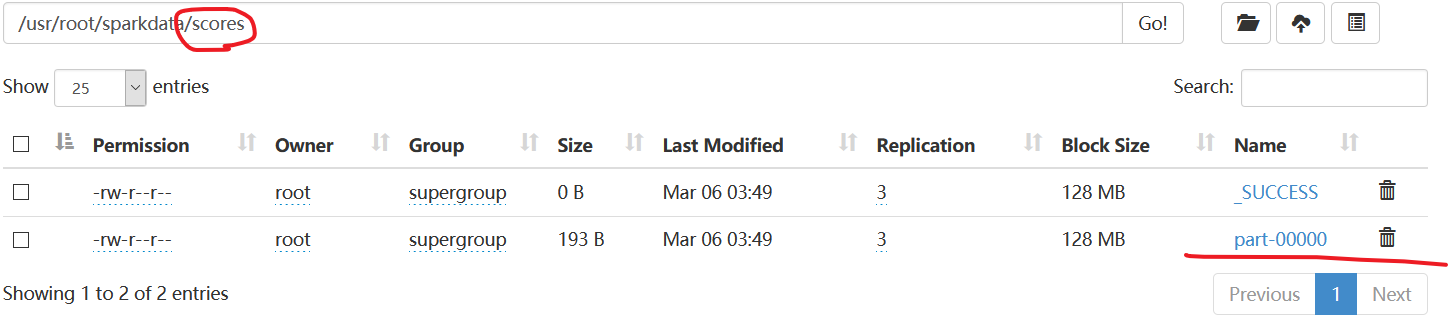
该目录下只有一个文件。
三、coalesce
coalesce(numPartitions:Int,shuffle:Boolean=false,partitionCoalescer:Option[PartitionCoalescer]=Option.empty)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号