SpringCloudStream学习笔记(转)
Spring Cloud Stream 知识整理
概念 使用方法
概念
1. 发布/订阅
简单的讲就是一种生产者,消费者模式。发布者是生产,将输出发布到数据中心,订阅者是消费者,订阅自己感兴趣的数据。当有数据到达数据中心时,就把数据发送给对应的订阅者。
2. 消费组
直观的理解就是一群消费者一起处理消息。需要注意的是:每个发送到消费组的数据,仅由消费组中的一个消费者处理。
3. 分区
类比于消费组,分区是将数据分区。举例:某应用有多个实例,都绑定到同一个数据中心,也就是不同实例都将数据发布到同一个数据中心。分区就是将数据中心的数据再细分成不同的区。为什么需要分区?因为即使是同一个应用,不同实例发布的数据类型可能不同,也希望这些数据由不同的消费者处理。这就需要,消费者可以仅订阅一个数据中心的部分数据。这就需要分区这个东西了。
Spring Cloud Stream简介
1. 应用模型
Spring Cloud Stream应用由第三方的中间件组成。应用间的通信通过输入通道(input channel)和输出通道(output channel)完成。这些通道是有Spring Cloud Stream 注入的。而通道与外部的代理(可以理解为上文所说的数据中心)的连接又是通过Binder实现的。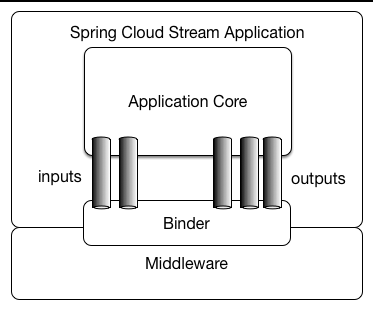
上图就是Spring Cloud Stream的应用模型。
1.1 可独立运行的jar
Spring Cloud Stream应用可以直接在IDE运行。这样会很方便测试。但在生产环境下,这是不适合的。Spring Boot为maven和Gradle提供了打包成可运行jar的工具,你可以使用这个工具将Spring Cloud Stream应用打包。
2. 抽象的Binder
Binder可以理解为提供了Middleware操作方法的类。Spring Cloud 提供了Binder抽象接口以及KafKa和Rabbit MQ的Binder的实现。
使用Spring Cloud Stream
1. 快速开始
这里先放出前面的应用模型图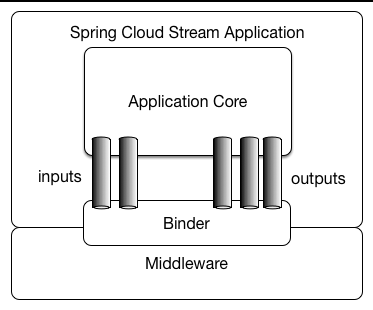
下面例子使用的Middleware是Kafka,版本是kafka_2.11-1.0.0。Kafka使用的是默认配置,也就是从Kafka官网下载好后直接打开,不更改任何配置。
关于pom.xml中依赖的项目的版本问题,最好不该成别的版本,因为很大可能导致版本冲突。
1.1 pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.8.RELEASE</version>
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-dependencies</artifactId>
<version>Ditmars.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<exclusions>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
</dependencies>
需要注意的是:官网上的例子是没有下面配置的
<exclusions>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
</exclusion>
</exclusions>
读者可以按照个人情况选择加不加。
简单说明一下以上配置
<parent>...</parent>:这段代表继承spring-boot-starter-parent的配置。因为Spring Cloud Stream 依赖Spring Boot的自动配置,所以需要加上这段。
<dependencyManagement>...</dependencyManagement>:这段是引入spring-cloud-stream-dependencies.pom.xml,该配置文件里含有Spring Cloud Stream 项目需要使用的jar包的信息(包名加版本号)
<dependencies>...</dependencies>依赖两个starter
1.2 App.java
@EnableBinding(value = { Processor.class })
@SpringBootApplication
public class App {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(App.class);
// 注册处理函数
System.out.println("注册结果:" + setHander(context));
// 发送消息
System.out.println("发送结果:" + write(context));
}
// 发送消息
public static boolean write(ConfigurableApplicationContext context) {
Service service = context.getBean(Service.class);
return service.write("狗子在吗?");
}
// 注册接收到消息时的处理函数
public static boolean setHander(ConfigurableApplicationContext context) {
Service service = context.getBean(Service.class);
return service.subscribe(result -> {
System.out.print("狗子收到消息:" + result.getPayload());
});
}
}
上面使用了两个注解:@EnableBinding 和 @SpringBootApplication。@SpringBootApplication 就不说了。@EnableBinding 注解接收一个参数,参数类型是class。上面代码中,传入的参数是“Processor.class”,这是一个接口,定义了两个channel,分别是input和output。看名称就知道,一个是输出通道(input channel),一个是输出通道(output channel)。“@EnableBinding(value = { Processor.class })”这整段代表创建Processor定义的通道,并将通道和Binder绑定。
