XML解析之SAX方式解析xml文件
XML是一种通用的数据交换格式,它的平台无关,语言无关,系统无关,在不同的语言环境的解析方式都是一样的,只不过是实现的语法不同。
DOM ,SAX属于基础方法,是官方提供的平台无关的解析方式;JDOM,DOM4J属于扩展方法,他们是在基础的方法上扩展出来,只适用于Java平台;
JAXP是SDK提供的一套解析XML的API,支持DOM和SAX解析方式,JAXP是JavaSE一部分,它由javax.xml,org.w3c.sax,org.xml.sax包及其子包组成。从JDK6.0开始,JAXP开始支持另一种XML解析方式--StAX解析方式。
本文将重点介绍下用SAX解析文件:
SAX解析方式会逐行地去扫描XML文档,当遇到标签时会触发解析处理器,采用事件处理的方式解析XML (Simple API for XML) ,不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。
优点是:在读取文档的同时即可对XML进行处理,不必等到文档加载结束,相对快捷。不需要加载进内存,因此不存在占用内存的问题,可以解析超大XML。
缺点是:只能用来读取XML中数据,无法进行增删改。
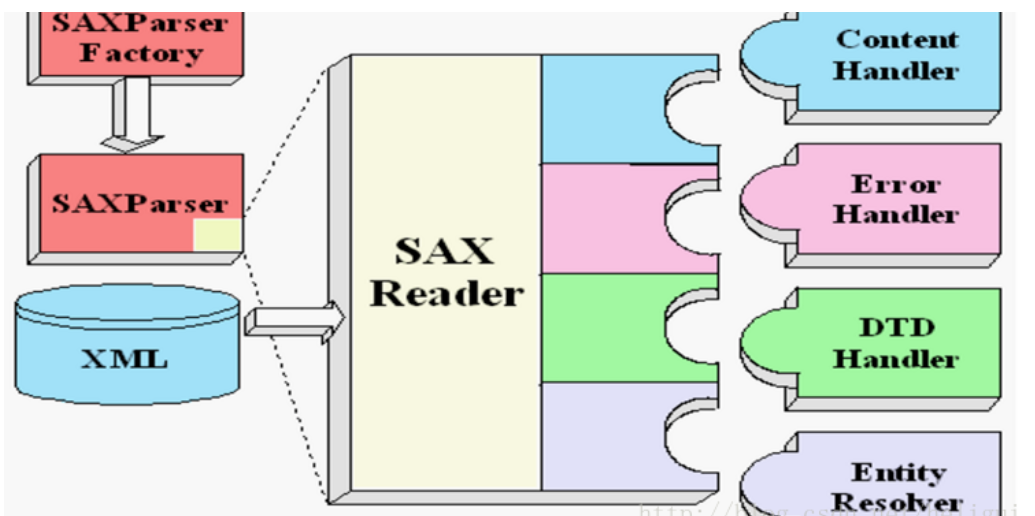
SAX解析可分四个步骤进行:
1、得到xml文件对应的资源,可以是xml的输入流,文件和uri
2、得到SAX解析工厂(SAXParserFactory)
3、由解析工厂生产一个SAX解析器(SAXParser)
4、传入输入流和handler给解析器,调用parse()解析
public static void main(String[] args) throws Exception {
//1.创建解析工厂
SAXParserFactoryfactory=SAXParserFactory.newInstance();
//2.得到解析器
SAXParser sp=factory.newSAXParser();
//3得到解读器
XMLReader reader=sp.getXMLReader();
//设置内容处理器
reader.setContentHandler(new ListHandler());
//读取xml的文档内容
reader.parse("src/Book.xml");
}
}
1.创建一个Book.xml的 xml文档


<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<书名 name="dddd">java web就业</书名>
<作者>张三</作者>
<售价>40</售价>
</书>
<书>
<书名 name="xxxx">HTML教程</书名>
<作者>自己</作者>
<售价>50</售价>
</书>
</书架>
2.创建一个javaBean实体类
package sax;
public class Book {
private String name;
private String author;
private String price;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
@Override
public String toString() {
return "Book [name=" + name + ", author=" + author + ", price=" + price + "]";
}
}
3.新建一个ListHandler类,这个类需要DefaultHandler或者实现ContentHandler接口。该类是SAX解析的核心所在,我们要重写以下几个我们关心的方法。
1、startDocument():文档解析开始时调用,该方法只会调用一次
2、startElement(String uri, String localName, String qName,
3、Attributes attributes):标签(节点)解析开始时调用
uri:xml文档的命名空间 localName:标签的名字 qName:带命名空间的标签的名字 attributes:标签的属性集 characters(char[] ch, int start, int length):解析标签的内容的时候调用 ch:当前读取到的TextNode(文本节点)的字节数组 start:字节开始的位置,为0则读取全部 length:当前TextNode的长度
4、endElement(String uri, String localName, String qName):标签(节点)解析结束后调用
5、endDocument():文档解析结束后调用,该方法只会调用一次
新建的ListHandler类实现完整代码如下:
class ListHandler implements ContentHandler{
/**
* 当读取到第一个元素时开始做什么
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes atts) throws SAXException {
System.out.print("<"+qName);
for(int i=0;atts!=null&&i<atts.getLength();i++){
String attName=atts.getQName(i);
String attValueString=atts.getValue(i);
System.out.print(" "+attName+"="+attValueString);
System.out.print(">");
}
}
/**
* 表示读取到第一个元素结尾时做什么
*/
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.print("</"+qName+">");
}
/**
* 表示读取字符串时做什么
*/
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.print(new String(ch,start,length));
}
@Override
public void setDocumentLocator(Locator locator) {
// TODO Auto-generated method stub
}
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void endPrefixMapping(String prefix) throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void processingInstruction(String target, String data)
throws SAXException {
// TODO Auto-generated method stub
}
@Override
public void skippedEntity(String name) throws SAXException {
// TODO Auto-generated method stub
}
}
到此,sax方式解析XML文档结束。
总结,SAX解析XML具有解析速度快,占用内存少,对于Android等移动设备来说有巨大的优势,深入了解SAX的事件触发机制是掌握SAX解析的关键,掌握了SAX的事件触发就掌握了SAX解析XML
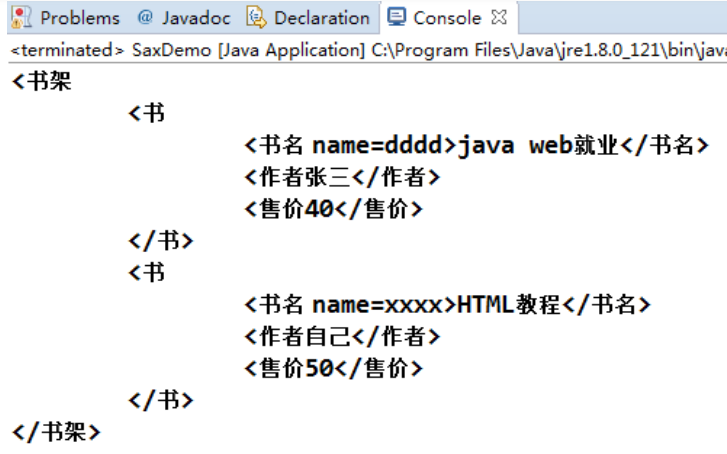
运行结果图:
更多内容:
参见:https://www.jianshu.com/p/9d6e5b066908

 浙公网安备 33010602011771号
浙公网安备 33010602011771号