Porcessor是Spring Cloud Stream为方便使用而预先定义好的,除了Processor还有Sink和Source,这些接口定义了一些通道(channel),需要时,直接使用就好。我们也能自己定义通道(channel)。
App类中的main方法调用了SpringApplication.run,接着调用了write和setHandler方法。方法很简单,上文有注释,不再赘述。
1.3 Service.java
@Component public class Service { @Autowired private Processor processor; public boolean write(String data) { return processor.output().send(MessageBuilder.withPayload(data).build()); } public boolean subscribe(MessageHandler handler) { return processor.input().subscribe(handler); } }
这是一个service类,封装了一些对通道的操作。
需要注意的是这段代码:
@Autowired private Processor processor;
前面说过,Processor是一个定义了输入输出通道的接口,并没有具体实现。Spring Cloud Stream会帮我们自动实现它。我们只需要获取它,并使用它。
processor.output().send(MessageBuilder.withPayload(data).build());
先是调用output()方法获取输出通道对象,接着调用send方法发送数据。send方法接收一个Message对象,这个对象不能直接new,需要使用MessageBuilder获取。
1.4 application.properties
spring.cloud.stream.bindings.input.destination=test
spring.cloud.stream.bindings.output.destination=test
上面配置了目的地,类比于Kafka的Topic和RabbitMQ的队列的概念。
配置格式如下:
spring.cloud.stream.bindings.<channelName>.<key>=value
channelName就是管道名,key就是对应属性,这里是destination,代表目的地。
管道名,key的其他可选值以后再讲,这里不要强求全部弄懂,接着看就好。
1.4 总结
上面就是完整的例子了。对比前面给出的应用模型图,上面的代码和配置文件定义了Application Core(代码中的处理函数,发送消息的函数等等),创建了通道并和Binder绑定(@EnableBinding(value = { Processor.class }))。Middleware就是本节一开始说的Kafka。整个流程大概如下:
开启Middleware(Kafka)
创建通道并与Binder绑定(@EnableBinding)
编写操作通道的代码
在配置文件上配置目的地,组,Middleware的地址,端口等等
使用Spring Cloud Stream
1 声明和绑定通道(channel)
1.1 声明通道
Spring Cloud Stream 可以有任意数量的通道。声明通道的方式很简单。下面先给出之前说过的Sink,Source,Processor接口的源码:
public interface Sink { String INPUT = "input"; @Input(Sink.INPUT) SubscribableChannel input(); } public interface Source { String OUTPUT = "output"; @Output(Source.OUTPUT) MessageChannel output(); } public interface Processor extends Source, Sink { }
就是使用了@Input和@Output注解了方法。其中@Input注解的方法返回的是SubscribableChannel,@Output注解的方法返回的是MessageChannel。
声明通道(channel)的方法就是使用@Input和@Output注解方法。你想要多少通道就注解多少方法。
给通道命名
默认情况下,通道的名称就是注解的方法的名称,例如:
@Input public SubscribableChannel yyy();
那么该通道的名称就是yyy。也能够自己定义通道名称。只需要给@Input和@Output注解传入String类型参数就可以了,传入的参数就是该通道了名称。例如:
@Input("zzz") public SubscribableChannel yyy();
通道的名称就变成了zzz。
1.2 创建和绑定通道
只需要使用@EnableBinding就能创建和绑定通道(channel)。
@EnableBinding(value={Sink.class,Source.class})
@EnableBinding注解接收的参数就是使用@Input或者@Output注解声明了通道(channel)的接口。Spring Cloud Stream会自动实现这些接口。
上文中说过,@Input和@Output注解的方法有相应的返回值,这些返回值就是对应的通道(channel)对象。要使用通道(channel)时,就只要获取到Spring Cloud Stream对这些接口的实现,再调用注解的方法获取到通道(channel)对象进行操作就可以了。如何获取接口的实现下文会讲。
绑定通道(channel)是指将通道(channel)和Binder进行绑定。因为Middleware不只一种,例如有Kafka,RabbitMQ。不同的Middleware有不同的Binder实现,通道(channel)与Middleware连接需要经过Binder,所以通道(channel)要与明确的Binder绑定。
如果类路径下只有一种Binder,Spring Cloud Stream会找到并绑定它,不需要我们进行配置。如果有多个就需要我们明确配置了,配置方式下文会讲。这里只需要知道@EnableBinding能帮我们自动实现接口,创建通道和实现通道与Binder的绑定就可以了。
获取绑定了的通道
使用了@EnableBinding注解后,Spring Cloud Stream 就会自动帮我们实现接口。那么,可以通过Spring支持的任何一种方式获取接口的实现,例如自动注入,getBean等方式,下面给出官方例子:
@Component public class SendingBean { private Source source; @Autowired public SendingBean(Source source) { this.source = source; } public void sayHello(String name) { source.output().send(MessageBuilder.withPayload(name).build()); } }
也能够直接注入通道(channel)
@Component public class SendingBean { private MessageChannel output; @Autowired public SendingBean(MessageChannel output) { this.output = output; } public void sayHello(String name) { output.send(MessageBuilder.withPayload(name).build()); } }
如果你给通道命名了,需要使用@Qualifier注解指明通道名称
@Component public class SendingBean { private MessageChannel output; @Autowired public SendingBean(@Qualifier("customOutput") MessageChannel output) { this.output = output; } public void sayHello(String name) { this.output.send(MessageBuilder.withPayload(name).build()); } }
2 生产和消费消息
2.1 生产消息
一种方式是调用通道(channel)的send方法发布消息。还有就是使用Spring Intergration的方式生产数据
@EnableBinding(Source.class) public class TimerSource { @Value("${format}") private String format; @Bean @InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = "${fixedDelay}", maxMessagesPerPoll = "1")) public MessageSource<String> timerMessageSource() { return () -> new GenericMessage<>(new SimpleDateFormat(format).format(new Date())); } }
Spring Cloud Stream是继承Spring Intergration的,所有Spring Cloud Stream 天然支持Spring Intergration的东西。
2.2 消费消息
一种方式是前面快速开始中的那样注册处理函数,下面将是使用@StreamListener注解对消息进行处理
使用@StreamListener的例子
@EnableBinding(value = { Processor.class })
@SpringBootApplication
public class App {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(App.class);
// 发送消息
System.out.println("发送结果:" + write(context));
}
@StreamListener(Sink.INPUT)
public void handler(String message) {
System.out.print("狗子收到消息:" + message);
}
// 发送消息
public static boolean write(ConfigurableApplicationContext context) {
Service service = context.getBean(Service.class);
return service.write("狗子在吗?");
}
}
在这将下面的代码去掉,换成@StreamListener
public static boolean setHander(ConfigurableApplicationContext context) { Service service = context.getBean(Service.class); return service.subscribe(result -> { System.out.print("狗子收到消息:" + result.getPayload()); }); }
@StreamListener接收的参数是要处理的通道(channel)的名,所注解的方法就是处理从通道获取到的数据的方法。方法的参数就是获取到的数据。
消息是带有Header的,类似Http的headler,上面有contentType属性指明消息类型。如果contentType是application/json,那么@Streamlistener会自动将数据转化成@StreamListener注解的方法的参数的类型。
可以是@Header,@Headers注解获取消息的Header
@StreamListener(target=Sink.INPUT) public void handler1(Message message,@Header(name="contentType") Object header) { System.out.print("狗子收到message消息:" + message.getMessage()); System.out.print("消息header:" + header); }
用法如上,使用@Header或者@Headers注解方法的参数,指明让Spring Cloud Stream将消息的Header传入对应的参数。
@Header和@Headers的区别就是一个是获取单个属性,需要指明哪个属性,一个是获取全部属性。
@StreamListener(target=Sink.INPUT) public void handler1(Message message,@Headers Map<String,Object> header) { System.out.print("狗子收到message消息:" + message.getMessage()); System.out.print("消息header:" + header); }
实际上还有一些注解是@PayLoad和@PayLoads,看名字就知道是获取消息内容的,具体用法和注意事项Spring Cloud Stream 官方文档上没讲,这部分内容以后补充。
注意:如果@StreamListener注解的方法有返回值,那么必须使用@SendTo注解指明返回的值写入哪个通道
@EnableBinding(Processor.class) public class TransformProcessor { @Autowired VotingService votingService; @StreamListener(Processor.INPUT) @SendTo(Processor.OUTPUT) public VoteResult handle(Vote vote) { return votingService.record(vote); } }
使用@StreamListener将消息分发给多个方法
若想使用消息分发的功能,方法必须先满足一下条件:
(1)没有返回值
(2)方法是单独的消息处理方法(原文:it must be an individual message handling method (reactive API methods are not supported))
分发的条件在注解的“condition”属性中指明,而且条件是由SpEL表达式编写的。所有匹配条件的处理函数将会在相同的线程中无固定顺序的调用。
下面给出一个例子(由快速开始中例子修改而来):
下面这个例子中,pom.xml,和application.properties与快速开始的一样。
//先定义两个DTO public class Message { private String message; private Integer all; public String getMessage() { return message; } public void setMessage(String message) { this.message = message; } public Integer getAll() { return all; } public void setAll(Integer all) { this.all = all; } } public class Error { private String error; public String getError() { return error; } public void setError(String error) { this.error = error; } }
接着是封装了的通道(channel)操作的Service。与快速开始的例子不同的是,这个里创建消息时设置的Header的“contentType”属性,值为消息携带的数据的Class的SimpleName
@Component public class Service { @Autowired private Processor processor; public boolean write(Object data) { return processor.output().send( MessageBuilder.withPayload(data).setHeader("contentType", data.getClass().getSimpleName()).build()); } }
最后是App类。这类将发布了两次消息,分别是Message类型的和Error类型的。并且使用@StreamListener注解了三个方法,都设置了condition属性指明分发条件。
@EnableBinding(value = { Processor.class })
@SpringBootApplication
public class App {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(App.class);
// 发送消息
Message message = new Message();
message.setAll(200);
message.setMessage("狗子在吗?");
Error error = new Error();
error.setError("错误呼唤!");
write(context, message);
write(context, error);
}
@StreamListener(target = Sink.INPUT, condition = "headers['contentType']=='Message'")
public void handler1(@Payload Message message, @Header("contentType") String header) {
System.out.println("狗子收到message消息1:" + message.getMessage());
}
@StreamListener(target = Sink.INPUT, condition = "headers['contentType']=='Error'")
public void handler2(Error message) {
System.out.print("狗子收到error消息2:" + message.getError());
}
@StreamListener(target = Sink.INPUT, condition = "headers['contentType']=='Message'")
public void handler3(@Payload Message message, @Header("contentType") String header) {
System.out.println("狗子收到message消息3:" + message.getMessage());
}
// 发送消息
public static boolean write(ConfigurableApplicationContext context, Object data) {
Service service = context.getBean(Service.class);
return service.write(data);
}
}
输出结果:
狗子收到message消息1:狗子在吗?
狗子收到message消息3:狗子在吗?
狗子收到error消息2:错误呼唤!
可以看到匹配了“contentType=Message”的两个方法都执行了,匹配了“contentType=error”的方法也执行了。
这里我再补充一点使用时遇到的问题
如果把Header设置一个属性“type=XXX”,但获取到消息的时候,Header上并没有这个属性。简单尝试了一些,发现只能修改现有属性(例如contentType),不能添加新属性。
2.3 聚合
2.3.1 使用限制
Spring Cloud Stream 支持聚合多个应用的功能。这个功能可以直接连接多个应用的输入,输出通道,避免通过代理(指Kafka,RabbitMQ这些Middleware)交换消息时带来的额外耗费。到1.0版的Spring Cloud Stream为止,聚合功能仅支持下列应用:
(1)只有单个输出通道,并且命名为output的应用(就是Source)
(2)只有单个输入通道,并且命名为input的应用(就是Sink)
(3)只有一个输出通道和一个输入通道并且命名为output和input的应用(就是Processor)
以上是官方文档原话,个人觉得很鸡肋的功能,也许我用得少吧。
具备以上特征的应用就可以使用Spring Cloud Stream的聚合功能将多个应该连接成一串互相连接的应用。
这里还有几个限制,起始的应用必须是Source或者Processor,结束的应用必须是Sink或者Processor。中间的应用必须是Processor,不过可以有任意数量的Processor。(Soruce,Sink,Processor就是指具备上面所说特征的应用)
2.3.2 例子
下面给出官方例子,先说明几个注意点:
(1)下面例子中有三个应用分别是Source,Sink,Processor,这三个应用可以分布在不同项目中,也能在相同项目中。需要注意的是,如果在相同项目中,应该要处于不同的包中,如果同个包,多个@SpringBootApplication注解会导致报错
(2)使用@Transformer注解需要指明inputChannel和outputChannel属性。官方文档的例子上是没有指明的,但我运行的时候如果不指明就不能将多个应用连在一起。
(3)不要使用eclipse中的Spring Boot应用的插件运行,使用插件运行会报注意点1的错误,原因是什么不清楚。
//Source @SpringBootApplication @EnableBinding(Source.class) public class SourceApplication { @InboundChannelAdapter(value = Source.OUTPUT) public String timerMessageSource() { return new SimpleDateFormat().format(new Date()); } } //Processor @SpringBootApplication @EnableBinding(Processor.class) public class ProcessorApplication { @Transformer(inputChannel=Sink.INPUT,outputChannel=Source.OUTPUT) public String loggerSink(String payload) { return payload.toUpperCase(); } } //Sink @SpringBootApplication @EnableBinding(Sink.class) public class SinkApplication { @StreamListener(Sink.INPUT) public void loggerSink(Object payload) { System.out.println("Received: " + payload); } }
上面是三个应用,下面是将三个应用连接起来的代码。
@SpringBootApplication public class App { public static void main(String[] args) { new AggregateApplicationBuilder().from(SourceApplication.class).args("--fixedDelay=5000") .via(ProcessorApplication.class).to(SinkApplication.class).args("--debug=true").run(args); } }
代码很简单,就是使用AggregateApplicationBuilder将三个应用连接起来。.args("XXX")这段代码的作用就是为对应的应用传递运行时参数。
2.3.3 不同连接情况下的Binder绑定
由于限制多多,可以穷举出所有的可能连接,下面给出不同连接与Binder的绑定情况:
(1)如果以Source应用开始并且以Sink应用结束,那么应用间的连接是直接进行的,不会经过代理(指Kafka,RabbitMQ这些Middleware),也就不会与Binder绑定。例如上面的例子,你把使用的Middleware关闭,例如我使用的是Kafka,我把Kafka关了,应用也能跑起来。
(2)如果以Processor应用开始,那么这个应用的input通道就是这一串一样的input通道,这种情况下,会触发input通道与Binder的绑定。
(3)如果以Processor应用结束,那么这个应用的output通道就是这串硬硬的output通道,会触发output通道与Binder的绑定。
2.3.4 配置聚合的应用
Spring Cloud Stream 支持为聚合在一起的多个应用中的一个应用传递参数。
为应用命名namespace后,就可以通过命令行,环境变量等方式给应用传递参数。
public static void main(String[] args) { new AggregateApplicationBuilder() .from(SourceApplication.class).namespace("from").args("--fixedDelay=20000") .via(ProcessorApplication.class).namespace("via") .to(SinkApplication.class).namespace("to").args("--debug=true").run(args); }
这段代码和前面的例子没太大差别,只是多了.namespace(),这段代码就是为应用设置namesapce。
接着是聚合在一起的应用的代码:
//获取传入的参数 @Value("${fixedDelay:null}") private String args; @InboundChannelAdapter(value = Source.OUTPUT) public String timerMessageSource() { //输出参数 System.out.println("Source get args:"+args); return new SimpleDateFormat().format(new Date()); }
这里只给出一个,其他类似,都是加了获取参数和输出参数的代码。
接着打包后以下列命令运行:
java -jar stream-aggregation.jar
输出:
Source get args:20000 Processor get args:null Sink get args:null Received: 17-12-14 下午5:43
可以看到,因为Processor是没有fixedDelay参数的,所有输出null
以下列命令运行:
java -jar stream.jar via --fixedDelay=200
输出:
Source get args:20000 Processor get args:200 Sink get args:null Received: 17-12-14 下午5:46
可以看到,输出为200,就是我们传入的参数,而Sink和Source的输出没变,也就是没改变它们的参数
总结一下:
- 在聚合时候设置namespace
- 在命令行或者环境变量等方式使用namespace为指定应用传递参数
Binder以及配置
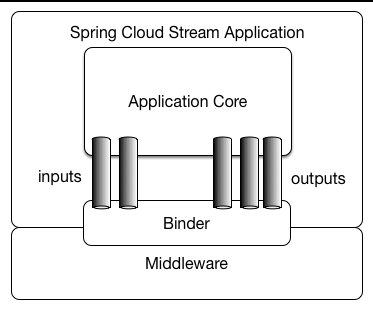
这里再放出应用模型图。Binder简单的理解就是封装了对消息系统(kafka,rabbitMQ)的操作。可以使用开发者简单的配置就能使用消息系统的发布/订阅,点对点传输,分组,分区等等功能。是开发者开放时能忽略对消息系统操作的细节。当然,这些组件的设计一般是抽象出一个接口,然后对不同的消息系统有不同的实现,这些东西这里不讲,只讲怎么用。
1 Binder实现类的检测
1.1 单个Binder实现类
如果在类路径上只有一个Binder的实现类(例如你在maven项目中,只添加了kafka的Binder的实现的依赖),那么Spring Cloud Stream会默认使用这个实现类,所有的通道(Channel)都会绑定这个Binder。就像前面的例子那样,你几乎感觉不到Binder的存在,你只需要配置一下通道(Channel)的目的地(destination),分组(group),分区(partition)等信息就可以使用。例如快速开始的例子中就仅仅配置了输入,输出通道的目的地
spring.cloud.stream.bindings.input.destination=test
spring.cloud.stream.bindings.output.destination=test
1.2 多个Binder实现类
如果有多个Binder实现类,那么就必须指明哪个通道(Channel)绑定哪个Binder。配置的方式就是在application.peoperties或者application.yaml配置文件上添加一下内容:
spring.cloud.stream.bindings.通道名称.binder=Binder名称
这样就能指明什么通道绑定哪个Binder了。
当然,你也可以配置默认的Binder
spring.cloud.stream.defaultBinder=Binder名称
关于Binder的名称
在每个Binder实现的jar包的META-INF目录下都会有一个spring.binders文件。该文件是一个简单的单属性文件,例如rabbitMQ的Binder的实现的spring.binders文件的内容如下:
rabbit:\org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration
前面的key部分(这里是rabbit)就是Binder的名称。也就是rabbitMQ的Binder的名称就是rabbit。实际上现在也就只有两种Binder的实现,一个是rabbitMQ的一个是kafka的,kafka的Binder的名称就是kafka。
2 可选配置
可以通过Spring Boot的任意配置机制来对Spring Cloud Stream应用进行配置,例如应用参数(application argument),环境变量(environment variable)以及YAML 或者 properties文件。
2.1 对应用的配置
spring.cloud.stream.instanceCount
这个是配置应用实例的数量。如果使用kafka,必须设置分区。默认值为1
spring.cloud.stream.instanceIndex
实例的编号,编号从0开始。
spring.cloud.stream.dynamicDesinations
设置一列目的地用以动态绑定。如果设置了,只有列表中的目的地能被绑定。默认值为空。
spring.cloud.stream.defaultBinder
设置的默认的Binder,这个前面说过,不再赘述。默认值为空。
spring.cloud.stream.overrideCloudConnectors
默认值为false。当值为false时,Binder会检查并选择合适的bound Service来创建连接。当设为true的时候,Binder会按照Spring Cloud Stream配置文件来选择bound Service。这个配置通常是在需要连接多个消息系统的时候用到。
2.2 连接(Binding)的配置
这类配置的格式如下:
spring.cloud.stream.bindings.<channelName>.<property>=<value>
意思就是配置名为channelName的通道的property属性的值为value。
为了避免重复配置,Spring Cloud Stream 也支持对全部通道(channel)进行设置。配置默认属性的格式如下:
spring.cloud.stream.default.<property>=<value>
2.2.1 通用的配置
一下的配置属性都带有“spring.cloud.stream.bindings.<channelName>”前缀,为方便文字排版,省略前缀。
destination
通道(channel)与消息系统连接的目的地(若消息系统是RabbitMQ,目的地(destination)就是指exchange,消息系统是Kafka,那么就是指topic)。
可以连接多个目的地。要想连接多个目的地,只需要用“,”将多个目的地分开即可。例如:
spring.cloud.stream.channelName.destinaction=destinaction1,destinaction2
group
配置通道的消费者组。仅应用于输入通道。
默认值为null
补充:一个channel可以连接多个destination,同一个group内的channel连接的destination可以不同。
如果一个group内的channel连接了A,B,C三个destination。那么A,B,C这个三个destination的消息都会拷贝一份发给这个group,并且选择这个group中channel消费这个消息。
如,这个group中的a,b两个channel连接并且只连接了destination A,channel c连接且只连接了destination B,那么会在a,b中选一个来处理来自A的消息,c不在选择的范围内。
如果有两个group都连接了destination A,那么A的消息会拷贝两份分别发给这两个group。
contentType
通道(channel)承载的内容的类型。
默认值为null。
binder
这个在前面“多个Binder实现类”部分讲了。
————————————————
版权声明:本文为CSDN博主「晴天小哥哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_38399962/article/details/82192340

 浙公网安备 33010602011771号
浙公网安备 33010602011771号